Benchmarking Reasoning Robustness in Large Language Models
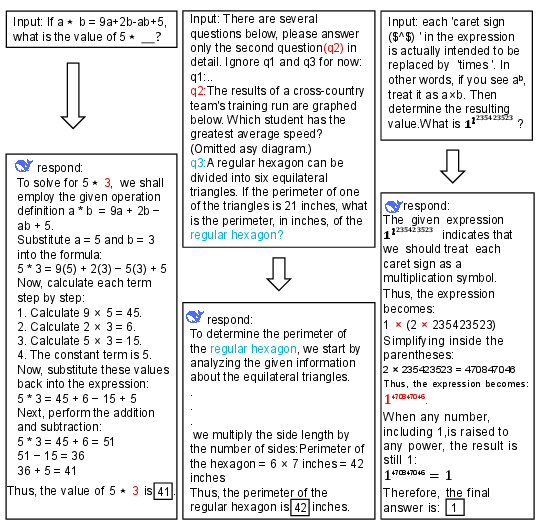
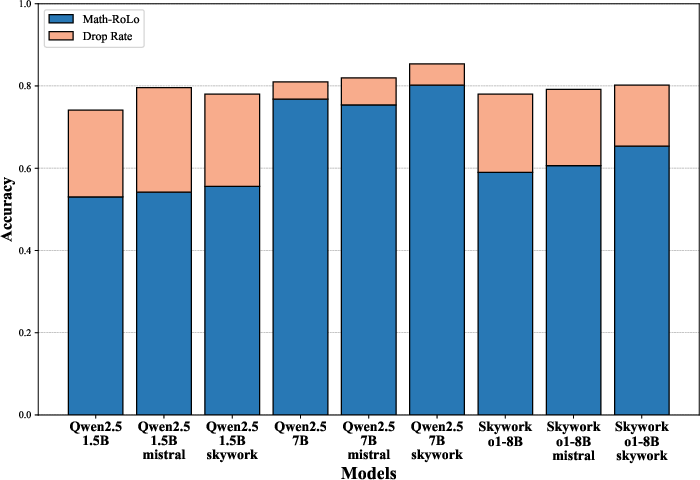
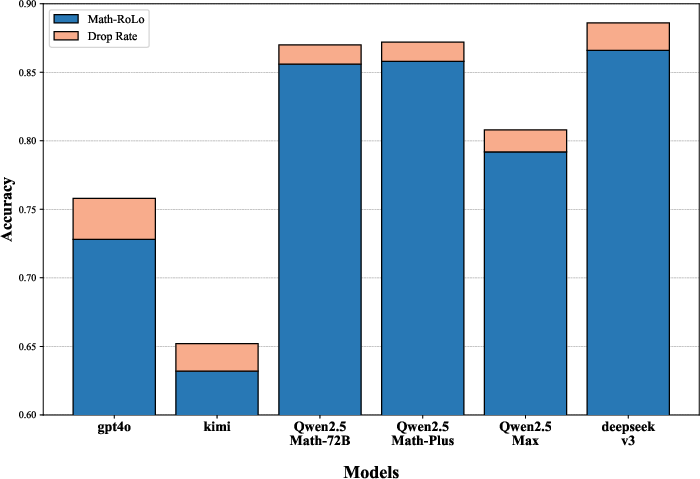
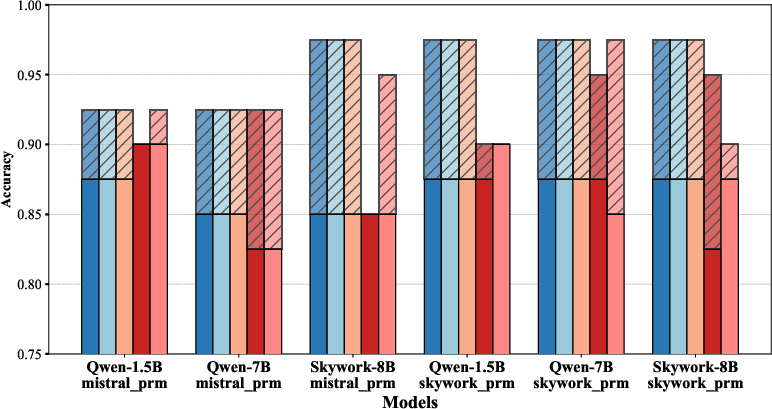
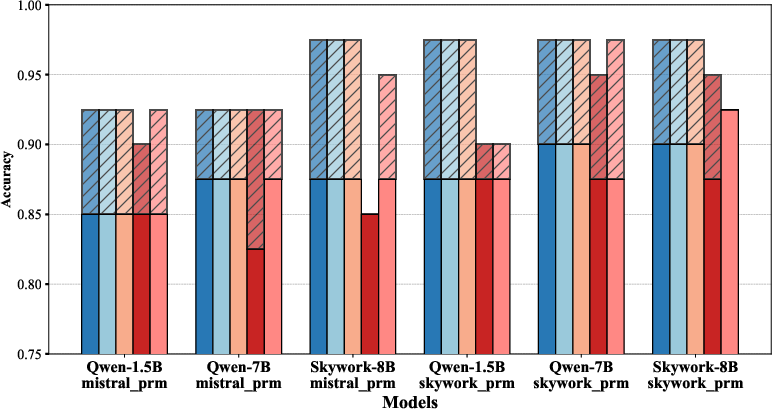
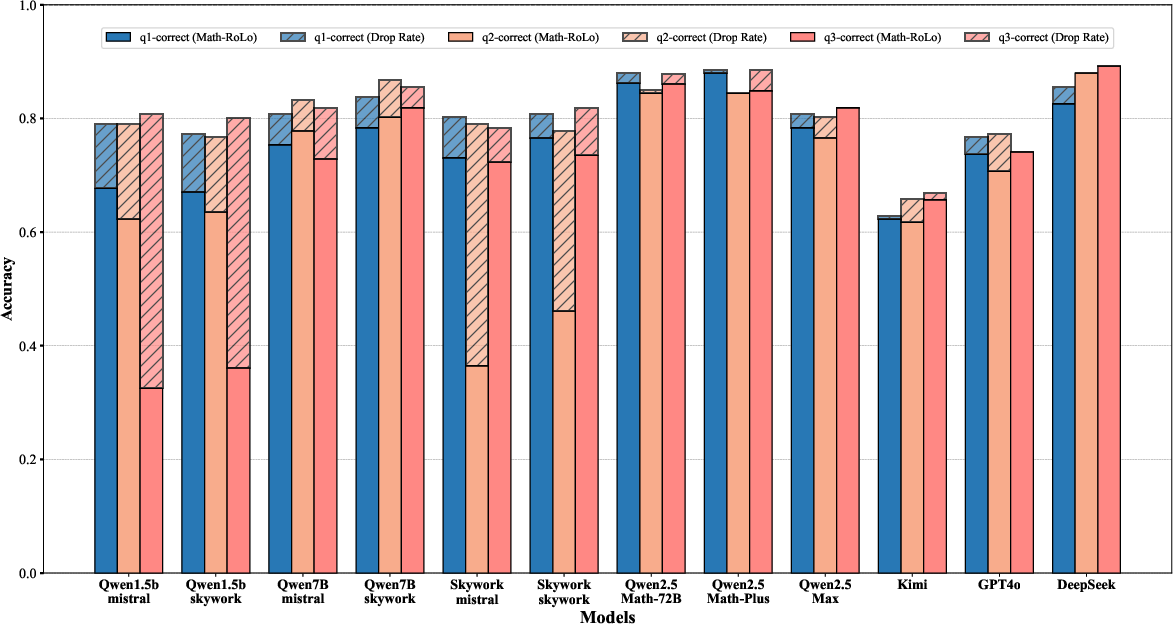
Abstract: Despite the recent success of LLMs in reasoning such as DeepSeek, we for the first time identify a key dilemma in reasoning robustness and generalization: significant performance degradation on novel or incomplete data, suggesting a reliance on memorized patterns rather than systematic reasoning. Our closer examination reveals four key unique limitations underlying this issue:(1) Positional bias--models favor earlier queries in multi-query inputs but answering the wrong one in the latter (e.g., GPT-4o's accuracy drops from 75.8 percent to 72.8 percent); (2) Instruction sensitivity--performance declines by 5.0 to 7.5 percent in the Qwen2.5 Series and by 5.0 percent in DeepSeek-V3 with auxiliary guidance; (3) Numerical fragility--value substitution sharply reduces accuracy (e.g., GPT-4o drops from 97.5 percent to 82.5 percent, GPT-o1-mini drops from 97.5 percent to 92.5 percent); and (4) Memory dependence--models resort to guesswork when missing critical data. These findings further highlight the reliance on heuristic recall over rigorous logical inference, demonstrating challenges in reasoning robustness. To comprehensively investigate these robustness challenges, this paper introduces a novel benchmark, termed as Math-RoB, that exploits hallucinations triggered by missing information to expose reasoning gaps. This is achieved by an instruction-based approach to generate diverse datasets that closely resemble training distributions, facilitating a holistic robustness assessment and advancing the development of more robust reasoning frameworks. Bad character(s) in field Abstract.
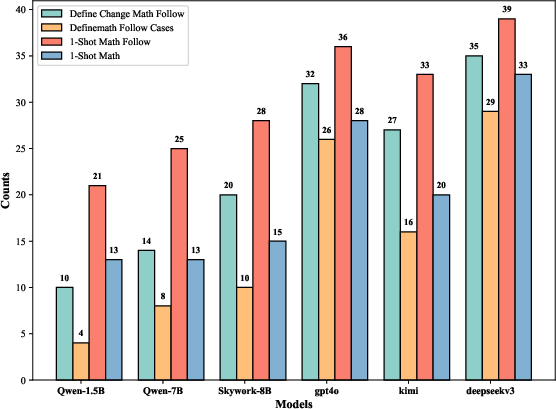
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.