Multimodal Prompt Optimization: Why Not Leverage Multiple Modalities for MLLMs
Abstract: LLMs have shown remarkable success, and their multimodal expansions (MLLMs) further unlock capabilities spanning images, videos, and other modalities beyond text. However, despite this shift, prompt optimization approaches, designed to reduce the burden of manual prompt crafting while maximizing performance, remain confined to text, ultimately limiting the full potential of MLLMs. Motivated by this gap, we introduce the new problem of multimodal prompt optimization, which expands the prior definition of prompt optimization to the multimodal space defined by the pairs of textual and non-textual prompts. To tackle this problem, we then propose the Multimodal Prompt Optimizer (MPO), a unified framework that not only performs the joint optimization of multimodal prompts through alignment-preserving updates but also guides the selection process of candidate prompts by leveraging earlier evaluations as priors in a Bayesian-based selection strategy. Through extensive experiments across diverse modalities that go beyond text, such as images, videos, and even molecules, we demonstrate that MPO outperforms leading text-only optimization methods, establishing multimodal prompt optimization as a crucial step to realizing the potential of MLLMs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Multimodal Prompt Optimization (MPO) — A simple explanation
1) What is this paper about?
This paper is about making AI systems that understand both words and other kinds of information—like pictures, videos, or even molecule diagrams—work better by giving them better “prompts.” A prompt is like the instructions you give an AI before asking it to do something. Most past methods only improved the words in the prompt. This paper says: why not also improve the non-text parts (like a helpful example image)? They introduce a new method called MPO that improves both the text and the non-text parts together.
2) What questions are the researchers asking?
The paper focuses on a few simple questions:
- If an AI can use more than just text, can we make it perform better by optimizing both the words and the non-text examples it sees?
- How can we keep the text and non-text parts “in sync” so they don’t send mixed messages?
- How can we quickly pick the most promising prompts without wasting time testing too many weak ideas?
3) How did they do it? (Methods in everyday language)
Think of training an AI like helping a student study with a guide that has both instructions (text) and helpful examples (images, short videos, or diagrams). The paper’s method, MPO, improves that study guide in two smart ways:
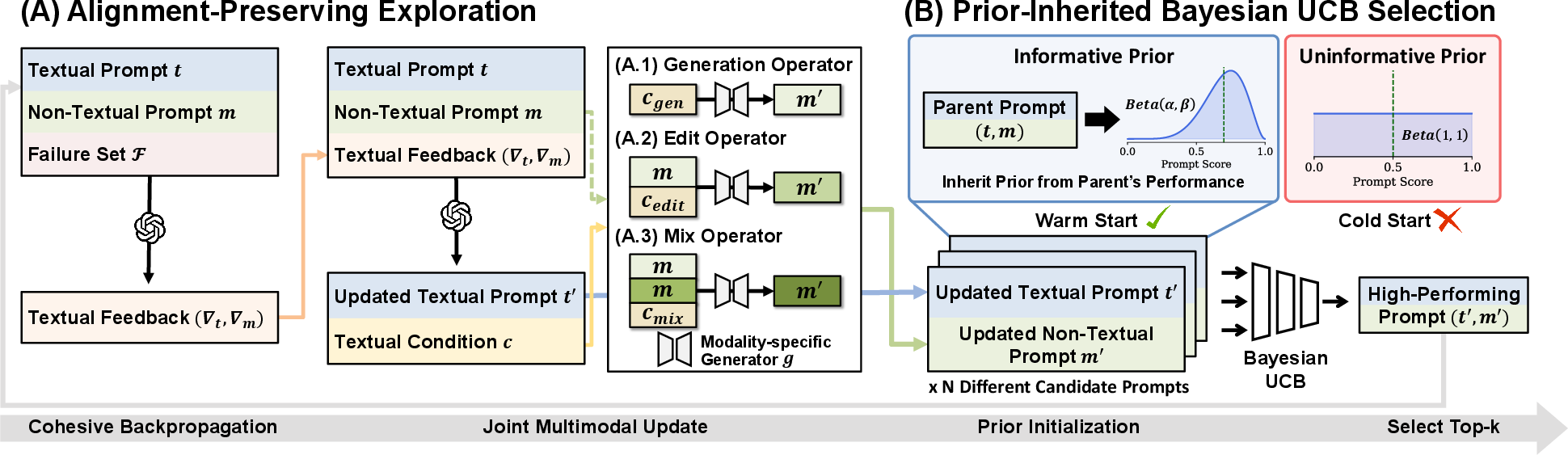
- Part A: Alignment-preserving exploration
- improve the written instructions (text), and
- guide how to create or adjust the non-text example (like an image or video clip).
- This keeps the words and examples aligned—so they support each other instead of confusing the AI.
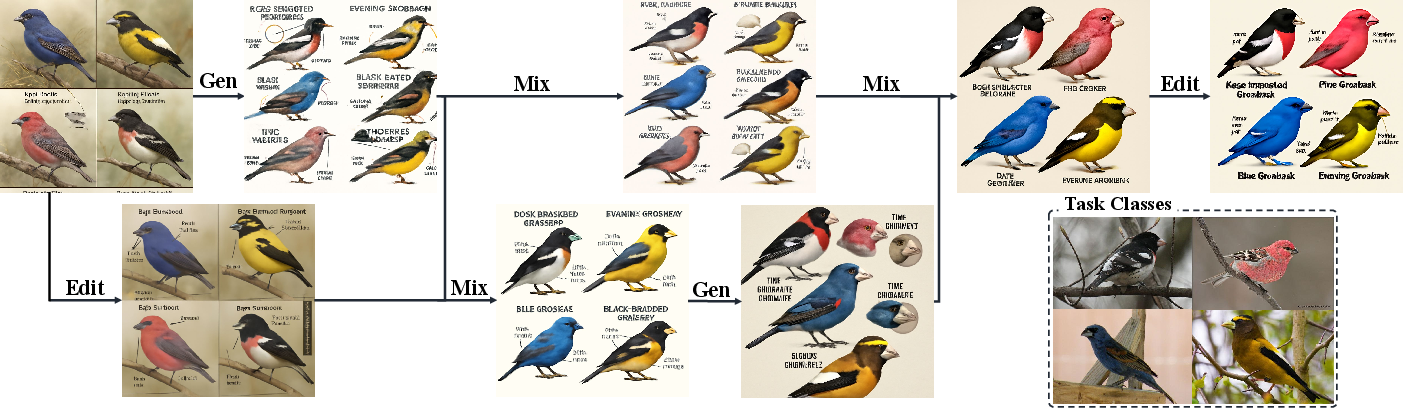
To explore different ideas, MPO uses three simple operators. These are like ways to improve or vary the non-text example: - Generation: make a brand-new example from scratch using the feedback. - Edit: take the current example and tweak specific parts based on the feedback. - Mix: combine the best parts from several examples to make a stronger one.
- Part B: Smarter selection with “prior-inherited Bayesian UCB” Testing every new prompt equally would waste time. Instead, MPO assumes that if a “parent” prompt was good, its “child” versions (small improvements of it) are likely to be good too. So, when deciding which new prompts to test, MPO gives extra credit to those coming from strong parents. In plain terms: it uses a smart try-the-best-first strategy that relies on clues from earlier results. This saves testing time and quickly zooms in on the best prompts.
4) What did they find, and why does it matter?
Across many tasks—like recognizing diseases on leaves from images, answering questions about medical or driving scenes, understanding videos, and predicting molecule properties—MPO beat the best text-only methods. Here’s why this matters:
- Using both words and helpful non-text examples gives the AI clearer, richer guidance than words alone.
- Keeping the text and non-text parts aligned leads to big performance gains.
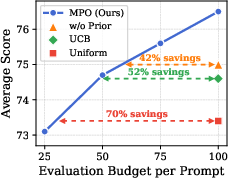
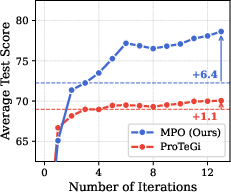
- The “smart selection” step means MPO can reach high performance while testing far fewer prompts, saving time and compute. In their tests, MPO reached the same accuracy with much less evaluation budget (they report large savings, for example around 40–70% depending on the comparison).
They also showed:
- The three operators (Generate, Edit, Mix) each help in different ways, and using all three works best.
- Their approach works with different backbone models and tools—that means it’s flexible and not tied to one specific AI system.
- Both parts of the prompt matter: the improved text helps, and the improved non-text helps, but the best results come when they are optimized together.
5) What’s the bigger impact?
This research suggests a simple idea with big payoff: if an AI can understand multiple kinds of input, we should optimize all of them, not just the words. That could make AI better at real-world jobs where pictures, videos, or diagrams matter—like medical imaging, self-driving scenarios, or even drug discovery. It also saves time and cost because it finds strong prompts faster. In short, MPO helps unlock the full power of multimodal AIs by teaching them with better, well-matched instructions and examples.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, formulated to guide future research.
- Formal definition and injection mechanism of non-textual prompts: The paper does not precisely standardize what constitutes a “non-textual prompt” across modalities (image, video, molecule), nor how these prompts are tokenized/injected into different MLLMs (e.g., as reference frames, prototype images, synthetic molecules, or learned embeddings). Establishing modality-specific schemas and consistent interfaces would enable reproducibility and fair comparison.
- Modeling of performance metrics in Bayesian UCB: The selection strategy treats prompt performance as Bernoulli (Beta posteriors), yet many tasks use multi-class accuracy, F1, or continuous scores. A generalization to non-Bernoulli rewards (e.g., Gaussian, Dirichlet-multinomial, Beta-binomial, or heteroscedastic models) and a principled mapping from task metrics to reward distributions is left unaddressed.
- Parent–child correlation validation across tasks and modalities: The strong correlation (Pearson r = 0.88) is shown on a single dataset (CUB). Systematically testing whether this holds for videos, molecules, medical/remote sensing VQA, and under different model families is necessary to justify prior inheritance broadly.
- Theoretical guarantees for selection under hierarchical and non-stationary arms: Beyond Proposition 1, there is no regret or sample-complexity analysis for a dynamic, hierarchical search tree where arm distributions change across iterations (children depend on parents). Extending theory to hierarchical bandits or tree-based Bayesian optimization would strengthen guarantees.
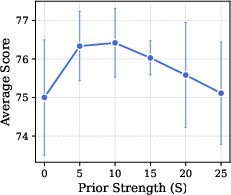
- Sensitivity analyses beyond prior strength S: Only S is ablated. The paper does not analyze sensitivity to beam size (b), number of iterations (T), per-operator proportions (generation/edit/mix ratios), batch size for evaluation, or selection quantile used in Bayesian UCB. Establishing principled defaults and auto-tuning strategies would make MPO more robust.
- Robustness of LLM-derived “semantic gradient” feedback: The unified feedback is produced by an optimizer LLM (e.g., GPT-4o mini), which can be noisy, biased, or fail under domain shift. Quantifying the reliability of failure analyses, calibrating critique quality, and exploring self-consistency or verification mechanisms are open directions.
- Cross-modal alignment quantification beyond images: MPO’s alignment analysis relies on the DSG score (an image–text measure). There is no general metric for video–text or molecule–text alignment. Developing modality-agnostic alignment metrics (or task-specific surrogates) and testing their correlation with downstream performance remains open.
- Failure cases and spurious correlations in non-textual prompts: While alignment improves performance on average, the paper does not analyze cases where non-textual prompts introduce spurious features that mislead the MLLM (e.g., backgrounds, common artifacts, or scaffold biases in molecules). Stress-testing for distribution shifts and adversarial cues would clarify risks.
- End-to-end compute, latency, and cost accounting: The efficiency analysis focuses on selection budget, but omits the computational cost of generating/editing/mixing non-textual prompts (image/video synthesis, molecule generation/validation), inference latency, and API costs. Quantifying end-to-end resource demands and proposing budget-aware strategies is needed for practical deployment.
- Quality control and validity in molecule generation: The paper uses general-purpose LLMs for molecule prompting without reporting chemical validity rates (e.g., SMILES correctness, stereochemistry), physical plausibility, property distributions, toxicity filters, or synthetic accessibility (SA). Incorporating cheminformatics validation, constraints, and domain-specific generators is essential.
- Baseline breadth for multimodal prompting: Comparisons are limited to text-only APO and few-shot prompting. Missing baselines include (i) human-curated multimodal prompts, (ii) retrieval-based prototype images/videos/molecules, (iii) simple multimodal augmentations (e.g., generic domain-reference images), and (iv) instance-specific multimodal prompting adapted for task-level prompts. Adding these would test whether MPO’s gains exceed more straightforward multimodal designs.
- Clarification of how video prompts are formed and used: The paper does not specify how non-textual video prompts are constructed (length, frames, compression) nor how they are incorporated alongside query videos (as separate streams, concatenation, or reference embeddings). Standardizing prompt-video construction and assessing memory/latency impacts is a gap.
- Mixing operator implementation details: The “mix” operator combines multiple non-textual prompts, but the paper lacks specifics on mixing algorithms (e.g., alpha blending, feature-level fusion, semantic composition), hyperparameters, and guarantees against artifacts. Clear, reproducible procedures and ablations on mixing strategies are needed.
- Generalization to additional modalities and multimodal combinations: MPO is tested on images, videos, and molecules, but audio, 3D, point clouds, charts/plots, and sensor streams are not studied. Extending the framework and alignment metrics to these modalities and combinations (e.g., audio–video–text) would broaden applicability.
- Interaction with instance-specific prompting: MPO targets reusable task-level prompts; integrating it with instance-specific techniques (e.g., MM-CoT, visual bounding-box prompts, query-conditioned references) and measuring additive or diminishing returns is unexplored.
- Interpretability and human-in-the-loop editing: Non-textual prompts may be less interpretable to practitioners (e.g., synthetic videos/molecules). Mechanisms for explaining why a multimodal prompt works, auditing alignment, and enabling expert edits/constraints (especially in safety-critical domains) are not addressed.
- Transferability across models and tasks: While generalizability across backbones is reported, it is unclear whether the same optimized non-textual prompt transfers across model families or related tasks without re-optimization. Systematic cross-model/task transfer studies and criteria for universality of prompts are missing.
- Data splits and evaluation protocol clarity: The selection process evaluates candidates on “small batches” without detailing whether a separate validation set is used, raising potential selection–test leakage concerns. Clear separation of train/validation/test sets and reporting of variance across seeds would strengthen claims.
- Safety and ethical considerations in generative prompts: The paper’s ethics section does not assess risks from generated images/videos (e.g., misleading medical imagery) or molecules (e.g., toxic/controlled substances). Introducing safety filters, domain constraints, and ethics assessments tailored to each modality is necessary.
- Calibration, uncertainty, and reliability: The work reports accuracy/F1 but does not evaluate calibration of predictions, uncertainty estimates, or the incidence of hallucinations under multimodal prompts. Assessing reliability and adding calibration-aware optimization could improve trustworthiness.
- Handling weak or negative parent priors: The prior-inherited UCB presumes informative parent–child relationships. Strategies for detecting and down-weighting weak/negative correlations (e.g., meta-learning of prior strength, robust priors, or switching to non-inherited selection) remain to be developed.
- Automatic operator selection and curriculum: The paper allocates operators evenly (generation/edit/mix) except at initialization. Learning when to favor each operator (e.g., via meta-bandits or reinforcement learning), operator scheduling, and adaptive curricula could improve efficiency.
- Memory and token budget constraints: Non-textual prompts, especially videos, can be large. The paper does not measure memory, context-window utilization, or attention bottlenecks induced by adding non-textual prompts. Establishing prompt size trade-offs and compression strategies is needed.
- Domain-specific evaluation for medical and scientific tasks: Beyond aggregate accuracy/F1, task-relevant metrics (e.g., clinical utility in radiology, pharmacological plausibility in molecules) and expert review are absent. Incorporating domain evaluations would validate real-world usefulness.
- Robustness under model/API drift: MPO relies on external optimizer/generator APIs. The impact of model updates, rate limits, and non-determinism on optimization stability and reproducibility is not studied. Methods to mitigate drift (e.g., caching, version pinning, stochastic ensembling) are an open need.
Glossary
- Alignment-preserving exploration: A strategy to jointly refine textual and non-textual prompt components so they remain semantically consistent across modalities. "Alignment-preserving exploration analyzes a failure set to generate feedback, which is then used both to refine the textual prompt and to guide a modality-specific generator to create a new non-textual prompt with one of three operators."
- Automatic Prompt Optimization (APO): A research area focused on automating the discovery and refinement of effective prompts for LLMs. "the field of Automatic Prompt Optimization (APO) has emerged, whose goal is to automate the discovery of effective prompts"
- Bandit-based allocation: An evaluation budgeting approach that uses multi-armed bandit algorithms to balance exploration and exploitation over candidate prompts. "bandit-based allocation, such as UCB~\citep{UCB, ProTeGi}, which adaptively balances exploration and exploitation."
- Bayesian UCB: A bandit method that computes upper confidence bounds using Bayesian posterior estimates to guide which candidate to evaluate next. "the best-arm identification cost of Bayesian UCB is nonincreasing,"
- Best-arm identification cost: The evaluation budget or sample complexity required to identify the highest-performing option in a bandit setting. "the best-arm identification cost of Bayesian UCB is nonincreasing,"
- Beta distribution: A continuous probability distribution used here to model the expected success rate of prompts via pseudo-counts of successes and failures. "we model the expected score of each multimodal prompt as a Beta distribution, ,"
- Bernoulli KL divergence: A measure of divergence between two Bernoulli distributions, used to analyze informativeness of priors. "where is the Bernoulli KL divergence."
- Beam search: A heuristic search algorithm that keeps a limited set (beam) of top candidates at each iteration to navigate large search spaces. "we use the beam search~\citep{ProTeGi} with the beam size of "
- Chain-of-Thought (CoT): A prompting strategy that elicits step-by-step reasoning before producing the final answer. "Chain-of-Thought (CoT)~\citep{CoT}, which uses the widely adopted phrase âLetâs think step by step,â"
- Cold-start problem: The inefficiency that arises when new candidates lack prior information, making early evaluations unproductive. "both paradigms suffer from an inefficient cold-start problem: newly generated prompts are treated as independent arms with no prior information,"
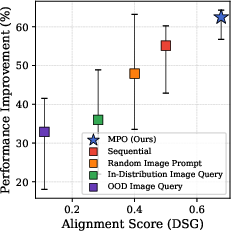
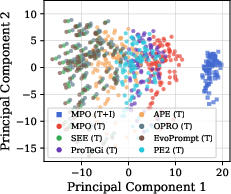
- Cross-modal alignment: The consistency of information across modalities (text, image, etc.), crucial for effective multimodal reasoning. "Relationship between cross-modal alignment and performance gain."
- DSG score: A metric designed to quantify cross-modal alignment between textual and visual components. "we measure the relationship between performance gain over the Human baseline and the DSG score designed to quantify alignment~\citep{DSGscore}."
- Edit operator: An exploration mechanism that performs fine-grained refinements of an existing non-textual prompt while preserving useful structure. "This operator performs fine-grained refinements of non-textual prompts (e.g., textures) while retaining useful structures from the prior prompt."
- Evolutionary algorithms: Optimization approaches inspired by biological evolution (e.g., mutation and crossover) used to explore prompt spaces. "others borrow ideas from evolutionary algorithms (e.g., mutation and crossover) to explore the prompt space~\citep{Evoprompt, promptbreeder}."
- Failure set: The subset of evaluated instances where the model’s output differs from the ground truth, used to derive feedback for prompt updates. "We begin by identifying a failure set "
- Generation operator: An exploration mechanism that creates entirely new non-textual prompts from scratch, guided by textual conditions. "This operator explores entirely new non-textual prompts, e.g., novel spatial arrangements in visual inputs or unique substructures in molecules."
- In-Distribution Image Query: A variant analysis where the image component is replaced with one sampled from the same task, to test alignment and performance. "(3) In-Distribution Image Query, where it is replaced with an image sampled from the same task;"
- Kleene Star: A formal language operator denoting a finite sequence over a set, used to define MLLM input sequences. " denotes the Kleene Star (representing a finite sequence over the combined spaces)."
- Mix operator: An exploration mechanism that blends multiple non-textual prompts under a learned mixing condition to synthesize complementary strengths. "Mix operator. This operator blends the complementary strengths of multiple multimodal prompts."
- Modality-specific encoders: Components (e.g., vision or audio encoders) aligned with LLM backbones to process non-textual inputs in multimodal models. "which aligns modality-specific encoders (e.g., vision or audio) with LLM backbones,"
- Modality-specific generators: External generative modules (e.g., text-to-image, text-to-molecule) used to produce or revise non-textual prompt components. "modality-specific generators (such as text-to-image or text-to-molecule modules),"
- Multimodal LLMs (MLLMs): Models that process sequences including both text and non-textual modalities and generate textual outputs. "Multimodal LLMs (MLLMs) extend the capabilities of LLMs by processing inputs that combine text with non-textual modalities."
- Multimodal pre-training: Large-scale training that aligns encoders from different modalities with an LLM backbone before fine-tuning. "these models are typically trained through large-scale multimodal pre-training, which aligns modality-specific encoders (e.g., vision or audio) with LLM backbones,"
- Multimodal prompt optimization: The problem of jointly optimizing textual and non-textual prompts to maximize task performance in MLLMs. "we introduce the new problem of multimodal prompt optimization,"
- OOD Image Query: A variant analysis where the image component is replaced with one sampled from a different task (out-of-distribution). "(4) OOD Image Query, where it is replaced with an image sampled from a different task."
- Parent-Child Correlation: The observed positive correlation between a parent prompt’s performance and the average performance of its child prompts. "Parent-Child Correlation"
- PCA: Principal Component Analysis, used to visualize differences in internal hidden-state representations induced by prompts. "Visualization of hidden states in MLLMs by PCA."
- Posterior parameters: The updated Beta distribution parameters (α, β) reflecting observed successes and failures during bandit evaluation. "and update its posterior parameters and ."
- Preference optimization: A post-training paradigm that aligns model outputs with human or task-specific preferences via feedback signals. "followed by post-training stages such as supervised fine-tuning and preference optimization to endow them with multimodal instruction-following abilities"
- Prior strength: A hyperparameter controlling how strongly a child prompt’s initial Beta prior is inherited from its parent’s posterior mean. "prior strength hyperparameter ,"
- Prior-Inherited Bayesian UCB: A selection strategy that initializes each child prompt’s prior using its parent’s posterior to warm-start bandit evaluation. "we propose prior-inherited Bayesian UCB, a selection strategy that initializes the score distribution of a new child prompt based on the posterior of its parent (rather than uniform)."
- Pseudo-observations: Artificial counts added to a prior to encode inherited information before any new evaluations. "provides pseudo-observations to newly generated child prompts,"
- Semantic gradient: A unified feedback signal derived from failure analysis that guides coherent updates across modalities. "single semantic gradient (i.e., feedback) to ensure their alignment"
- Soft prompts: Learned continuous embeddings prepended to inputs to steer model behavior without fine-tuning all parameters. "learns continuous embedding vectors (i.e., soft prompts) that are prepended to model inputs to steer behavior~\citep{MaPLe, ModalPrompt, M2PT}."
- UCB: Upper Confidence Bound, a bandit algorithm that balances exploration and exploitation when selecting candidates to evaluate. "such as UCB~\citep{UCB, ProTeGi}"
- Warm start: Initializing a model or selection process with informative priors to reduce early-stage inefficiency. "warm-starting the search to effectively identify high-performing prompts among candidates."
Practical Applications
Summary
The paper introduces Multimodal Prompt Optimization (MPO), a framework that optimizes prompts for Multimodal LLMs (MLLMs) by jointly refining textual and non-textual components (e.g., images, videos, molecules) and by selecting candidates efficiently using a prior-inherited Bayesian UCB strategy. MPO’s two key innovations are:
- Alignment-preserving exploration: a single, unified feedback signal (from failure analysis) drives coherent updates to both text and non-textual prompts via three operators (generation, edit, mix), using modality-specific generators (e.g., text-to-image).
- Prior-inherited Bayesian UCB selection: warm-starts evaluation of child prompts using the parent’s posterior performance, reducing evaluation cost and accelerating discovery of high-performing prompts.
Below, practical applications are grouped into immediate vs. long-term, with sector linkages, potential products/tools/workflows, and feasibility assumptions.
Immediate Applications
These are deployable now with existing MLLMs, off-the-shelf modality-specific generators, and typical enterprise evaluation pipelines.
Healthcare
- Radiology and medical VQA assistance (SLAKE-like): Improve QA accuracy by embedding optimized visual exemplars alongside textual instructions to guide MLLMs in reasoning about scans and medical imagery.
- Sector: Healthcare
- Tools/workflows: MPO-driven prompt co-pilot inside PACS viewers; alignment-preserving edits to add representative reference images; Bayesian-UCB evaluation scheduler to select best prompts under limited annotation budgets.
- Assumptions/dependencies: Non-diagnostic use; human-in-the-loop; access to de-identified, licensed images; institutional approval; MLLMs competent in medical terminology.
- Clinical education and simulation: Generate multimodal teaching prompts (text + curated images) that highlight salient findings, improving training question banks and tutoring systems.
- Sector: Healthcare education
- Tools/workflows: MPO integrated into LMS authoring; generation/mix operators to create diverse but aligned visual exemplars.
- Assumptions/dependencies: Copyright-cleared images; careful review to avoid hallucinated medical claims.
Drug discovery and cheminformatics
- ADME-tox and property triage (Absorption, BBBP, CYP inhibition): Use MPO to co-optimize textual assay instructions and molecular representations (as non-textual prompts) to boost screening accuracy and prioritize candidates.
- Sector: Pharma/biotech
- Tools/workflows: MPO loop connected to molecular depiction/generation tools; Bayesian-UCB to minimize compound-level evaluation costs; automated failure set analysis from retrospective screens.
- Assumptions/dependencies: Reliable molecule encoders in the MLLM; validated evaluation metrics; domain SMEs for oversight.
Automotive and mobility
- Driver monitoring and in-cabin activity recognition (DriveAct): Improve driver state classification by optimizing visual exemplars and textual guidelines for camera feeds.
- Sector: Automotive
- Tools/workflows: MPO-based prompt pack for DMS systems; edit operator for fine-tuning environment-specific lighting, camera placement; bandit-based evaluation under budget constraints.
- Assumptions/dependencies: Privacy-compliant video data; stable camera configurations; edge-to-cloud inference compatibility.
- Scene understanding and driving VQA (DrivingVQA): Enhance incident summarization and situational queries by combining text with reference frames or short clips.
- Sector: Automotive/insurance/fleet
- Tools/workflows: MPO-generated visual prompt boards for common maneuvers/edge cases; selection policy to keep evaluation costs low.
- Assumptions/dependencies: Latency budget compatible with adding references; robust performance in varied weather/lighting.
Remote sensing and geospatial analytics
- Land use/land cover and remote-sensing VQA (RSVQA-like): Improve MLLM performance by adding optimized satellite exemplars and textual constraints for region-specific tasks.
- Sector: Energy, climate, agriculture, public sector
- Tools/workflows: MPO pipelines inside geospatial analytics platforms; mix operator to build hybrid reference images reflecting composite terrains.
- Assumptions/dependencies: Licensed satellite imagery; geo-bias considerations; domain calibration for spectral bands.
Enterprise AI and MLOps
- Multimodal prompt engineering copilots: Productize MPO as a developer tool that suggests, edits, and mixes textual and visual prompt components to meet KPI targets.
- Sector: Software/tools
- Tools/workflows: SDK or plugin for LangChain/LlamaIndex; UI to preview generation/edit/mix outputs; automatic failure set curation; Bayesian-UCB evaluator.
- Assumptions/dependencies: Access to MLLMs with image/video inputs; reliable text-to-image/video APIs.
- Budget-efficient evaluation schedulers: Use prior-inherited Bayesian UCB to cut evaluation costs for any prompt optimization workflow (including text-only), especially at cold start.
- Sector: Software/marketing/ops
- Tools/workflows: Bandit microservice for prompt/variant testing; dashboards showing posterior means and UCBs; API-first integration with CI/CD.
- Assumptions/dependencies: Metric approximable as Bernoulli or bounded scalar; meaningful parent-child structure (correlated performance).
Education and training
- Multimodal tutoring and assessment: Generate aligned visual examples alongside textual scaffolds to improve question answering on charts, diagrams, and lab videos.
- Sector: Education/edtech
- Tools/workflows: MPO-enabled content authoring; generation/edit operators to refine didactic visuals; classroom trials with small evaluation budgets.
- Assumptions/dependencies: Content licensing; accessibility compliance (alt-text, captions).
Content moderation and support operations
- Policy compliance and incident triage: Improve accuracy on visual policy enforcement by co-optimizing textual rules and curated edge-case image boards.
- Sector: Trust & Safety, customer support
- Tools/workflows: MPO-generated exemplar library; Bayesian-UCB to choose top-performing rule+exemplar sets.
- Assumptions/dependencies: Clear, measurable policies; careful handling of sensitive imagery.
Data labeling and QA
- Human-in-the-loop labeling assistants: Provide optimized multimodal prompts to boost LLM-assisted labeling quality for images/videos, reducing rework.
- Sector: Data ops
- Tools/workflows: MPO inside labeling platforms; automatic failure-set-driven edits to prompts; rolling A/B testing with UCB.
- Assumptions/dependencies: Label definitions stable; interface for quick evaluator feedback.
Long-Term Applications
These require further research, scaling, regulatory clearance, or robust system integration.
Clinical decision support and regulated deployment
- Decision support with certified MLLMs: Use MPO to create rigorously validated, aligned multimodal prompts for specific diagnostic pathways (e.g., radiology findings, dermatology).
- Sector: Healthcare
- Potential products: “Regulated MPO Packs” with locked prompts/exemplars; audit logs; bias and performance reports.
- Assumptions/dependencies: Regulatory approval (e.g., FDA/CE); robust provenance and watermarking of generated exemplars; extensive prospective validation.
Autonomy and robotics
- On-device, real-time multimodal prompt adaptation: Robots and ADAS systems refine prompts on the fly using alignment-preserving edits to handle environment shifts.
- Sector: Robotics/automotive/industrial
- Potential products: Low-latency MPO modules; edge-compatible generators; safety monitors to veto risky updates.
- Assumptions/dependencies: Deterministic latency; safety certification; robust fallback procedures.
Scientific discovery loops
- Closed-loop molecular design: Combine MPO-driven molecular prompt generation/edit/mix with lab assays to iteratively improve properties (active learning).
- Sector: Pharma/materials
- Potential products: “MPO-Lab” orchestrator that integrates assay feedback as failure sets; Bayesian-UCB to allocate assays efficiently.
- Assumptions/dependencies: Validated molecular representations; reliable structure-property generalization; lab throughput alignment.
Personalized multimodal assistants
- User-specific multimodal memory and prompts: Assistants that maintain visual notebooks and optimize prompts to reflect user preferences and environments.
- Sector: Consumer software
- Potential products: “Prompt Memory” that stores/refines personal visual references; auto-adaptation to user tasks.
- Assumptions/dependencies: Privacy-preserving storage; on-device inference at scale; robust consent management.
Synthetic data and augmentation ecosystems
- Targeted synthetic reference generation: Use MPO to produce high-value, aligned non-textual prompts that capture failure modes and enrich training datasets.
- Sector: ML data platforms
- Potential products: Synthetic exemplar catalogs; distribution-shift-aware mix operator pipelines.
- Assumptions/dependencies: Proven domain transfer from synthetic to real; watermarking and provenance tracking; bias audits.
Cross-domain policy and standards
- Benchmarks and auditing for multimodal prompt optimization: Establish evaluation standards, safety testing, and environmental budgeting (e.g., documenting 40–70% budget reductions).
- Sector: Policy/standards
- Potential products: “MPO Benchmark Suite” and audit templates; best-practice guidelines for using synthetic media in sensitive domains.
- Assumptions/dependencies: Multistakeholder buy-in; datasets with transparent licenses; standardized metrics per domain.
Advanced bandit and hierarchical optimization
- Generalized hierarchical warm-start bandits: Extend prior-inherited Bayesian UCB to multi-level prompt trees (e.g., reasoning chains, tool-use graphs) and non-Bernoulli metrics.
- Sector: Optimization/ML platforms
- Potential products: Hierarchical bandit libraries with theoretical guarantees; adaptive prior strength schedulers.
- Assumptions/dependencies: Stable parent-child correlations; robust posterior modeling for non-binary KPIs.
Energy-efficient and edge deployments
- Green evaluation strategies: Leverage warm-start selection to minimize compute and emissions in large-scale prompt searches; enable low-power edge evaluation.
- Sector: Energy/sustainability/edge AI
- Potential products: “Eco-UCB” schedulers; carbon dashboards integrated with prompt ops.
- Assumptions/dependencies: Reliable accounting of energy per evaluation; schedulers integrated with cluster resource managers.
Key Assumptions and Dependencies (Cross-cutting)
- Model capabilities: Access to MLLMs that accept and reason over multiple modalities; quality of modality-specific generators (image/video/molecule) materially affects outcomes.
- Evaluation modeling: Prior-inherited Bayesian UCB assumes meaningful parent-child performance correlation and metrics that can be reasonably modeled with Beta-Bernoulli or adapted posteriors.
- Data and licensing: Use of generated non-textual prompts requires proper licensing, watermarking, and provenance tracking; sensitive domains (e.g., medical) require strict governance.
- Robustness and alignment: Unified feedback must capture true failure modes; risk of overfitting to spurious cues if failure sets are not representative; monitor for distribution shifts.
- Human oversight and safety: Especially in high-stakes domains, MPO outputs should be treated as decision support with validation, not as automated decision-makers.
- Compute and latency: Multimodal prompt search and generation impose costs; budget-aware selection helps but deployment must align with latency constraints (e.g., edge or real-time systems).
These applications translate MPO’s core findings—joint multimodal prompt refinement and warm-started selection—into concrete tools and workflows that can lift performance, cut evaluation costs, and expand the utility of MLLMs across sectors.
Collections
Sign up for free to add this paper to one or more collections.