- The paper introduces FastAttention, which extends FlashAttention2 to NPUs and low-resource GPUs for efficient large language model inference.
- It employs a two-level tiling strategy, tiling-AllReduce, and CPU-GPU collaboration to enhance memory bandwidth utilization and minimize latency.
- Empirical results demonstrate up to 10.7× speedup on NPUs and significant FLOPS improvements on Volta GPUs, underscoring its scalability.
FastAttention Integration for NPUs and Low-resource GPUs
The paper "FastAttention: Extend FlashAttention2 to NPUs and Low-resource GPUs" presents an advancement in the FlashAttention series by introducing FastAttention, which is designed to optimize LLM inference on Neural Processing Units (NPUs) and low-resource Graphics Processing Units (GPUs). It addresses critical challenges such as adaptation to non-CUDA architectures, inefficiencies in distributed inference, and memory constraints during ultra-long sequence processing.
Methodology Overview
The development of FastAttention is centered on making the FlashAttention series compatible with Ascend NPUs and Volta-based GPUs while implementing strategies to reduce computation and communication overhead.
NPU Implementation
The introduction of a two-level tiling strategy significantly enhances runtime efficiency by reducing synchronization overhead during attention calculations:
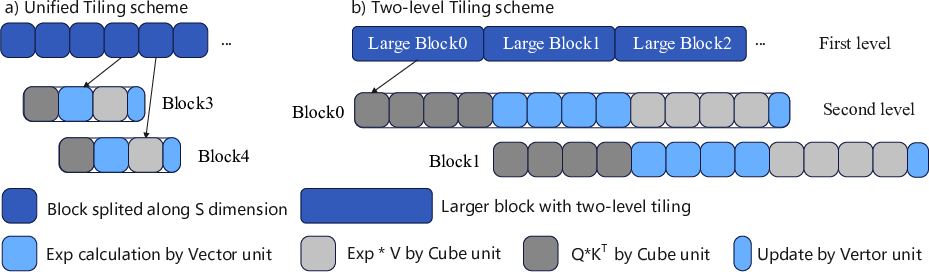
Figure 1: a) The unified tiling scheme with the fine-grained pipeline of Vector and Cube units; b) The two-level tiling strategy that employs the larger block size in the first level and maintains the smaller block size in the second level.
This approach maximizes memory bandwidth utilization and improves the parallelism between Cube and Vector units by adopting a pipelined model.
Multi-NPU Strategy
In multi-NPU scenarios, FastAttention leverages a tiling-AllReduce strategy to further optimize operational latency by overlapping computation and data transfer phases:

Figure 2: The pipeline of the FastAttention with different block sizes.
This results in a reduction of communication costs ordinarily incurred during distributed inference processes.
GPU Adaptation
For Volta-based GPUs, FastAttention modifies the operand data layout in shared memory using CuTe library constructs and ensures compatibility with the m8n8k4 instruction set of Volta GPUs:
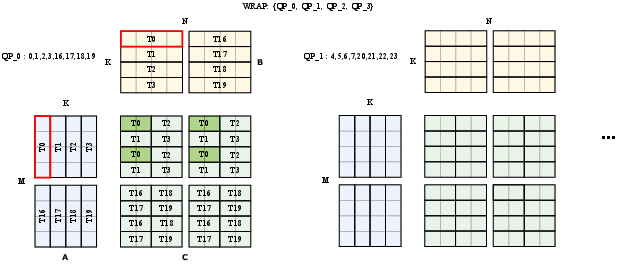
Figure 3: An example of MMA instruction m8n8k4 for Volta.
This redesign allows the efficient implementation of matrix multiplications necessary for attention mechanisms.
CPU-GPU Collaborative Strategy
To extend inference capabilities beyond memory-bound constraints, FastAttention incorporates a CPU-GPU cooperative strategy, enhancing computational reach for ultra-long sequence support:
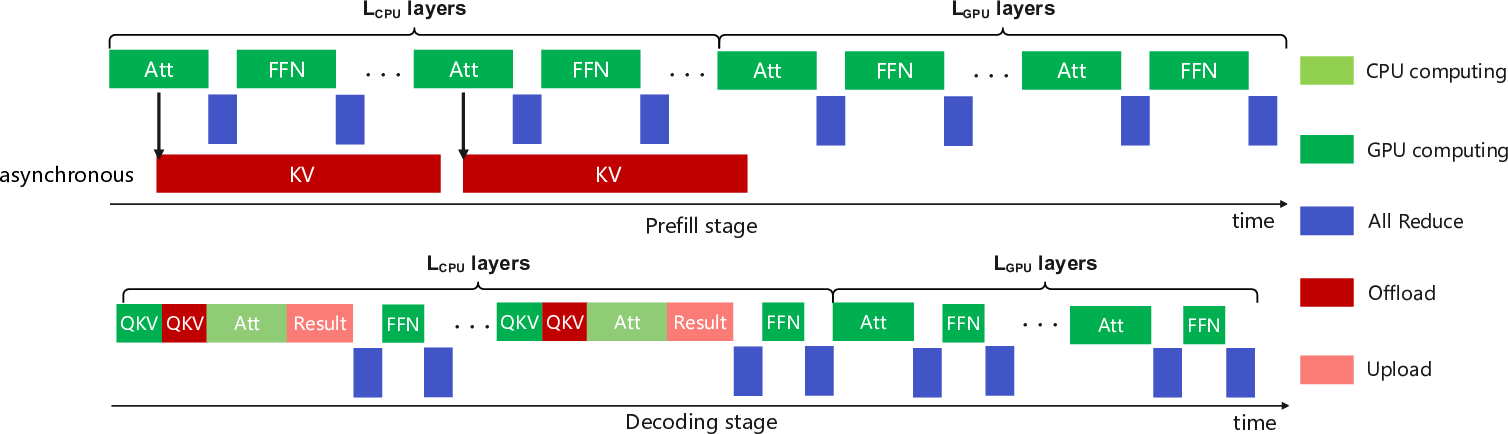
Figure 4: The method design of the fine-grained CPU-GPU collaborative strategy.
Memory is dynamically managed across CPUs and GPUs, facilitating extensive input data processing which would otherwise be restricted by GPU memory limits.
The empirical results demonstrate superior efficacy and scalability of FastAttention in various operational contexts:
- Single NPU Efficiency: FastAttention achieves up to a 10.7× speedup over standard implementations and a throughput boost of 5.16× in real-time processing scenarios.
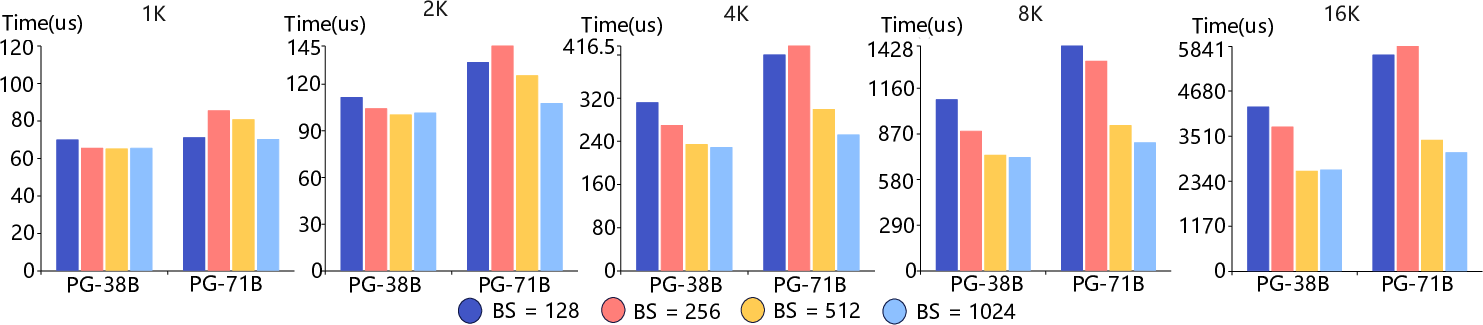
Figure 5: The latency comparison of FastAttention with different block sizes on an Ascend 910B across sequence lengths from 1K to 16K.
- Multi-NPU Scalability: Demonstrating up to 1.40× speedup for large-scale LLMs, it minimizes latency even as sequence lengths extend to tens of thousands.
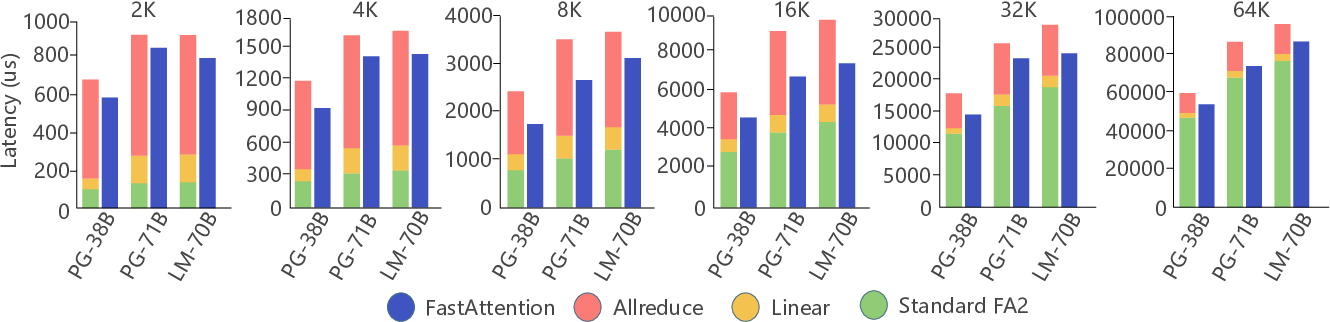
Figure 6: The performance of FastAttention on eight Ascend 910B NPUs with sequence length from 2K to 32K.
- Low-resource GPU Advantage: On V100 GPUs, FastAttention provides up to 1.43× improved FLOPS execution, highlighting its proficiency in harnessing Volta architecture.
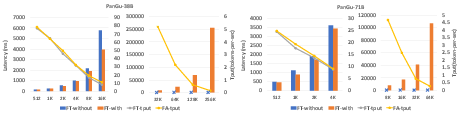
Figure 7: Latency and throughput comparison of FasterTransformer with and without FastAttention for different models and sequence lengths on eight V100 GPUs.
These results underscore FastAttention's capacity to effectively transition resources in scalable AI deployments.
Conclusion
FastAttention represents an integral stride in adapting attention mechanisms for less conventional hardware architectures like NPUs and low-resource GPUs. The methodologies and strategies presented not only bridge the compatibility gap with older architectures but also optimize computational workflows to accommodate increasing data and inference throughput demands. This advancement paves the way for future endeavors in extending efficient attention-based computing across diverse hardware setups, ensuring robust and scalable AI implementations.