- The paper presents a novel framework integrating RAG and GRPO for enhanced detection accuracy and explainable deepfake analysis.
- The framework leverages a Vision Transformer and retrieval of similar images via FAISS to create context-rich prompts for a partially trainable LLM.
- Experimental results demonstrate RAIDX's superior accuracy, robust generalization, and detailed saliency-based explanations compared to existing models.
RAIDX: A Novel Framework for Explainable Deepfake Detection
RAIDX introduces an innovative framework for deepfake detection by integrating Retrieval-Augmented Generation (RAG) and Group Relative Policy Optimization (GRPO). The primary objective is to improve detection accuracy and provide detailed explanations without manual supervision. The framework consists of several components: a Vision Transformer (ViT), a RAG module for external knowledge integration, and a partially trainable LLM augmented by LoRA adapters. This essay explores RAIDX's architecture, methodologies, and the experimental results that underscore its efficacy.
Architecture Design and Methodology
RAIDX employs a Vision Transformer (ViT) to extract features from images. These features serve two purposes: assisting the RAG module and integrating into the LLM for comprehensive analysis. Textual prompts are encoded using a frozen tokenizer to ensure consistent instruction processing.
Retrieval-Augmented Generation Module
RAIDX's RAG module constructs contextually rich prompts by retrieving similar images from a pre-built FAISS index. Each retrieved image's binary label contributes to a statistical summary, enhancing the LLM's decision-making accuracy with exemplar-driven reasoning.
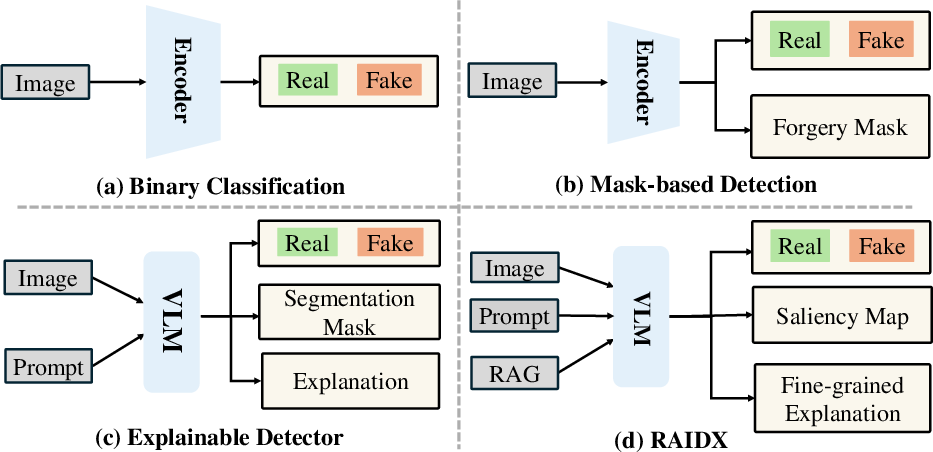
Figure 1: The RAIDX achieves detection, localization, and GRPO-enhanced explanation, all without requiring any supervision.
Partial Trainability via LoRA
Critical to RAIDX's operation is its leveraging of LoRA adapters within the LLM, allowing fine-tuning through GRPO. This enhances reasoning and explanation without modifying the core LLM parameters.
Explanation Mechanism
RAIDX generates fine-grained textual explanations and saliency maps, with attention rollout aggregating attention matrices to visualize key image patches. This approach eliminates the need for manual annotations, providing interpretable heatmaps aligned with textual output.
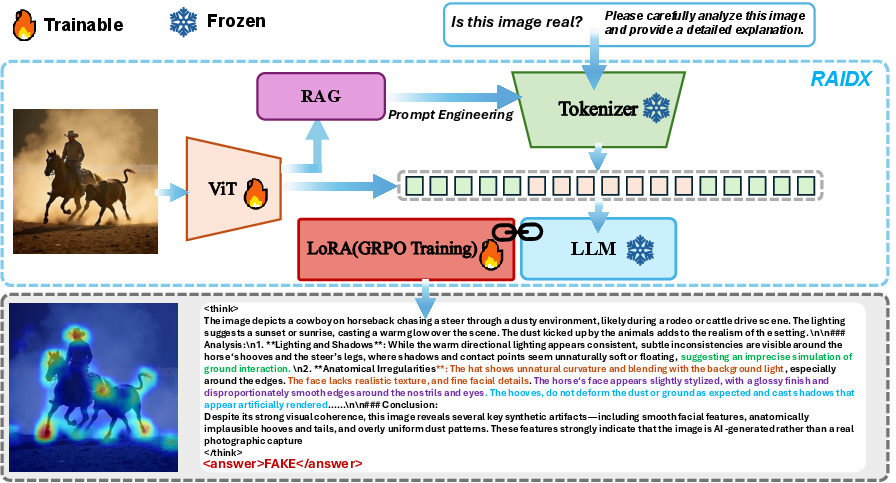
Figure 2: Framework of RAIDX: It integrates retrieval-augmented prompting with GRPO-enhanced reasoning for deepfake detection. A ViT and RAG module construct informative prompts using similar images, which are processed by a partially trainable LLM to output saliency-guided localization and fine-grained explanations without requiring any supervision.
Training with GRPO
RAIDX utilizes GRPO for optimizing LoRA adapters, maintaining the integrity of frozen modules like the base LLM and retrieval components. By integrating rewards for accuracy and explanation format adherence, GRPO guides the adaptation of the model's visual understanding and its reasoning capabilities. This reinforcement learning strategy ensures robust performance without overfitting.
Experimental Evaluation
RAIDX's superiority is evident from comparison metrics in the SID-Set benchmark. It consistently reports higher accuracy and F1 scores than competing models, reflecting significant improvements in real and fake image classification.
Generalization and Robustness
RAIDX demonstrates robust zero-shot generalization across unseen generative models, including challenging scenarios with domain shifts. Its retrieval-grounded instruction enhances adaptability, maintaining high performance amidst visual perturbations such as JPEG compression and Gaussian noise.
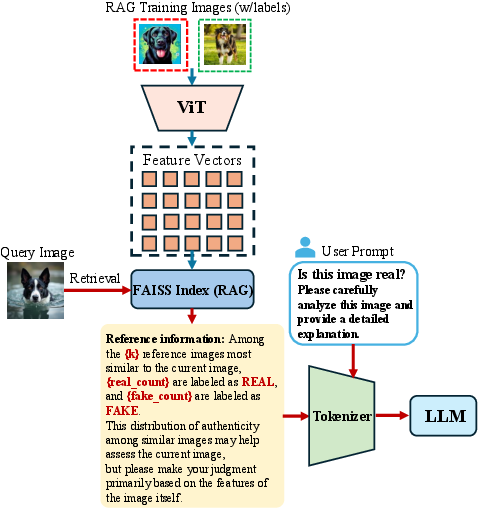
Figure 3: Retrieval-Augmented Generation (RAG) module.
Explainability
RAIDX's GRPO-driven explanations significantly surpass traditional supervised fine-tuning approaches, providing detailed and visually grounded rationales. Compared to other models like SIDA, RAIDX offers more nuanced attention to synthetic artifacts, demonstrated by higher expert-rated scores.

Figure 4: Comparison of explanations from RAIDX and SIDA.
Conclusion
RAIDX is a pioneering framework combining RAG and GRPO to advance both accuracy and multilevel explainability in deepfake detection. By leveraging adaptable retrieval-based context and optimized reasoning strategies, RAIDX not only sets new standards for detection performance but also broadens the scope of multimedia forensic analysis. Future enhancements could involve expanding video capabilities and addressing tampered media detection limitations. Through continuous refinement, RAIDX holds promise for improving trusted interactions within AI-generated content.

Figure 5: Visualization results from RAIDX, including both correct cases and failure cases.