- The paper provides an extensive review of multimodal recommender systems, categorizing techniques into feature interaction, enhancement, and model optimization.
- It details methodologies including graph neural networks, attention mechanisms, and contrastive learning to handle data sparsity and cold start challenges.
- The survey offers practical insights and future directions, emphasizing real-world applications in multimedia services and calls for more comprehensive datasets.
Multimodal Recommender Systems: A Survey
Introduction
The paper "Multimodal Recommender Systems: A Survey" (2302.03883) provides an in-depth exploration of multimodal recommender systems (MRS), which are increasingly significant due to the rise of multimedia services. With the advent of diverse online platforms offering rich multimedia content, understanding and leveraging multimodal features—including images, audio, and text—has become essential to improve user experience and recommendation accuracy. Multimodal features not only enrich the information available but also help mitigate challenges like data sparsity and the cold start problem in recommendation systems. This survey categorizes existing models based on three core technical aspects: Feature Interaction, Feature Enhancement, and Model Optimization.
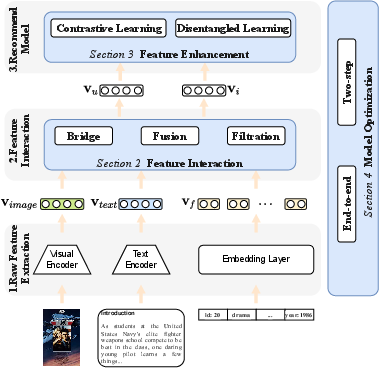
Figure 1: The general procedures of multimodal recommendation.
Procedures of Multimodal Recommender Systems
The MRS framework is fundamentally structured into three procedures: Raw Feature Extracting, Feature Interaction, and Recommendation. Initially, various modalities of information such as text, images, and audio are extracted through specialized encoders. This is followed by the creation of a shared semantic space to enable interaction amongst different modality features. The final step involves leveraging enhanced user and item representations for accurate recommendations.
A notable challenge arises in effectively fusing multimodal data from disparate semantic spaces. This requires sophisticated techniques to align these diverse data streams for optimal user preference modeling. Consequently, the survey emphasizes three primary categories based on challenges: Feature Interaction, Feature Enhancement, and Model Optimization.
Feature Interaction
Feature Interaction concerns the integration of modality features to form comprehensive user and item representations. It involves advanced techniques such as Graph Neural Networks (GNNs) and attention mechanisms, which provide solutions by bridging, fusing, and filtering multimodal information.
Types of Feature Interaction
- Bridge: This technique primarily involves constructing user-item and item-item graphs, which are crucial for capturing complex interaction patterns. Methods like MMGCN and DualGNN use these graphs to model user preferences while coping with modality diversity.
- Fusion: This process entails combining modality features into a coherent representation for recommendation. Techniques range from coarse to fine-grained attention mechanisms, allowing for different levels of information aggregation and retention.
- Filtration: Filtering focuses on eliminating noisy data within the multimodal feature set. Techniques such as GRCN and PMGCRN dynamically prune irrelevant or incorrect interactions, improving recommendation quality by retaining only pertinent information.
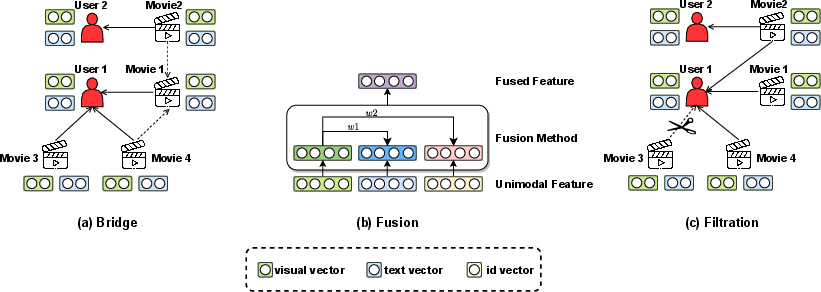
Figure 2: The illustration to three types of feature interaction.
Multimodal Feature Enhancement
Feature Enhancement strategies such as Disentangled Representation Learning (DRL) and Contrastive Learning (CL) are employed to improve the richness and accuracy of modality features. DRL methods disentangle user and item features, enabling a clearer understanding of different modality contributions. Meanwhile, CL approaches enhance feature representations by contrasting similarities between different modalities, often leveraging data augmentations to create robust feature representations.
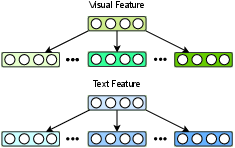
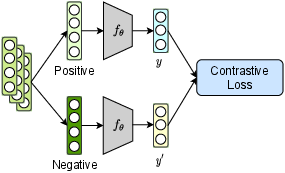
Figure 3: Disentangled Representation Learning
Model Optimization
Model Optimization deals with the computational efficiency and effectiveness of training models in MRS. There are two main approaches:
- End-to-End Training: This approach updates the full model architecture simultaneously, necessitating significant computational power but providing fine-tuned integration of multimodal features.
- Two-step Training: In contrast, this method involves pre-training stages for the modality encoders, followed by task-specific optimization. It allows for more focused training on specific tasks but requires handling separately trained components.


Figure 4: End-to-end Training
Applications and Resources
MRS have broad applications across various domains such as video streaming, e-commerce, and social media, where different modalities influence user interaction. The paper details specific datasets for these use cases, facilitating further research and development. It also highlights available open-source frameworks like MMRec and Cornac, which offer ready-to-use architectures for implementing MRS models.
Conclusion
The survey concludes by identifying key challenges and future directions for MRS research. These include the development of universal models that can efficiently integrate multimodal data, improving model interpretability, and enhancing computational efficiency to handle large-scale systems. Alongside, there is a call for more comprehensive and diverse datasets to extend the applicability and robustness of multimodal recommendation systems. Through its detailed analysis, this paper serves as a guide for researchers aiming to innovate and advance the field of multimodal recommender systems.

