- The paper presents VLM-TAMP, a hierarchical framework that leverages vision-language models to generate semantically rich subgoals for task and motion planning.
- The paper outlines an iterative reprompting strategy that improves planning robustness, increasing success rates by 47–55% on complex robotic tasks.
- The paper demonstrates that subgoal prediction significantly outperforms direct action sequencing, reducing planning complexity and achieving up to 100% success in long-horizon tasks.
Guiding Long-Horizon Task and Motion Planning with Vision LLMs
Introduction
This paper introduces VLM-TAMP, a hierarchical planning framework that integrates Vision-LLMs (VLMs) with Task and Motion Planning (TAMP) to address long-horizon robot manipulation tasks. The motivation stems from the complementary strengths and weaknesses of VLMs and TAMP: VLMs excel at commonsense reasoning and high-level plan generation but lack geometric and kinematic feasibility awareness, while TAMP is capable of generating feasible, low-level plans but struggles with semantic scalability and computational complexity in large, open-world domains. VLM-TAMP leverages VLMs to generate semantically meaningful, horizon-reducing subgoals, which are then refined and executed by a TAMP planner, with iterative reprompting to handle failures.

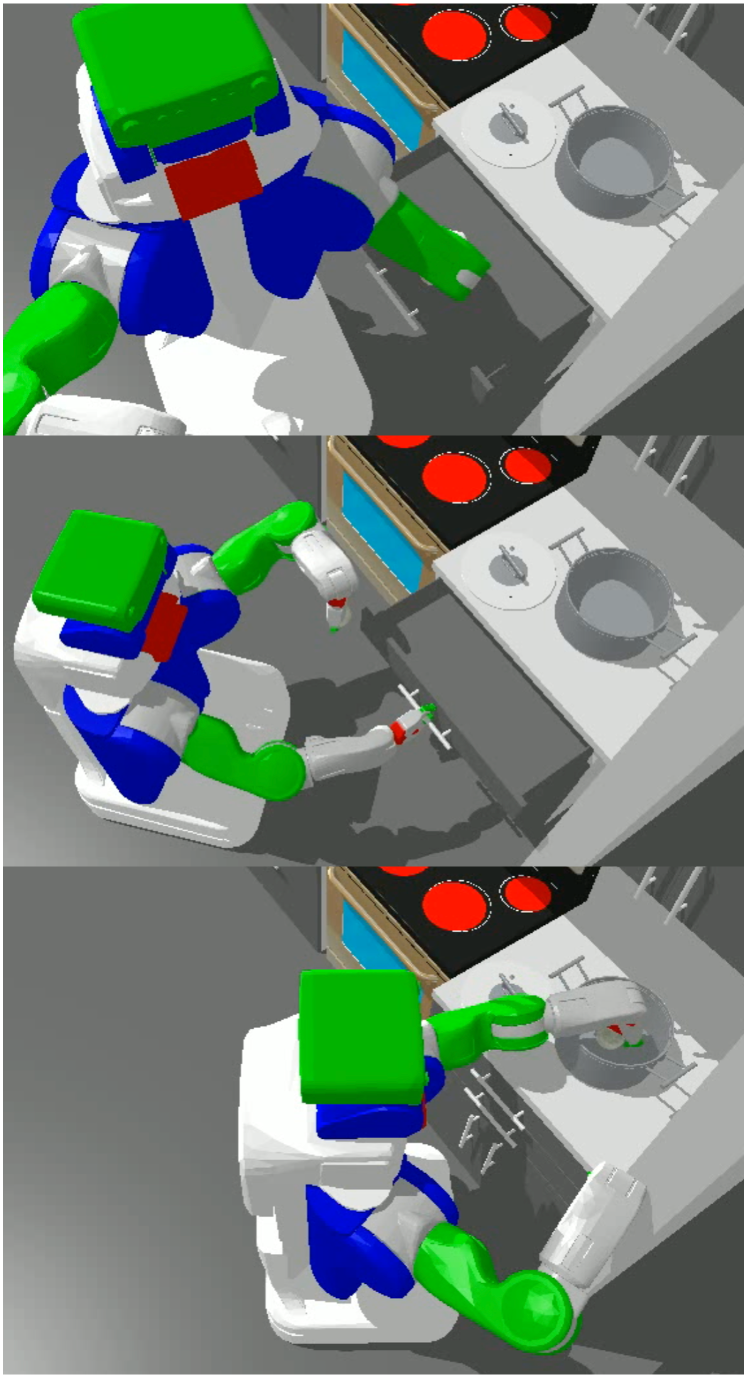

Figure 1: Dual-arm Rummy directly picks and places the cabbage as its arms are long enough to reach far.
The system assumes access to a 3D geometric model of the environment, a robot embodiment, and a natural language goal (e.g., "make chicken soup"). The VLM receives a rendered image of the scene annotated with object names, bounding boxes, and spatial relations, as well as a textual description of the environment. This multimodal input enables the VLM to generate a sequence of intermediate subgoals or actions.
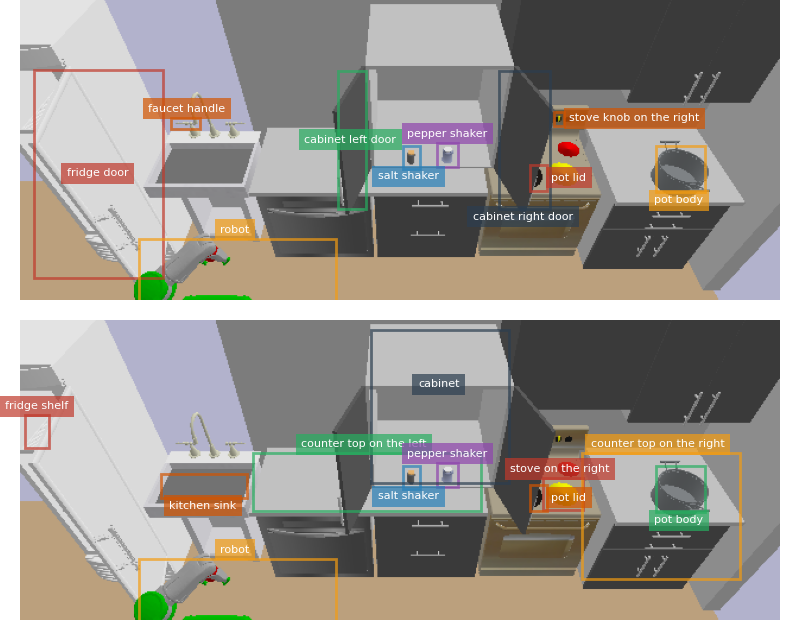
Figure 2: An example input image to the VLM, annotated with object names, bounding boxes, movable objects, articulated joints, and placement surfaces.
VLM-TAMP operates in two modes:
- Subgoal Prediction: The VLM generates a sequence of subgoals in a formal language (PDDL predicates), which are then solved sequentially by TAMP.
- Action Prediction: The VLM generates a sequence of high-level actions, which are directly refined by TAMP into executable trajectories.
The system includes a Problem Manager (PM) that formulates TAMP subproblems and a Task Planner (TP) that checks the semantic validity of subgoals. If a subgoal or action cannot be refined due to geometric or kinematic infeasibility, the VLM is reprompted with updated state and collision information.
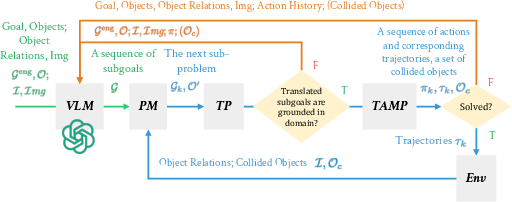
Figure 3: The VLM-TAMP algorithm, showing the interaction between the VLM, Problem Manager, Task Planner, and TAMP refinement loop.
Methodology
VLM Querying and Translation
The VLM is prompted with a structured template that includes the goal, object list, spatial relations, and an annotated image. The response is a sequence of intermediate subgoals or actions in English, which are then translated into PDDL predicates or action tuples. Semantic validation is performed to ensure type correctness and argument validity. If errors are detected, the VLM is reprompted with explicit feedback.
TAMP Refinement
For each subgoal or action, TAMP constructs a subproblem using a reduced set of relevant objects to minimize branching factor. The planner attempts to find a feasible plan skeleton and refines it by sampling continuous parameters (object poses, grasps, robot configurations). If planning fails due to collisions or sampling failures, additional objects are incrementally included, and the process is retried up to a fixed budget. If all attempts fail, the VLM is reprompted with updated collision and execution history.
Replanning and Robustness
The iterative reprompting mechanism allows the system to recover from VLM errors, semantic inconsistencies, and geometric infeasibility. The approach assumes the absence of irreversible dead-ends, enabling the decomposition of long-horizon problems into tractable subproblems.
Experimental Evaluation
The evaluation focuses on a challenging kitchen manipulation domain, where a robot must execute 30–50 actions to achieve cooking goals involving up to 21 objects and articulated elements. Two robot embodiments are considered: single-arm and dual-arm manipulators. Four task variants are tested, varying the number of obstacles and initial conditions.
Six methods are compared:
- VLM-TAMP (subgoal prediction) with 0, 1, or 2 reprompt attempts
- VLM-action sequencing (action prediction) with 0, 1, or 2 reprompt attempts
Each method is run for 30 random trials per task variant. Metrics include task success rate (all subgoals/actions refined and executed) and task completion percentage (fraction of subproblems solved).
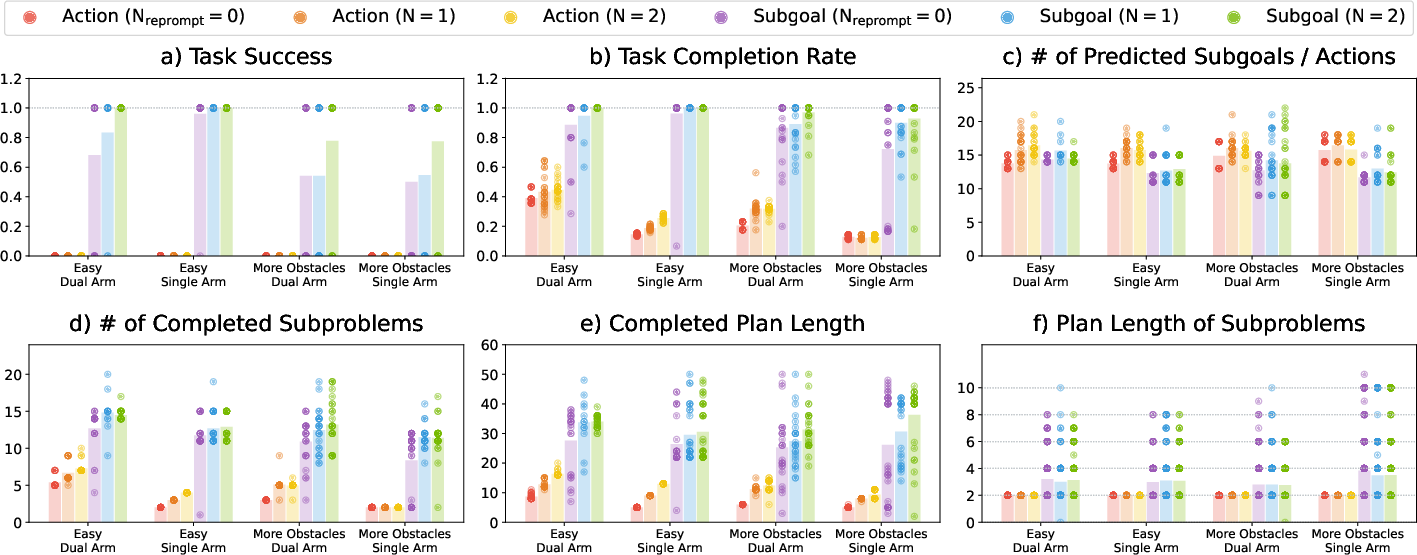
Figure 4: Experimental results showing that (1) subgoal prediction (VLM-TAMP) outperforms action prediction, and (2) reprompting improves performance for subgoal prediction but not for action prediction, across increasing problem difficulty and robot complexity.
Key Results
- VLM-TAMP achieves 50–100% success rates on long-horizon tasks, while action prediction baselines achieve 0% success.
- Task completion percentage for VLM-TAMP is 72–100%, compared to 15–45% for action prediction.
- Reprompting increases VLM-TAMP success by 47–55% on the hardest problems, but does not improve action prediction baselines.
- The TAMP planner effectively fills in missing or infeasible actions (e.g., moving obstacles, opening doors) that VLMs typically omit.
Failure Analysis
- Translation errors: The VLM may generate subgoals/actions with incorrect argument types, missing objects, or misspellings.
- Infeasible actions: The VLM may propose actions that violate preconditions (e.g., attempting to pick up an object with a full hand) or are blocked by the environment.
- Plan skeleton search: The correct plan skeleton may not be found within the allowed search budget, especially in high-dimensional subproblems.
- Sampling failures: Low-level samplers (pose, grasp, IK) may fail to find feasible parameters within the compute budget.
Implications and Future Directions
VLM-TAMP demonstrates that leveraging VLMs for subgoal generation, rather than direct action sequencing, enables robust, scalable, and geometrically feasible long-horizon planning. The hierarchical decomposition reduces TAMP's computational burden and allows for effective recovery from VLM errors via reprompting. The results indicate that current VLMs are not reliable for direct action prediction in complex, embodied domains, but are effective at generating semantically meaningful subgoals when coupled with a geometric planner.
Practical implications include improved autonomy for service robots in unstructured environments, with the ability to handle diverse embodiments and scene layouts. Theoretically, the work highlights the importance of modular, hierarchical planning architectures that combine data-driven semantic reasoning with model-based geometric planning.
Future research directions include:
- Training end-to-end visuomotor policies to achieve VLM-generated subgoals directly from perception.
- Extending the approach to real-world, partially observed environments with noisy perception.
- Investigating tighter integration between VLMs and TAMP, such as learning to predict subgoal decompositions that optimize for geometric feasibility and planning efficiency.
Conclusion
VLM-TAMP provides a principled framework for integrating vision-LLMs with task and motion planning, enabling robust, long-horizon robot manipulation in complex environments. The empirical results establish that subgoal-based decomposition, combined with iterative replanning, substantially outperforms direct action sequencing approaches. This work advances the state of the art in embodied AI by demonstrating the practical benefits of hierarchical, modular planning systems that leverage the complementary strengths of large-scale pretrained models and symbolic-geometric planners.

