- The paper introduces a novel DMFT that models deep linear network training dynamics from random initialization, accurately predicting loss trajectories.
- It compares NTK and mean-field parameterizations, showing that optimal learning rates scale with width in NTK but remain invariant in μP networks.
- The study extends its framework to residual networks, demonstrating practical implications for hyperparameter transfer and efficient network scaling.
Deep Linear Network Training Dynamics from Random Initialization: Data, Width, Depth, and Hyperparameter Transfer
Introduction
The paper presents a detailed theoretical analysis of gradient descent dynamics in deep linear networks trained from random initialization, emphasizing the parameterization's role on the learning dynamics. The study elucidates the "wider is better" effect observed in mean-field or maximum-update parameterized networks and highlights the failure of hyperparameter transfer in Neural Tangent Kernel (NTK) parameterization as opposed to μTransfer in mean-field parameterization.
Theoretical Modeling
The theoretical framework developed in the study leverages a novel dynamical mean field theory (DMFT) tailored for deep linear networks. This approach predicts typical case loss dynamics and representation trajectories by establishing a closed set of equations centered on correlation and response functions for each hidden layer. Specifically, it captures training dynamics across different parameterizations: NTK, where optimal learning rates increase with model width, and mean-field (MFP or μP), where learning rates are preserved across widths.
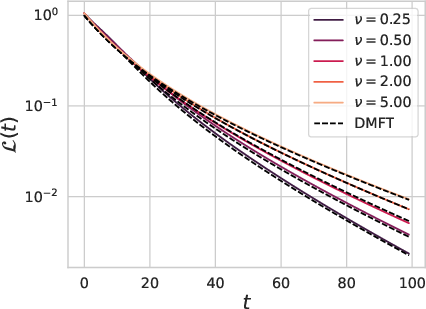
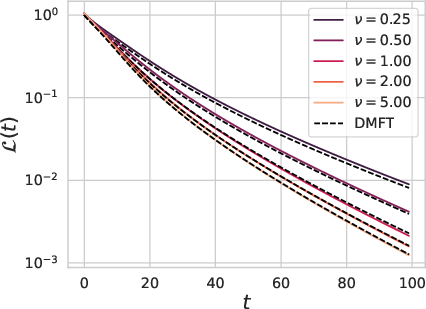
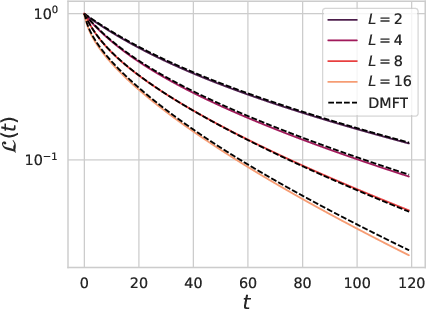
Figure 1: Our theory captures the role of width, depth and dataset size on the test loss L(t) and train loss L^(t) dynamics.
Dynamics and Generalization
The DMFT equations derived capture both train and test loss dynamics, delineating the typical learning curves associated with varying data, model width, and parameterizations. Crucially, the model illustrates how datasets and model widths can alter the dynamics due to finite width effects and batchsize configurations in online SGD scenarios.
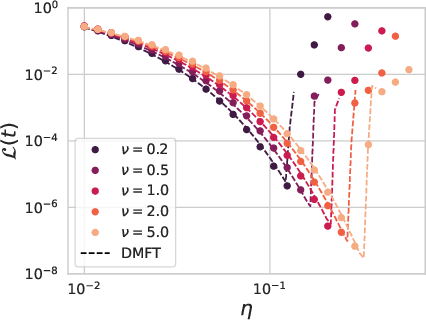
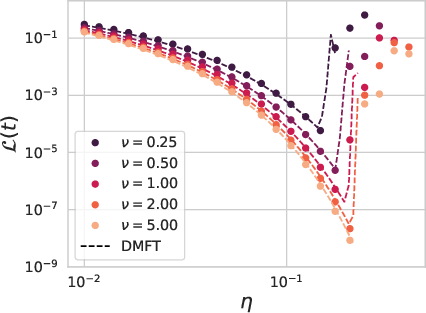
Figure 2: The theory can capture the failure of hyperparameter transfer in NTK parameterization and the success of hyperparameter transfer in μP networks.
Hyperparameter Transfer and Learning Rate Dynamics
Among the core findings is the successful prediction of hyperparameter transfer dynamics, confirming experimental observations that optimal learning rates remain consistent across model scales in μP networks but shift in NTK parameterization. This provides significant implications for understanding and optimizing large neural networks.
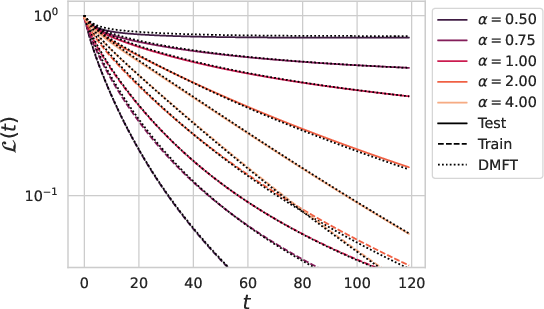
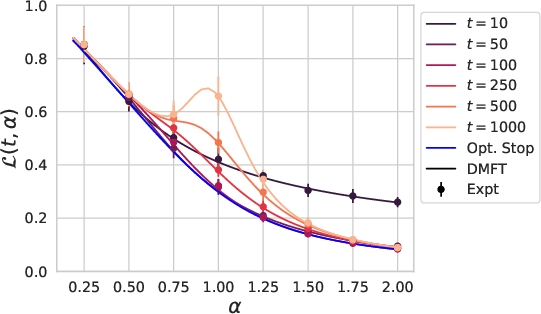
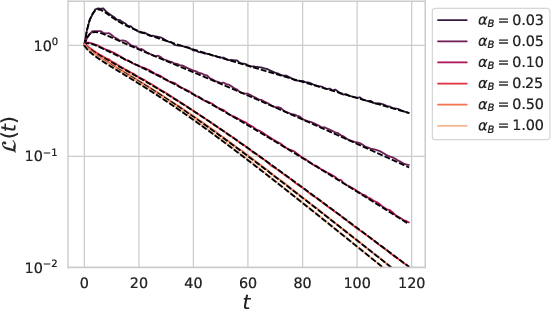
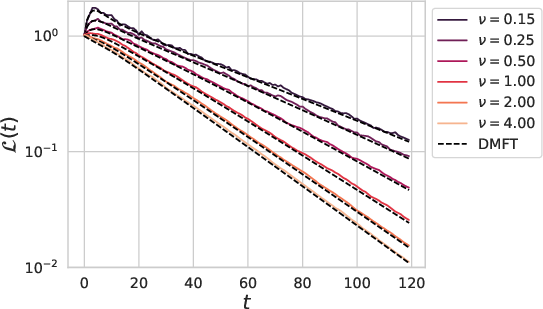
Figure 3: Train and test losses of a depth L=4 linear network versus dataset size P=αD compared to online SGD with batch size B=αBD.
Residual Network Dynamics
The paper extends its theoretical framework to residual networks, presenting a novel DMFT that handles cross-layer correlation and response functions. By scaling the residual branch properly, the study supports the existence of a well-defined infinite depth limit, consistent with the large depth-μP scaling established by previous works.
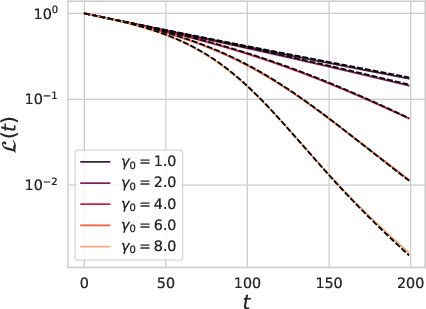
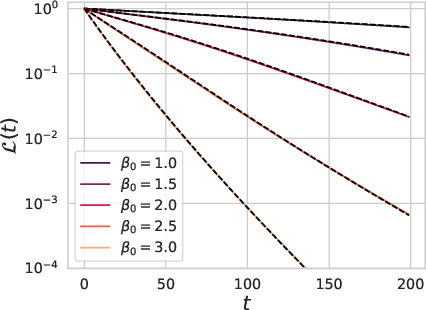
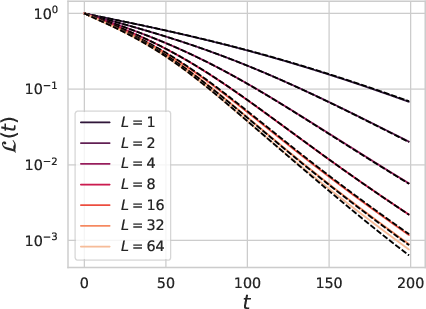
Figure 4: The training dynamics of large depth residual networks with random initialization.
Infinite Depth Limits
In the infinite depth limit under appropriate parameterization, the paper presents a set of stochastic differential equations (SDE) that govern the residual network dynamics. It demonstrates that feature learning can speed up convergence in power law hard task regimes, aligning with recent empirical findings.
Conclusion
This work advances the theoretical understanding of parameterized networks' dynamic scaling, training dynamics, and hyperparameter transfer. The DMFT framework developed is a critical tool, offering significant insights and guiding principles for efficiently scaling network training across various parameterizations.
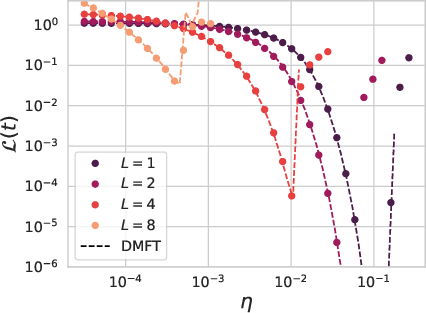
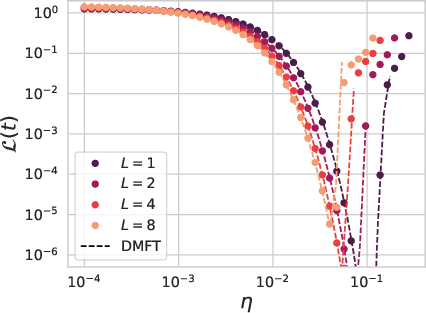
Figure 5: Learning rate transfer fails for vanilla ResNets but succeeds for scaled resnets, consistent with theory (dashed lines).
Implications
The findings have substantial implications for both theoretical and practical aspects of deep learning. They inform the design of more robust parameterization strategies and elucidate hyperparameter tuning, which can ultimately lead to more efficient training regimens across various architectures. Future research can build upon this framework to explore more complex non-linear networks and deeper architectures.
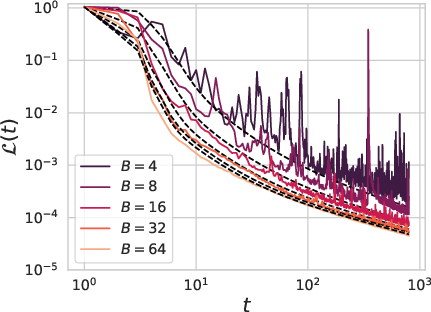
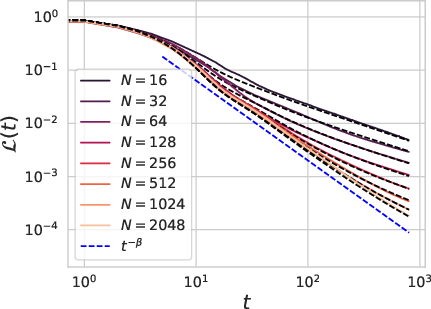
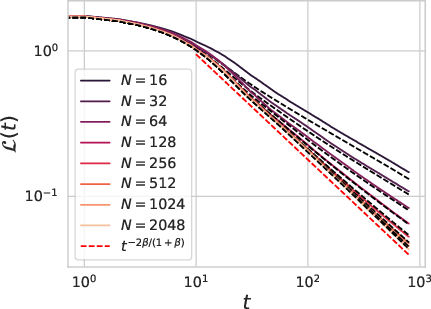
Figure 6: A dimension free mean field description of the dynamics captures SGD effects and finite width N effects for power law data covariates.


