- The paper demonstrates a novel LITEN method that dynamically learns robot affordances during execution without retraining.
- It employs a two-level hierarchical model where a high-level VLM decomposes tasks and a low-level VLA executes subtasks, guided by structured feedback.
- Experimental evaluations reveal iterative improvements and superior task completion over baselines, emphasizing the impact of in-context assessment.
Learning Affordances at Inference-Time for Vision-Language-Action Models
Introduction
This paper introduces Learning from Inference-Time Execution (LITEN), a method for enabling vision-language-action (VLA) models to learn robot affordances dynamically at inference time, without additional training. LITEN leverages a two-level hierarchical architecture: a high-level vision-LLM (VLM) decomposes complex tasks into subtasks, while a low-level VLA policy executes these subtasks. Critically, LITEN iteratively refines its planning by incorporating structured feedback from previous executions, allowing the system to adapt to the robot's capabilities and environmental constraints. This approach addresses the limitations of current VLA models, which typically operate in single-shot settings and lack mechanisms for contextual adaptation based on prior failures or successes.
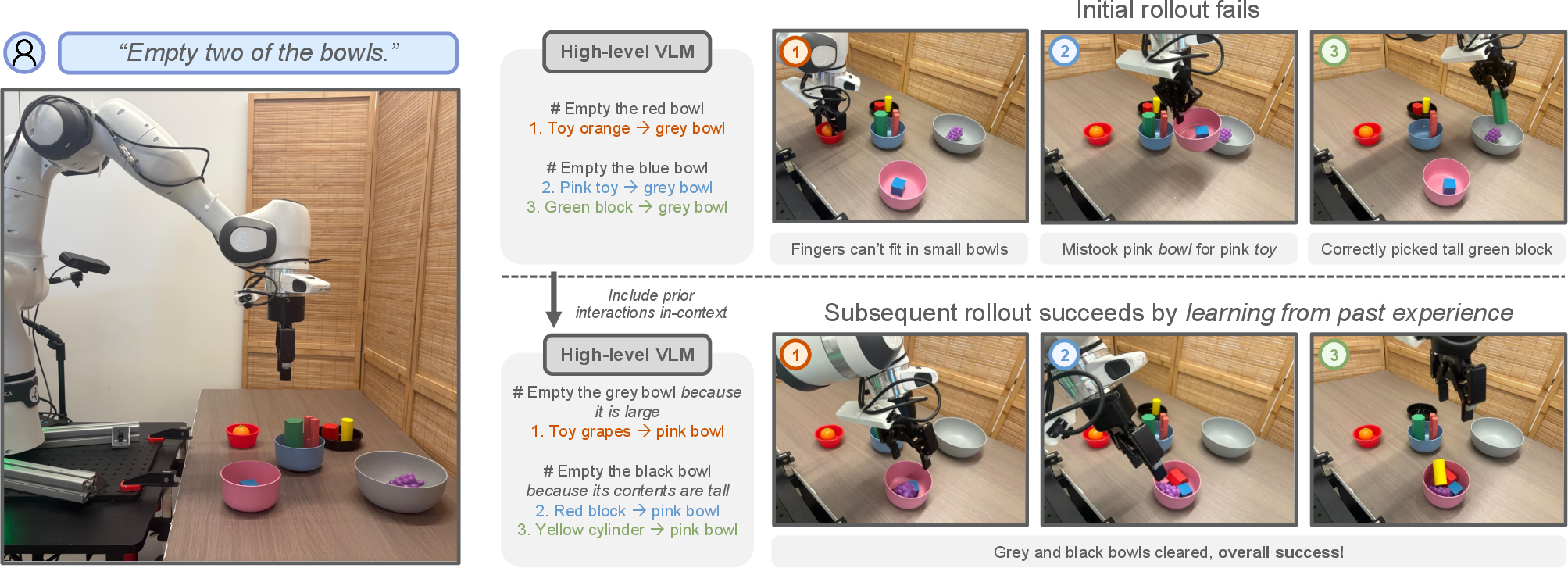
Figure 1: LITEN leverages a two-level hierarchical model to reason about complex tasks based on prior experience collected at inference-time, enabling affordance learning and performance improvement.
Methodology
Hierarchical Reasoning and Assessment Loop
LITEN operates in an iterative loop comprising two phases:
- Reasoning Phase: The high-level VLM receives a natural language task description and an initial scene observation. It generates a sequence of subtask instructions, constrained to the style of commands the VLA can execute. These subtasks are then executed sequentially by the VLA, producing a trajectory for each subtask.
- Assessment Phase: After execution, a VLM judge evaluates each subtask's outcome using structured prompts. The judge determines success or failure, describes what happened in case of failure, reasons about the cause, and suggests minimal changes to improve success likelihood. The assessment is performed using only the initial and final images of each subtask, as current VLMs struggle with raw video comprehension.
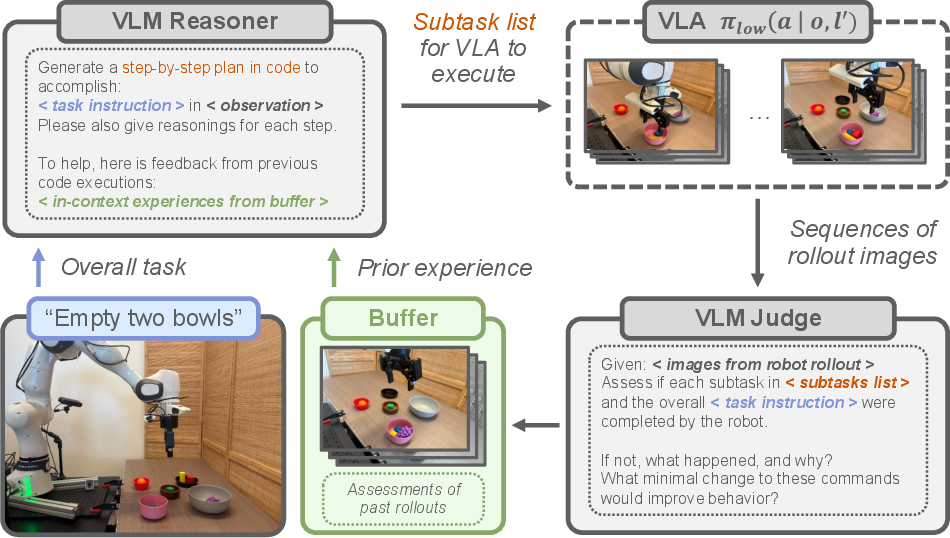
Figure 2: LITEN cycles between reasoning (task decomposition and execution) and assessment (structured evaluation of outcomes), iteratively improving by including assessment outputs in the VLM's context.
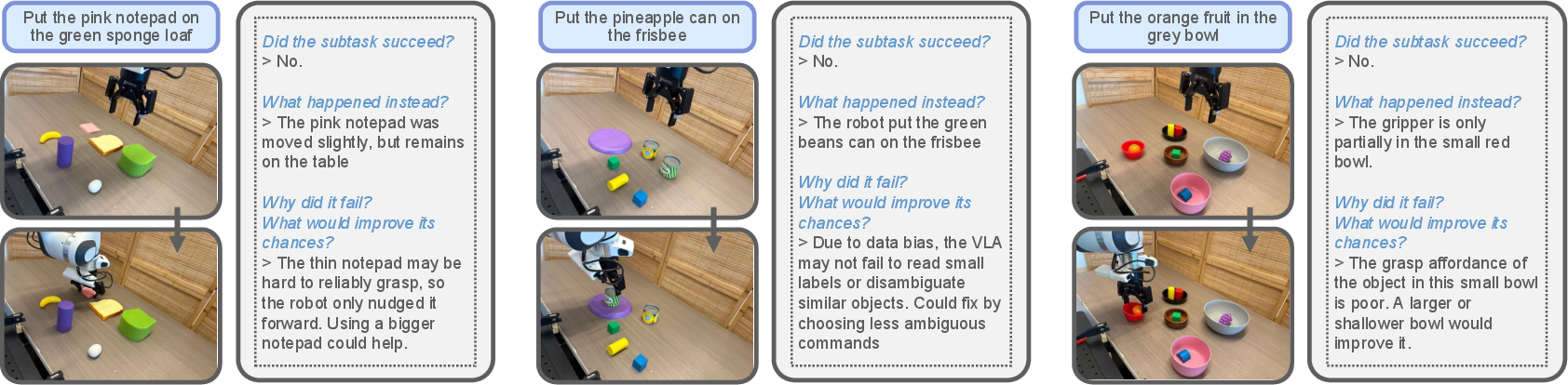
Figure 3: Examples of VLM judge's prompt and output for three subtasks, illustrating the structured feedback used for subsequent reasoning.
In-Context Experience Integration
The structured feedback from the assessment phase is incorporated in-context for the next reasoning phase. The VLM reasoner is instructed to prioritize subtasks with high empirical success, try new instructions, and rephrase unlikely instructions to maximize success. This enables the system to learn affordances—what the robot can and cannot do—based on accumulated experience, without retraining the underlying models.
Implementation Details
LITEN is instantiated using GPT-5-mini as the high-level VLM and π0.5-DROID as the low-level VLA, operating on a Franka Emika Panda robot arm. The reasoning phase is a single VLM request that includes the task, initial observation, prior experience, and usage instructions. The VLA executes subtasks with a fixed horizon, and the robot is reset between subtasks. The assessment phase uses a chain of VLM prompts for each subtask and the overall task, storing results hierarchically for future iterations.
Experimental Evaluation
Task Suite and Baselines
LITEN is evaluated on three multi-stage manipulation tasks requiring affordance learning:
- Stacking: Stack three objects, requiring the VLM to learn which objects are stackable.
- Emptying Bowls: Move contents between bowls, requiring the VLM to learn which bowls are graspable.
- Moving Off Table: Move objects such that only three remain on the table, requiring the VLM to learn manipulability and stability constraints.
Baselines include:
- Reflexion: Adaptation of LLM self-refinement to robotics, using video reflections.
- Positive-ICL: Only successful subtasks are retained in-context.
- No-Feedback: No prior experience is used.
Quantitative Results
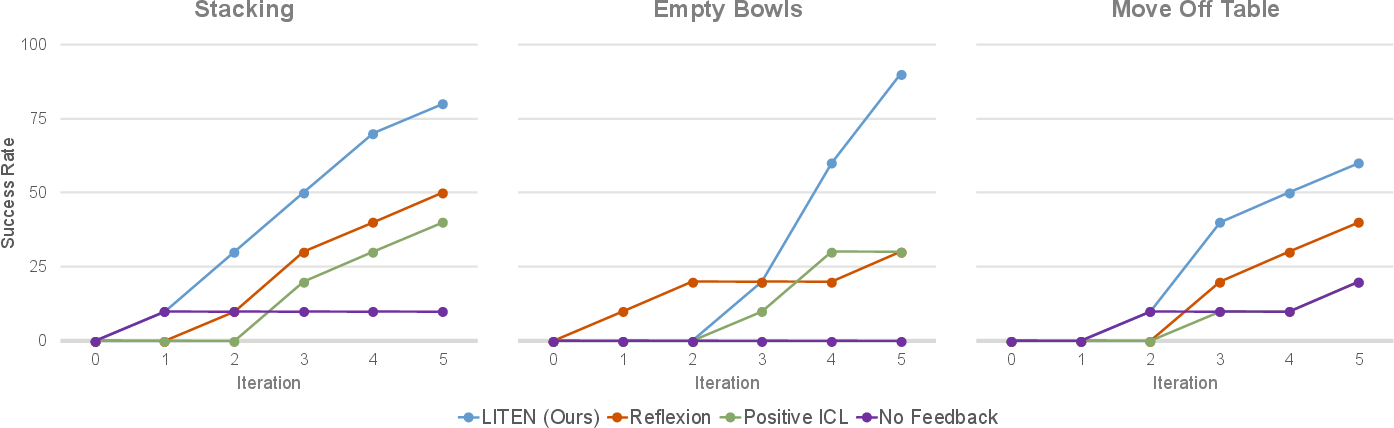
Figure 4: Success rates for full completion of each multi-stage task over five attempt iterations, showing consistent improvement with LITEN as more experience is collected.
LITEN demonstrates consistent improvement in task success rates over consecutive attempts, outperforming all baselines. The No-Feedback baseline is unable to solve any tasks, highlighting the necessity of learning from experience. Positive-ICL is inefficient due to reliance on random successful plans, and Reflexion struggles with unstructured video data.
Ablation Study
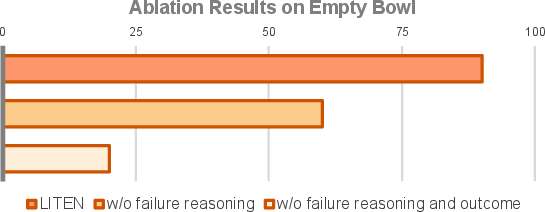
Figure 5: Success rates after five attempts with ablations of LITEN's assessment phase. Removing any assessment component dramatically reduces performance, underscoring the importance of structured feedback.
Ablating components of the assessment phase reveals that providing only binary success/failure signals is insufficient. Failure reasoning and outcome analysis are critical for effective affordance learning.
Qualitative Analysis

Figure 6: Examples of initial configurations and solutions for the evaluated tasks.
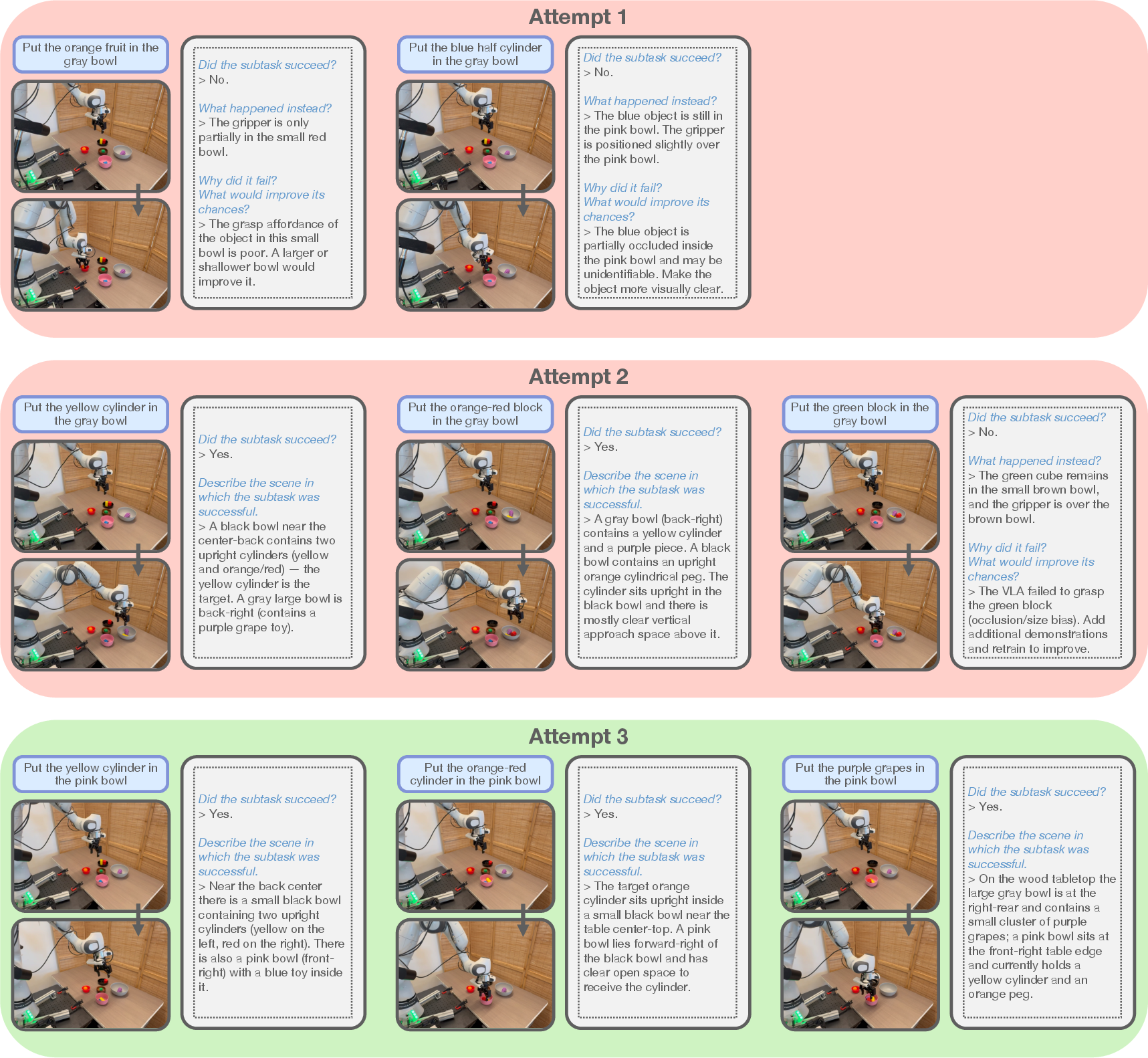
Figure 7: Example sequence of attempts for LITEN on the Empty Bowls task, culminating in successful execution.
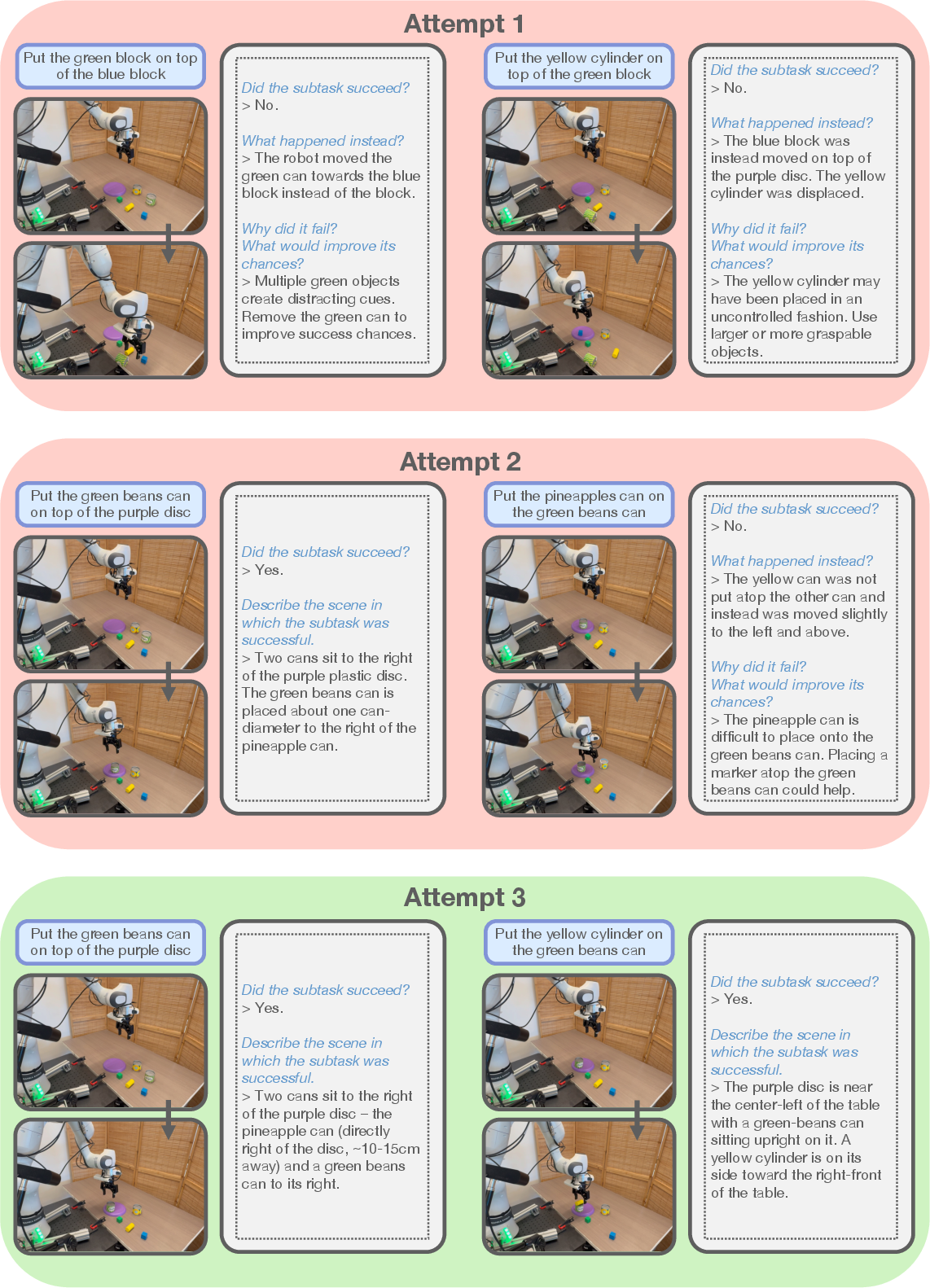
Figure 8: Example sequence of attempts for LITEN on the Stacking task, showing iterative refinement and eventual success.
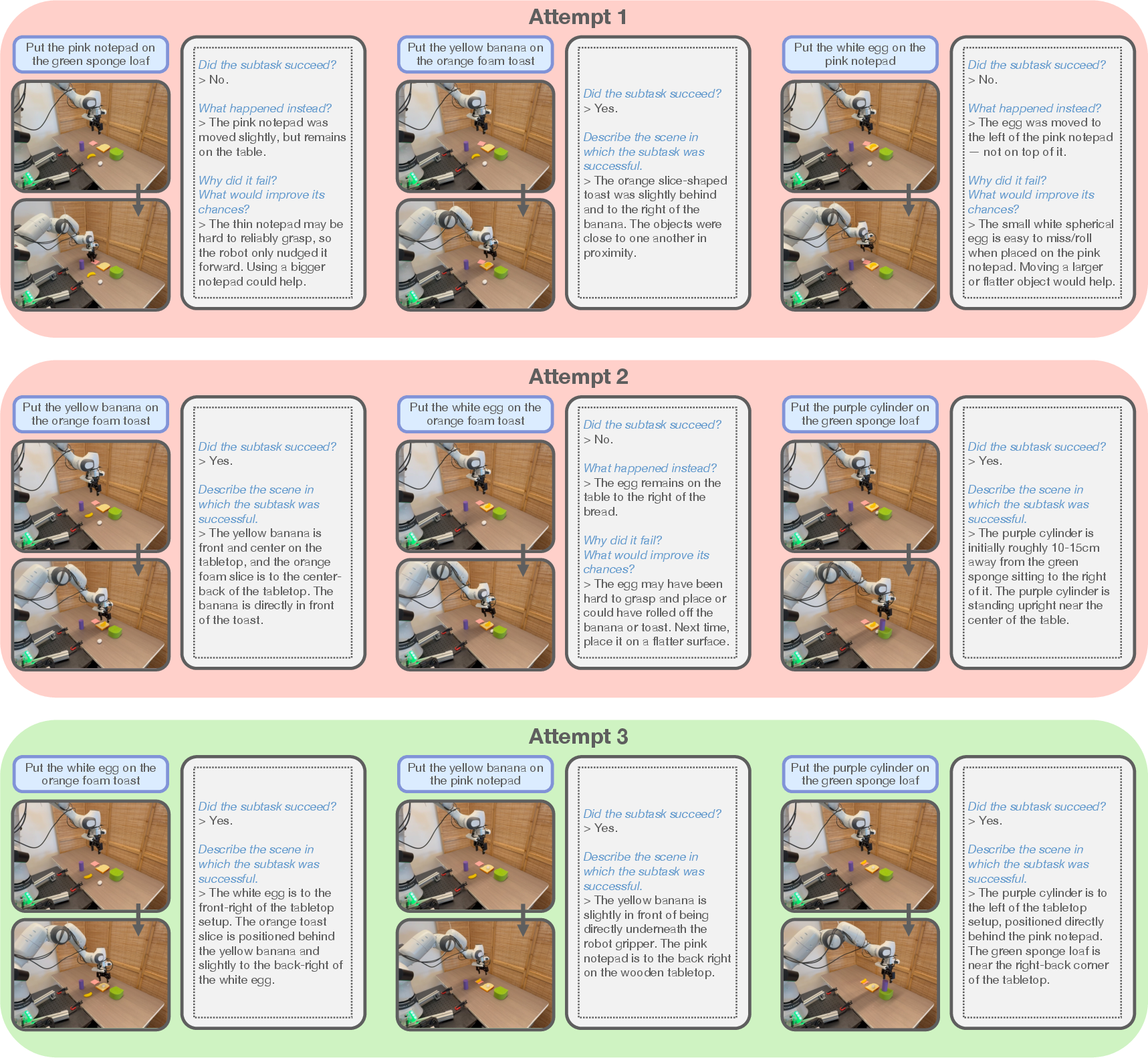
Figure 9: Example sequence of attempts for LITEN on the Empty Bowls task, illustrating the evolution of subtask plans and feedback.
LITEN effectively learns from failures due to VLA biases and physical constraints. For instance, it adapts plans when the VLA prefers larger objects or when precise stacking is infeasible. The structured assessment enables the VLM to diagnose failures and adjust future plans accordingly, unlike baselines that lack fine-grained feedback.
Failure Modes and Limitations
LITEN's failures are primarily due to VLA stochasticity, misattribution of failures to language rather than control, and insufficient causal reasoning across subtask sequences. The system may fixate on borderline affordances or misdiagnose control errors as language issues. Additionally, successful individual subtasks may not compose to overall task success due to lack of cross-subtask reasoning. Improving VLM video comprehension and causal reasoning capabilities is a clear direction for future work.
Implications and Future Directions
LITEN demonstrates that inference-time affordance learning is feasible and effective for real-world robotics, leveraging off-the-shelf VLMs and VLAs without retraining. The method is hardware-agnostic and broadly applicable, with potential for lifelong learning across diverse tasks. Scaling to large prior datasets will require advanced context management, such as retrieval-augmented generation. As VLMs and VLAs improve in physical understanding and language following, LITEN's efficacy will correspondingly increase.
Conclusion
LITEN provides a principled framework for enabling VLA models to learn affordances at inference time through structured reasoning and assessment. The approach yields substantial improvements in complex manipulation tasks, outperforming baselines and demonstrating the critical role of in-context experience and structured feedback. Future work should address limitations in causal reasoning and video comprehension, and explore scaling to lifelong and large-scale learning scenarios.

