- The paper introduces LoTRA, a method leveraging Tucker decomposition to adapt KANs efficiently by reducing parameters while maintaining model performance.
- It demonstrates that low tensor-rank structures enable faster convergence and improved efficiency in physics-informed machine learning tasks, especially in solving PDEs.
- Experimental findings reveal that slim KANs with LoTRA achieve significant compression ratios and enhanced generalization for function approximation and image classification.
Low Tensor-Rank Adaptation of Kolmogorov--Arnold Networks
Introduction
"Low Tensor-Rank Adaptation of Kolmogorov--Arnold Networks" presents a novel approach for fine-tuning Kolmogorov--Arnold Networks (KANs) by leveraging low tensor-rank adaptation (LoTRA). Inspired by Tucker decomposition and the observed low tensor-rank structures in KAN parameter updates, LoTRA aims to enhance the efficiency of training and reduce storage requirements while maintaining model expressiveness.
KANs have emerged as effective alternatives to traditional MLPs in diverse scientific domains, especially in physics-informed machine learning. They are based on the Kolmogorov--Arnold representation theorem, allowing representation of multivariate continuous functions through sums of univariate functions. The architecture of KANs surpasses traditional limitations of KART-based networks by offering deeper layers and arbitrary widths, enabling improved function approximation capabilities.
Despite their inherent advantages, transferring learning for KANs remains largely unexplored. This paper addresses this gap by introducing LoTRA to fine-tune KANs efficiently, demonstrating robust performance in solving partial differential equations (PDEs) and reducing model size through Slim KANs.
Low Tensor-Rank Adaptation
LoTRA leverages Tucker decomposition, a powerful technique for compressing third-order tensors into smaller core tensors augmented with transformation matrices. The method adapts KAN parameters through efficient updates, reducing computational load and storage requirements. The adaptation formula in LoTRA is inspired by evidence on low tensor-rank structures within KANs, providing for each KAN parameter tensor:
Aft=Apt+G×1U(1)×2U(2)×3U(3)
Applying LoTRA in physics-informed machine learning, the approach yields efficient training and storage across a class of PDEs with different parameters. By retaining shared information across tasks, LoTRA achieves faster convergence during fine-tuning, eliminating redundant learning.
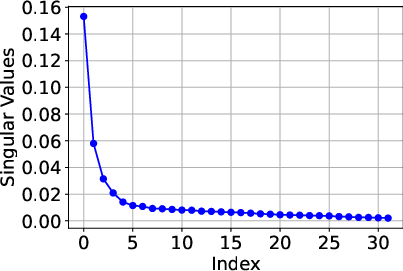
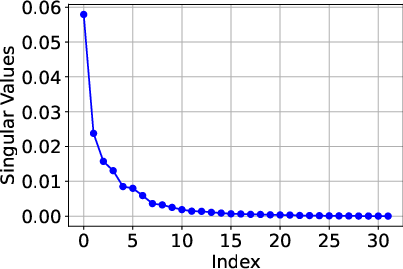
Figure 1: Singular values for the pre-trained model parameters and fine-tuned updates, demonstrating the low Tucker rank structure.
Theoretical Insights
The paper provides a theoretical analysis of LoTRA's expressiveness and efficient training capabilities. Based on Tucker decomposition, the fine-tuned model’s ability to approximate target functions depends on the magnitude of omitted singular values in error tensors.
The theoretical framework proposes an optimal learning rate selection strategy for LoTRA, ensuring efficient gradient descent training. Using identical learning rate scales for all components leads to inefficiency, necessitating differentiated rates based on tensor ranks and component attributes.
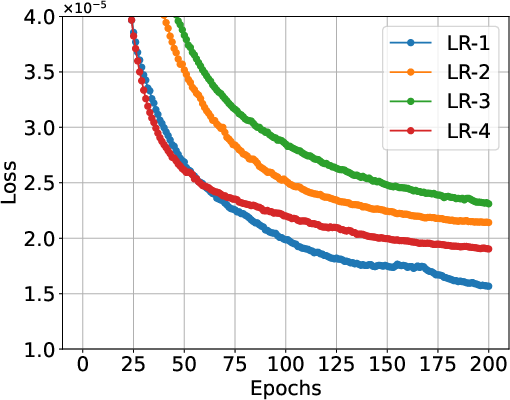
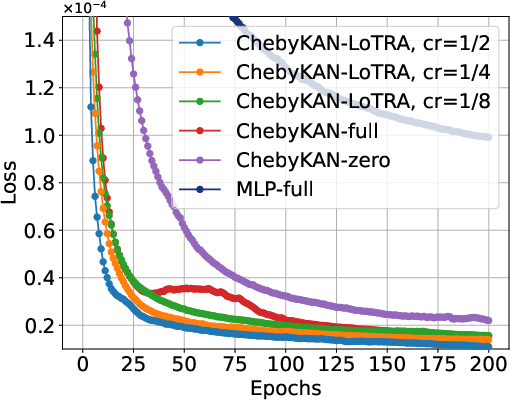
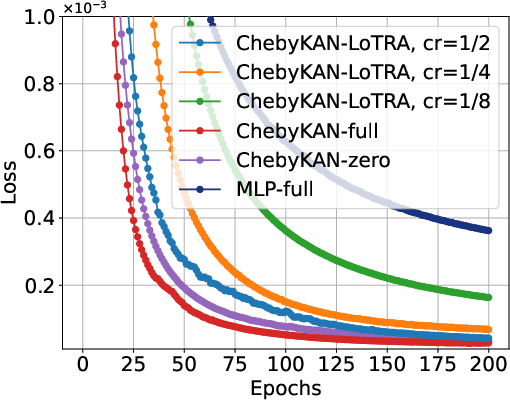
Figure 2: Fine-tuning trajectories of Chebyshev KANs using LoTRA under four strategies of learning rate selection (denoted as LR-1" toLR-4") for solving elliptic equations.
Applications
KANs excel in physics-informed machine learning, particularly in approximating PDE solutions. With LoTRA, KANs can efficiently handle variations in PDEs with different physical parameters by retaining shared patterns and adapting to task-specific information using low tensor-rank structures.
Experiments illustrate that KANs with LoTRA consistently match or surpass the performance of full fine-tuning models, demonstrating faster convergence and effective storage reduction through compression ratios.
Slim KANs
Slim KANs harness LoTRA’s low tensor-rank properties to achieve parameter-efficient models without requiring a pre-trained basis. The approach retains model expressiveness and mitigates overfitting through built-in regularization, yielding competitive performance in function representation and image classification tasks.
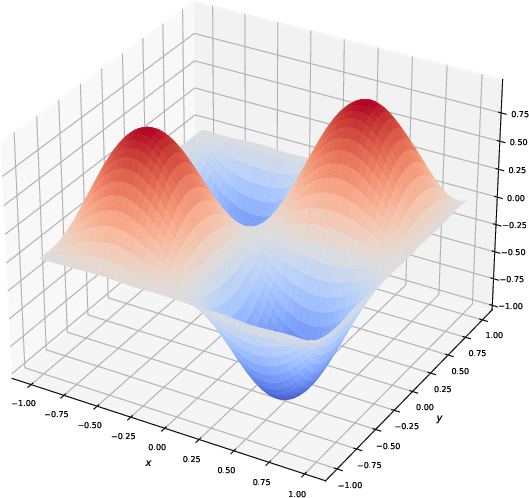
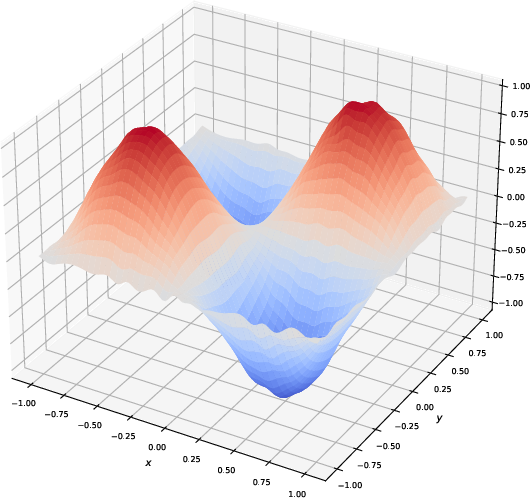
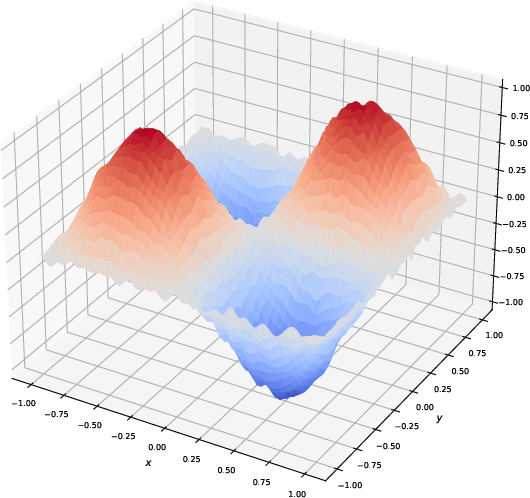
Figure 3: Visualization of the generated function by slim KAN models with different compression ratios for representing a trigonometric function. The figures illustrate that models with a larger compression ratio tend to overfit the noise, producing less smooth results. In contrast, models with smaller compression ratios generate smoother functions, reflecting better generalization.
Conclusion
LoTRA offers a transformative approach to fine-tuning KANs, enabling efficient training and significant parameter reduction while maintaining high performances across PDE solving tasks. The theoretical insights, coupled with robust experimental validations, position LoTRA as a promising method for scalable KAN applications in physics-informed machine learning and beyond. Future work may extend LoTRA’s theoretical foundations and explore integration into complex deep learning architectures for broader applications.