- The paper demonstrates that multi-agent dialogues significantly enhance the originality and feasibility of research ideas using a structured ideation–critique–revision framework.
- The study shows that incorporating diverse agent roles and optimal parallelism leads to improved feedback diversity and idea quality, with specialized critic roles achieving a notable win rate.
- Methodologically, the paper employs controlled experiments across seven research topics and utilizes LLM-based scoring to evaluate innovation and practical relevance.
Exploring Design of Multi-Agent LLM Dialogues for Research Ideation
The paper "Exploring Design of Multi-Agent LLM Dialogues for Research Ideation" investigates the optimal structuring of multi-agent dialogues among LLMs to enhance the generation of novel and feasible research ideas. By analyzing configurations involving different roles, numbers of agents, and dialogue depths, the study provides insights into improving the overall quality of ideas generated through such systems.
Introduction and Motivation
LLMs have shown significant capabilities in generating creative research ideas, yet existing approaches often rely on single-shot prompting, missing the collaborative benefits of multi-agent systems. Recent works have demonstrated the potential of interactions among LLMs to enhance accuracy and strategic planning through debate, self-critique, and role-playing. However, the optimal design for multi-agent interactions—particularly for open-ended tasks such as research ideation—remains unexplored.
Through a controlled study, this paper systematically analyzes how agent diversity, parallelism, and interaction depth contribute to the production of innovative and practical scientific ideas. The proposed framework models an ideation–critique–revision loop, aimed at iterative improvement in multi-agent LLM systems.
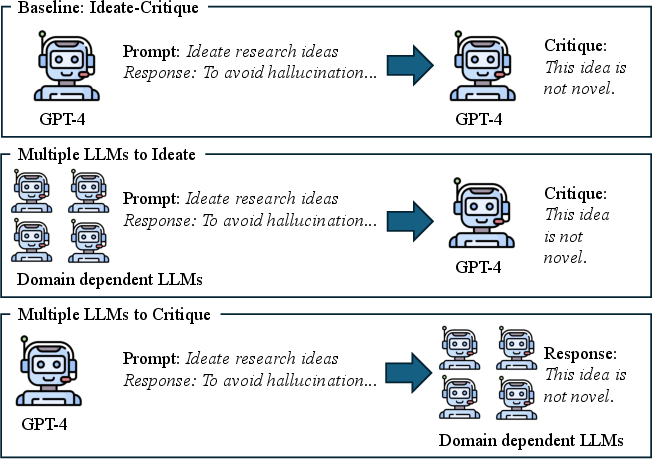
Figure 1: Examples of LLMs' discussion-based ideation. We compare several combinations of the number of LLMs, their assigned personas (e.g., domain-generalist or domain-expert), and the number of times that the ideation–critique–revision cycle is repeated.
Methodology
Overall Framework
The study builds upon the ideation framework by [si2025can], using a seed query to generate research ideas through a multi-agent LLM system. The structured ideation–critique–revision framework involves:
- Initial Ideation: One or more LLMs generate ideas based on seed topics.
- Critique: Another set of LLMs critiques the initial ideas.
- Revision: The ideas are revised, considering the critiques.
Each configuration of agent roles, numbers, and depth was evaluated across seven research topics, using diversity metrics and an LLM-as-a-judge ranking based on preferences derived from a GPT-4 tournament.
Experimental Configurations
The study compares multiple configurations to assess the impact of different design aspects on the generation quality:
- Agent Diversity: Examines the incorporation of different domain-specific personas for enhanced ideation, including roles such as "Physics-AI" and "Psychology-AI".
- Agent Parallelism: Involves varying the number of simultaneous critique agents to determine effects on feedback diversity and quality.
- Agent Interaction Depth: Changes in the number of critique–revision iterations to understand their impact on idea refinement.
These configurations were evaluated using a robust pipeline to ensure comparability, incorporating semantic deduplication and LLM-driven scoring for originality, feasibility, and clarity of generated ideas.
Results and Analysis
The results demonstrate that each design parameter—diversity, parallelism, and interaction depth—significantly influences the outputs in terms of diversity and quality. Key findings are:
- Agent Diversity: Enabling diverse critic personas leads to improved quality, while proposer/reviser diversity enhances idea diversity. Specialized critic roles achieved a notable win rate of 0.55 against the baseline in quality measures.
- Agent Parallelism: Increased identical critics raised idea diversity, peaking with three simultaneous critics, indicating an optimum balance for incorporating diverse feedback without introducing excessive noise.
- Agent Interaction Depth: Iterative refinement through multiple critique–revision cycles enhanced both idea diversity and quality, with three iterations identified as the most beneficial.
These findings suggest that maximizing complementarity among agents through role diversity and managing feedback breadth and depth can enhance both the novelty and feasibility of research ideas.
Conclusion
This study offers critical insights into designing multi-agent LLM systems for scientific ideation. By systematically exploring and evaluating various dialogue configurations, it lays down practical guidelines to optimize multi-agent LLM-based ideation. Future research may address limitations such as the reliance on automatic evaluation protocols and the exploration of richer multi-agent systems rooted in formal theories of creativity and collaboration.
Implications and Future Directions
The implications of this research are both practical and theoretical. Practically, the insights gained from these controlled experiments can inform the development of more effective tools for scientific ideation, potentially enhancing productivity in research activities. Theoretically, these findings contribute to the understanding of how agent diversity, parallelism, and interaction depth can be harnessed to improve the novel and practical output of AI systems.
Future research could explore the integration of more diverse and sophisticated interaction models, possibly grounded in existing studies from cognitive science and collective intelligence literature, to further refine multi-agent dialogues for creative generation tasks. Additionally, incorporating a human-in-the-loop for rich, qualitative evaluations of idea feasibility and creativity could provide deeper insights into the interplay between human and machine creativity.