- The paper presents a novel hybrid deep learning framework combining PaliGemma2 and DINOv2 for robust detection and explanation of DeepFakes.
- It leverages global context and localized feature extraction to accurately classify face-manipulated and fully synthetic images.
- The framework outperforms state-of-the-art methods in cross-dataset evaluations, offering transparent insights into image manipulations.
TruthLens: Explainable DeepFake Detection for Face Manipulated and Fully Synthetic Data
The paper "TruthLens: Explainable DeepFake Detection for Face Manipulated and Fully Synthetic Data" presents an innovative approach for tackling the issue of detecting DeepFakes through a novel framework that goes beyond traditional methods. TruthLens offers a solution to both detect and explain manipulations in images using a combination of multimodal LLMs (MLLM) and vision-only models.
Introduction
TruthLens addresses the complexities of DeepFake detection by providing not only a binary classification of real vs. fake but also generating detailed textual explanations for its predictions. The framework aims to handle both face-manipulated and fully synthetic data effectively, addressing the growing sophistication of AI-generated media content. This capability is achieved by leveraging the strengths of PaliGemma2, an MLLM that offers global context, together with DINOv2, a vision-focused model that captures localized inconsistencies.
Methodology
TruthLens's architecture is built on a hybrid model that incorporates advanced feature extraction to detect and explain DeepFakes accurately.
Overall Framework:
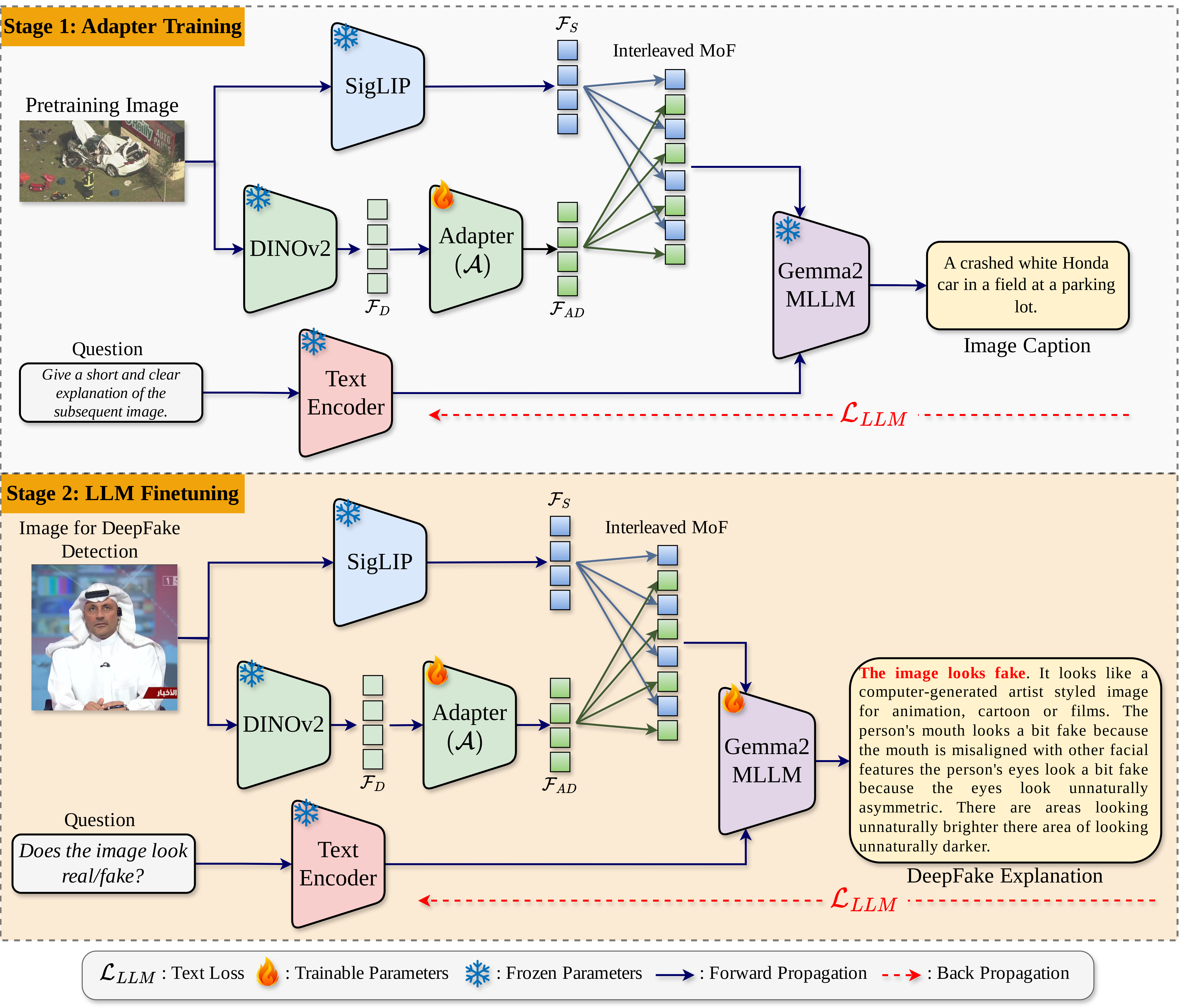
Figure 1: The overall framework for TruthLens utilizes the PaliGemma2 MLLM, combined with DINOv2 vision-only model, to achieve effective DeepFake detection through a hybrid approach.
- Global Contextual Understanding: PaliGemma2 is used to process global context for the entire image. This is crucial for understanding the overall composition and semantics of the image content, especially in fully AI-generated images.
- Localized Feature Extraction: DINOv2 enhances the model's ability to detect subtle manipulations localized to specific regions of an image, such as the facial features in face-manipulated DeepFakes.
- Feature Integration: A critical contribution of the work is the integration of features obtained from these two models to form a comprehensive detector that benefits from both global and local context.
Training Strategy
The training of TruthLens is executed in a phased manner:
- Adapter Training: The adapter, which aligns the DINOv2 features with the PaliGemma2 input requirements, is pretrained on a large-scale image-caption dataset.
- LLM Finetuning: The second phase involves finetuning the MLLM with datasets that are specifically annotated for DeepFake content, enhancing the model's ability to generalize and provide detailed explanations.
Experimental Results
TruthLens demonstrates superior performance over existing state-of-the-art (SOTA) methods in both detection accuracy and the quality of generated explanations across multiple datasets, including those specific to face manipulation and fully synthetic image generation. The model's effectiveness is particularly highlighted in cross-dataset evaluations, showcasing its robustness.
Qualitative Analysis:

Figure 2: DeepFake explanations obtained by TruthLens in cross-dataset settings on face-manipulated images from DF40, showcasing its ability to generalize and provide accurate explanations.
Implications and Future Work
The implications of this research are significant for the development of AI systems that require transparency and interpretability alongside accuracy. TruthLens's ability to extend beyond simple detection to explainability offers potential applications in areas demanding high-security measures, such as digital media verification and cybersecurity.
Future developments could involve extending this approach to video data, which presents additional challenges such as temporal consistency and real-time processing constraints. Moreover, enhancing the computational efficiency of the model will also be an important factor for deploying TruthLens in real-world applications.
Conclusion
TruthLens emerges as a comprehensive solution for DeepFake detection, addressing not only the detection challenge but also the need for explainable AI solutions. Its hybrid architecture successfully combines the strengths of different modality models, providing a robust framework that outperforms existing methods in both efficacy and interpretability. The paper sets a foundation for future research in creating more versatile and transparent AI models in the field of image and video forensics.