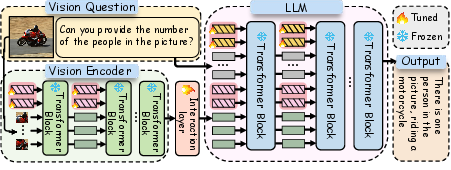
- The paper introduces M²PT, a parameter-efficient framework integrating visual and textual prompts to boost zero-shot learning in multimodal LLMs.
- It employs a novel cross-modality interaction that projects visual embeddings into the language space, achieving near full fine-tuning performance with only 0.09% of parameters updated.
- Empirical results on datasets like MME and CIFAR-100 demonstrate its robust scalability and potential for sustainable, resource-efficient model adaptation.
M2PT: Multimodal Prompt Tuning for Zero-shot Instruction Learning
The paper "M2PT: Multimodal Prompt Tuning for Zero-shot Instruction Learning" introduces a novel approach aimed at enhancing zero-shot generalization in Multimodal LLMs (MLLMs) through Multimodal Prompt Tuning (M2PT). The strategy focuses on parameter-efficient instruction tuning, which integrates visual and textual prompts during model fine-tuning to improve feature extraction and alignment across modalities. This essay will explore the methodology, empirical evaluation, and implications of the proposed M2PT approach.
Multimodal Prompt Tuning Framework
M2PT is designed to address the challenges associated with the increasing scale and complexity of MLLMs, which demand more sustainable parameter-efficient tuning methods:
Empirical Evaluation
The empirical performance of M2PT was extensively evaluated on various multimodal datasets, demonstrating its superiority over existing state-of-the-art PEFT methods:
- Superior Performance: M2PT significantly outperformed baselines such as LoRA, APrompt, and PTUM on multimodal tasks, achieving results close to fully fine-tuned models with just 0.09% of the total parameter updates.
- Efficient Zero-shot Learning: Despite using fewer parameters, M2PT succeeded in tasks that require integration across vision and language, such as MME and CIFAR-100, illustrating the robustness and efficiency of its prompt-based tuning approach.
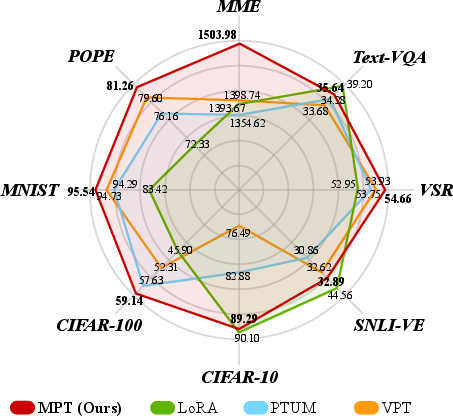
Figure 2: Comparison of M2PT and several PEFT methods, including LoRA, PTUM, and VPT, on multimodal tasks.
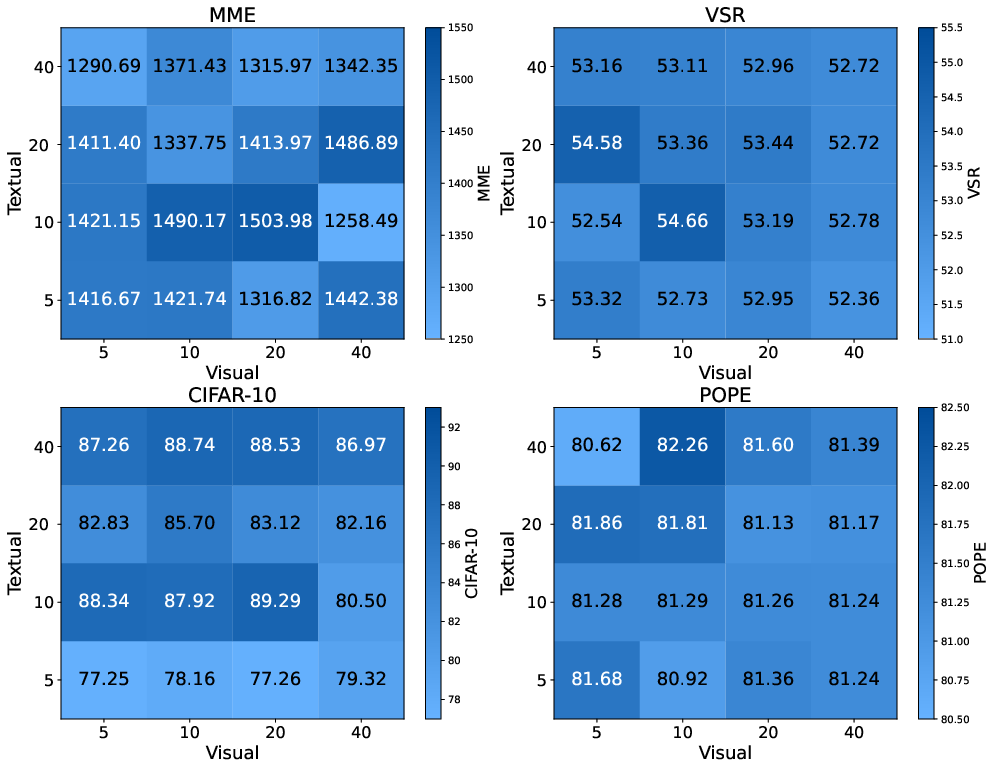
Analysis of Prompts and Layer Interactions
Through the visualization of attention activation maps, the study analyzed the impact of visual and textual prompts:
- Attention Activation: Both visual and textual prompts showed significant activation at key layers, with visual prompts exhibiting strong activations within the vision encoder and textual prompts influencing the LLM layers.
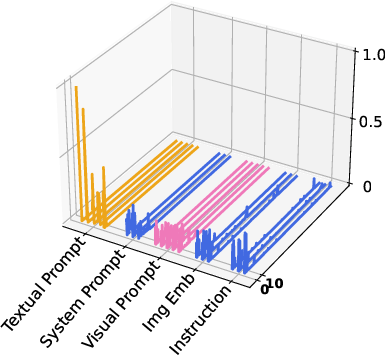
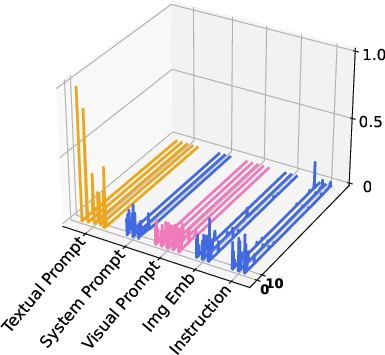
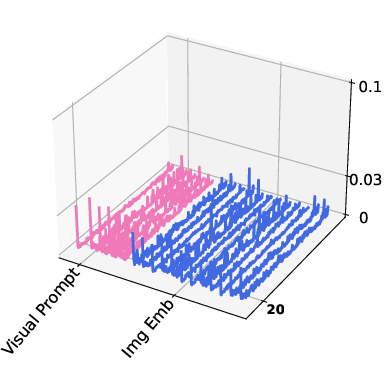
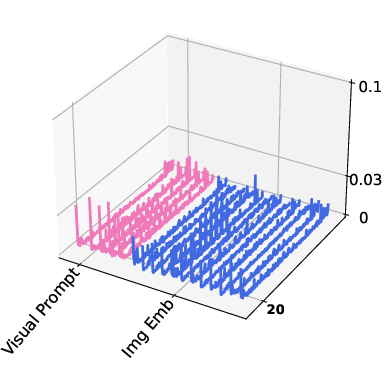
Figure 3: Visualization of attention activation maps showing high activation levels for vision and textual prompts during inference.
Insights on Prompt Configuration
Several experiments explored different aspects of prompt configuration:
Practical and Theoretical Implications
M2PT illustrates potential paths forward for real-world application and further research:
- Scalability and Efficiency: By reducing the computational footprint through parameter-efficient tuning, M2PT promotes the sustainability of deploying large-scale multimodal models.
- Future Directions: This work encourages continued exploration into parameter-efficient methods that maintain performance parity with full fine-tuning while offering new opportunities for domain-adaptive applications in resource-constrained environments.
Conclusion
M2PT successfully advances multimodal instruction tuning by innovatively applying soft prompts to balance efficiency and efficacy. The approach demonstrates the potential to adapt MLLMs effectively across diverse tasks with minimal parameter updates, contributing significant insights into scalable AI model adaptation.