A2Perf: Real-World Autonomous Agents Benchmark
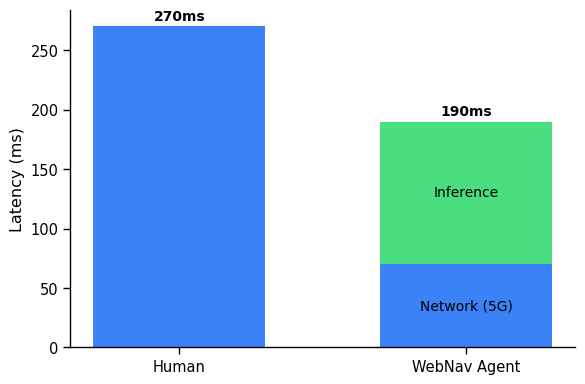
Abstract: Autonomous agents and systems cover a number of application areas, from robotics and digital assistants to combinatorial optimization, all sharing common, unresolved research challenges. It is not sufficient for agents to merely solve a given task; they must generalize to out-of-distribution tasks, perform reliably, and use hardware resources efficiently during training and inference, among other requirements. Several methods, such as reinforcement learning and imitation learning, are commonly used to tackle these problems, each with different trade-offs. However, there is a lack of benchmarking suites that define the environments, datasets, and metrics which can be used to provide a meaningful way for the community to compare progress on applying these methods to real-world problems. We introduce A2Perf--a benchmark with three environments that closely resemble real-world domains: computer chip floorplanning, web navigation, and quadruped locomotion. A2Perf provides metrics that track task performance, generalization, system resource efficiency, and reliability, which are all critical to real-world applications. Using A2Perf, we demonstrate that web navigation agents can achieve latencies comparable to human reaction times on consumer hardware, reveal reliability trade-offs between algorithms for quadruped locomotion, and quantify the energy costs of different learning approaches for computer chip-design. In addition, we propose a data cost metric to account for the cost incurred acquiring offline data for imitation learning and hybrid algorithms, which allows us to better compare these approaches. A2Perf also contains several standard baselines, enabling apples-to-apples comparisons across methods and facilitating progress in real-world autonomy. As an open-source benchmark, A2Perf is designed to remain accessible, up-to-date, and useful to the research community over the long term.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Below is a concise list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. These items highlight what is missing, uncertain, or left unexplored and are intended to be concrete and actionable for future work.
- Real-world validation: No hardware-in-the-loop or on-robot/on-device deployments are reported; results rely on simulators and mock sites, leaving the true sim-to-real transfer and deployment constraints unquantified.
- Web navigation realism: Evaluation is limited to gMiniWob mock sites; missing tests on live, heterogeneous websites with dynamic content, authentication, anti-bot defenses, accessibility (ARIA), internationalization, mobile layouts, and cross-browser variability.
- Quadruped on-board inference: No experiments on embedded or resource-constrained platforms (e.g., Jetson-class compute) to validate real-time control, thermal limits, and battery impact.
- Chip floorplanning end-to-end quality: No sign-off PPA (power, performance, area) or routed QoR validation using industrial EDA tools; reliance on proxy metrics leaves true downstream gains unverified.
- Floorplanning generalization: Limited assessment across diverse netlists and process/design nodes; unclear how well a trained agent transfers to unseen architectures without retraining.
- Data cost metric scope: Defined only for RL-generated datasets; excludes human demonstration costs (money/time), labeling/curation overhead, and ignores the energy/time to generate trajectories (rollouts) themselves.
- Data cost fairness: Online RL methods are assigned zero training sample cost, which undercounts the cost of their data collection (environment interaction) and biases comparisons with IL/offline approaches.
- Data cost aggregation: The formula averages energy over policies used to generate a dataset without weighting by each policy’s contribution (number of trajectories), potentially misestimating costs; no confidence intervals for cost estimates.
- System energy measurement fidelity: Energy/power tracked via CodeCarbon and NVML may be approximate and environment-dependent; no validation of measurement error or cross-tool agreement.
- Cross-hardware comparability: No normalization of system metrics (e.g., joules per environment step, per gradient update, per successful episode), making cross-platform comparisons difficult.
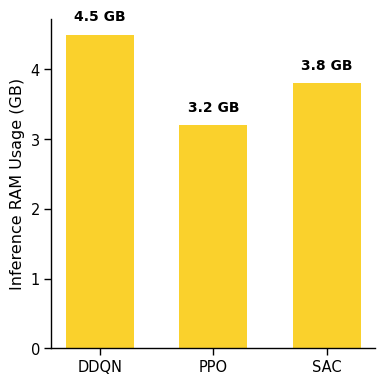
- Memory measurement methodology: Extremely high reported RAM usage (e.g., ~800+ GB) suggests measurement artifacts or multi-process aggregation errors; methodology for accurate, comparable RAM tracking is not validated.
- Latency realism in web tasks: Inference-time claims don’t account for real network latency, DNS, TLS, DOM thrashing, ad loads, or asynchronous JS; no controlled experiments injecting realistic network jitter/delays.
- Reliability metric specification: The chosen CVaR level α, detrending procedure, smoothing, and window sizes are not justified or sensitivity-tested; 10 seeds and 100 rollouts may be insufficient for stable tail estimates.
- Reliability beyond averages: No safety-focused metrics (e.g., constraint-violation rates, worst-case fall frequency for robots, unsafe click rates for web) or failure-severity-weighted risk measures.
- Generalization metric design: “Sum of mean returns across all tasks (including the training task)” conflates in-distribution and out-of-distribution performance, is sensitive to the number of tasks, and ignores reward scale differences (no normalization).
- OOD protocol: No formal train/validation/test splits or controlled OOD shift definitions (e.g., changes in dynamics, page templates, robot mass/friction, netlist families), limiting interpretability of generalization results.
- Multi-objective evaluation: No Pareto-front analysis or standardized scalarization for multi-objective domains (e.g., speed vs stability vs energy in robotics; wirelength vs congestion vs density in floorplanning).
- Sim-to-real quantification: No explicit sim-to-real gap metrics, domain randomization protocols, or robustness-to-perturbation studies to anticipate transfer success.
- Baseline coverage: Missing strong baselines including model-based RL, hierarchical RL, offline RL algorithms tailored to each domain, and modern LLM-based web agents; hyperparameter tuning protocols and fairness across methods are under-specified.
- Statistical rigor: Limited reporting (means ± std) without confidence intervals, bootstrap tests, or performance profiles; no standardized protocol for significance testing across seeds.
- Carbon accounting detail: Energy is reported but not translated into CO2e with region/time-varying grid intensity; no lifecycle accounting or embodied carbon of hardware considered.
- Composite selection guidance: No principled method to trade off data cost, system efficiency, reliability, and task performance (e.g., constrained optimization or multi-criteria decision frameworks) for practical agent selection.
- Leaderboard and governance: The planned leaderboard, submission format, result verification, and governance model are not yet operational; processes for auditability and reproducibility checks are unspecified.
- Reproducibility controls: No experiments assessing variability across OS/driver versions, Chrome/Selenium versions, or deep learning frameworks; Docker images are mentioned but not evaluated for cross-platform determinism.
- Safety scaffolding for web: No sandboxing or harm-mitigation protocols for web agents (e.g., protected environments, phishing/adversarial page defenses) and no metrics for severity-weighted safety incidents.
- Benchmark accessibility: High training resource demands limit participation; no “small-scale” or reference configurations for low-resource labs, and no analysis of scaling laws or minimal viable compute.
- Explainability: Although explainability is flagged as important for web navigation, the benchmark includes no explainability metrics, tasks, or evaluation procedures.
- Data documentation: Dataset licensing, diversity, expertise calibration, and detailed provenance are not fully specified; no standardized datasheets, no guarantees on representativeness, and no bias analysis.
- Metric boundary clarity: Potential confusion between “data cost” and “training system energy” boundaries (double counting or omission risks) is not resolved with explicit accounting rules.
- Failure mode taxonomy: No categorization or analysis of common failure modes per domain (e.g., specific gait instabilities, typical web misclicks, recurring placement pathologies) to guide targeted improvements.
Glossary
- A2Perf: An open-source benchmarking suite for evaluating autonomous agents across real-world domains with comprehensive metrics. "A2Perf provides metrics that track task performance, generalization, system resource efficiency, and reliability"
- ALE: The Arcade Learning Environment, a benchmark suite for evaluating agents on classic arcade games. "ALE \citep{bellemare2013arcade}"
- BC: Behavioral Cloning; an imitation learning method that trains policies directly from demonstrations. "BC results are obtained by training on the entire intermediate dataset."
- Cadence Innovus: An industry-grade electronic design automation tool for physical implementation and floorplanning. "Cadence Innovus"
- Circuit Training: An RL-based framework for chip floorplanning that places macros to optimize layout objectives. "Google has made Circuit Training available as an open-source framework"
- CodeCarbon: A library to estimate energy usage and emissions of ML workloads. "A2Perf uses the CodeCarbon library"
- Conditional Value at Risk (CVaR): A risk metric representing expected loss in the worst α-percent scenarios. "Conditional Value at Risk at level α."
- Congestion: A chip layout metric indicating routing bottlenecks and crowding of interconnects. "wirelength, congestion, and density"
- DAWNBench: A benchmark suite measuring end-to-end training and inference performance for deep learning. "DAWNBench \citep{Coleman2017DAWNBenchA}"
- D5RL: A benchmark focused on real-world offline RL datasets and tasks. "D5RL \citep{rafailov2024d5rl}"
- DDQN: Double Deep Q-Network; an RL algorithm that reduces overestimation bias in Q-learning. "provides more consistent initial placements compared to DDQN"
- DM Control: A suite of continuous control tasks for evaluating RL algorithms. "DM Control \citep{tassa2018deepmind}"
- DSRL: A collection of datasets for robotic and RL tasks to enable offline learning. "DSRL \cite{liu2023datasets}"
- Episodic Returns: The cumulative reward obtained over a full episode, used to measure task performance. "Episodic Returns"
- gMiniWob: A browser-based environment for web navigation tasks resembling real-world sites. "we use gMiniWob \cite{gur2021environment} to create mock websites"
- Goal-conditioned: A setting where policies are conditioned on specific goals to be achieved. "offline, goal-conditioned setting"
- Imitation Learning (IL): Methods that learn policies from expert demonstrations rather than environment interaction. "imitation learning (IL)"
- Inter-Quartile Range (IQR): A dispersion statistic measuring variability as the range between the 25th and 75th percentiles. "IQR: Inter-Quartile Range."
- JAX: A high-performance numerical computing and autodiff library often used for ML. "JAX-accelerated \citep{jax2018github} implementations"
- Jumanji: A benchmark of fast, JAX-based combinatorial optimization environments. "Jumanji \cite{bonnet2023jumanji}"
- Loon Benchmark: A real-world RL benchmark for aerial balloon navigation. "Loon Benchmark \citep{balloon_learning_env}"
- Meta-World: A meta-RL benchmark of diverse manipulation tasks for generalization studies. "Meta-World \citep{meta_world}"
- MiniWob: A suite of web-based tasks for evaluating agents on browser interactions. "MiniWob \citep{shi2017world}"
- MiniWob++: An extended version of MiniWob with more complex web tasks and interactions. "MiniWob++ \citep{liu2018reinforcement}"
- MLPerf: An industry-standard benchmark suite for ML training and inference performance. "MLPerf \citep{reddi2020mlperf}"
- NeoRL: A benchmark providing realistic environments for industrial and finance-related RL tasks. "NeoRL \citep{qin2022neorl}"
- Netlist: A representation of circuit components and connections used in chip design and floorplanning. "Ariane Netlist task"
- Non-stationarity: Environments whose dynamics or reward distributions change over time. "partial observability, non-stationarity, sparse rewards"
- OGBench: A benchmark emphasizing realistic tasks in offline, goal-conditioned RL. "OGBench \citep{park2024ogbench}"
- Offline Reinforcement Learning: RL that learns policies from fixed datasets without further environment interaction. "offline reinforcement learning \citep{levine2020offline}"
- Partial observability: The agent cannot directly observe the full environment state and must infer hidden variables. "partial observability, non-stationarity, sparse rewards"
- Policy rollouts: Executions of a trained policy in an environment to evaluate performance. "Dispersion Across Rollouts"
- PPO: Proximal Policy Optimization; an on-policy RL algorithm that stabilizes updates via clipping. "PPO exhibits superior stability during training"
- Proxy metrics: Surrogate measures used during training when true objectives are costly to evaluate. "these objectives are approximated using proxy metrics."
- Quadruped locomotion: Robotic control of four-legged systems learning dynamic gaits and movements. "quadruped locomotion"
- Reliability metrics: Statistical measures capturing variability and worst-case performance across time, runs, and rollouts. "reliability metrics \citep{chan2019measuring} prove crucial"
- SAC: Soft Actor-Critic; an off-policy RL algorithm optimizing a stochastic policy with entropy regularization. "SAC \citep{haarnoja2018soft_actor_critic} demonstrates more consistent gaits during deployment"
- Safety Gym: A benchmark focusing on safety-constrained RL environments. "Safety Gym \citep{ji2023safety_gym}"
- Selenium: A browser automation tool used to script and test web interactions. "Selenium, used in A2Perf, is a popular browser automation tool."
- Sim2Real gap: The performance discrepancy when transferring policies from simulation to the real world. "small Sim2Real gap."
- Synopsys IC Compiler: An industry-grade tool for chip physical design and implementation. "Synopsys IC Compiler"
- Tensor Processing Unit (TPU): Google’s specialized hardware accelerator for ML workloads. "History of the Tensor Processing Unit"
- Training Sample Cost: A metric quantifying the effort/energy required to generate offline datasets for training. "Training Sample Cost"
- Unitree Laikago: A commercial quadruped robot used for real-world locomotion experiments. "Unitree Laikago"
- Wall-clock time: The real elapsed time for training or inference, as opposed to simulated time. "wall-clock time"
- Wirelength: Total length of interconnect wires in a chip layout, a key optimization objective. "wirelength, congestion, and density"
Collections
Sign up for free to add this paper to one or more collections.

