- The paper presents a novel, lightweight framework that incrementally aligns modalities using fixed, pretrained encoders and efficient alignment layers.
- It introduces a Universal Projection module and Alignment Layer to project diverse modality features into a unified embedding space with minimal training.
- The framework achieves strong performance in zero-shot classification, cross-modal retrieval, and VQA while significantly reducing computational costs.
"OneEncoder: A Lightweight Framework for Progressive Alignment of Modalities"
Introduction
"OneEncoder" proposes an efficient and scalable framework for cross-modal alignment, addressing critical limitations in current multimodal models that require extensive computational resources and large datasets for training. The paper introduces a lightweight alignment framework that incrementally aligns modalities using pretrained modality-specific encoders, a Universal Projection (UP) module, and an Alignment Layer (AL).
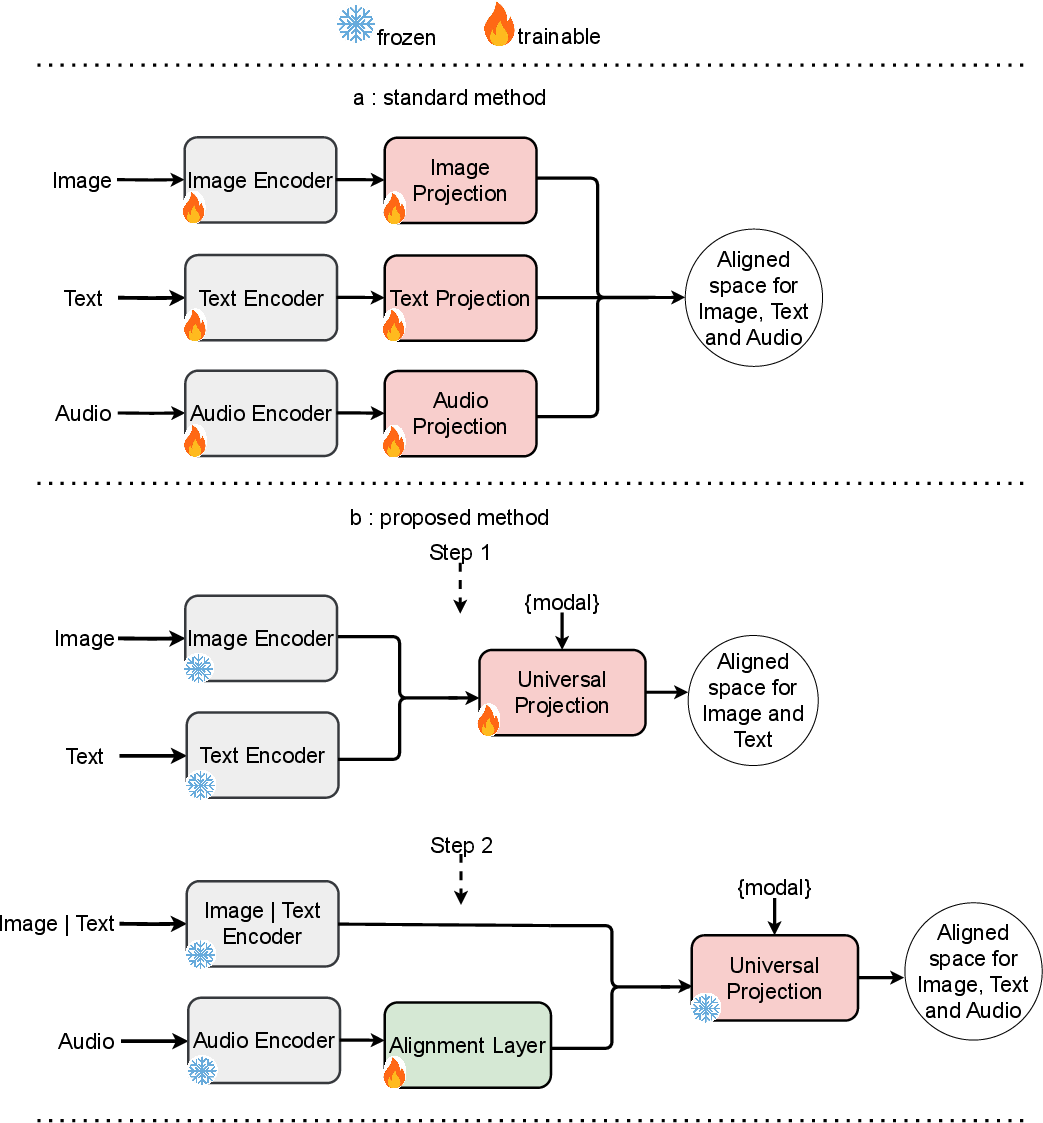
Figure 1: Comparison of three modality alignment methods: Standard cross-modal vs. OneEncoder. Standard aligns via simultaneous training of modality-specific encoders. OneEncoder uses frozen, pretrained encoders with a lightweight Universal Projection (UP) module trained on two modalities. For new modalities, UP stays frozen, training only the Alignment Layer. Modality tokens enable efficient switching between modalities. Using this method, video can be aligned with other modalities (image, text, audio) in the same way.
Model Architecture
The OneEncoder architecture consists of several key components: modality-specific encoders, a Universal Projection (UP) module, and an Alignment Layer (AL), each playing a vital role in the progressive alignment framework.
Modality-Specific Encoders
OneEncoder employs frozen pretrained models for each modality, such as ViT for images, BERT for text, Wav2Vec2 for audio, and VideoMAE for video. These models extract modality-specific features, maintaining computational efficiency by eliminating the need to train these large encoders from scratch.
Universal Projection Module
The UP module is designed to project features from multiple modalities into a unified embedding space. It utilizes transformer layers to capture inter-modal relationships and aligns image-text modalities initially. The UP incorporates modality tokens to facilitate seamless transitions and alignments across modalities, providing a coherent latent space for multimodal tasks.
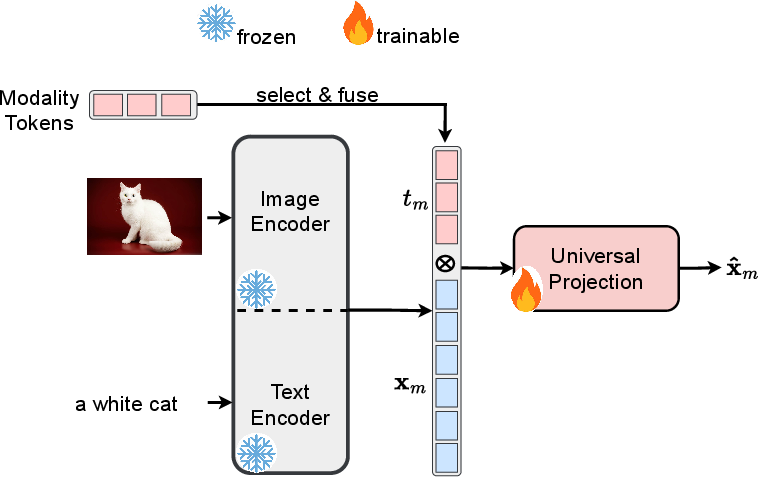
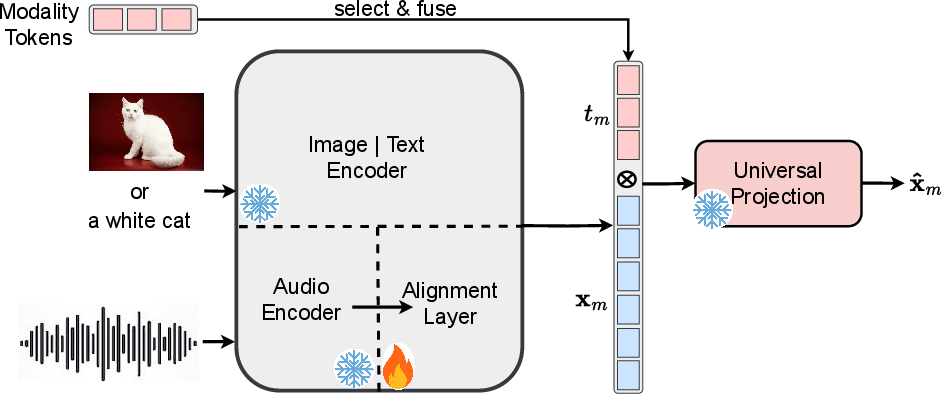
Figure 2: Step 1: Training the Lightweight UP and Aligning Image-Text Modalities
Alignment Layer
Upon aligning initial modalities, subsequent modalities are integrated using the AL. This lightweight MLP reduces the alignment complexity, facilitating efficient modality addition without retraining the entire framework. The AL projects new modality data into the shared alignment space established by the pretrained UP.
Training Procedure
The training process in OneEncoder follows a two-step approach: initial alignment and progressive alignment.
Initial Alignment
During the first step, the UP is trained using a contrastive learning framework on abundant, aligned datasets (e.g., image-text pairs). The UP defines a common semantic space for the initial modalities, guided by a learned contrastive objective to preserve mutual information.
Progressive Alignment
In subsequent steps, the pretrained UP remains fixed, and only the AL is updated. This setup allows OneEncoder to incorporate new modalities with minimal training cost by aligning them through already-aligned modalities, such as using text to align audio and video via text-audio or text-video datasets.
Applications and Evaluation
Zero-Shot Classification
OneEncoder demonstrates exceptional performance in zero-shot image classification tasks across various datasets, outperforming traditional models that require retraining all modality-specific encoders.
Cross-Modal Retrieval
The effectiveness of OneEncoder extends to cross-modal retrieval tasks between text, audio, and video, demonstrating superior alignment performance validated through metrics like Top-1 precision and recall.
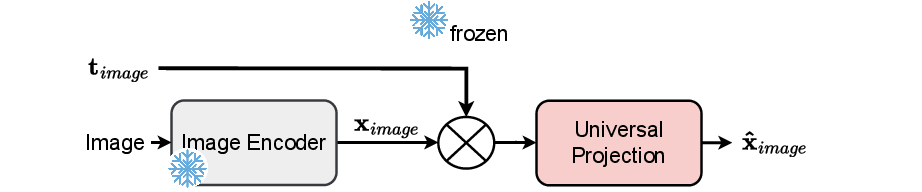



Figure 3: Image processing
Visual Question Answering
OneEncoder accommodates tasks beyond retrieval, such as Visual Question Answering (VQA), by using lightweight alignment strategies tailored to capture the intricacies of cross-modal reasoning required for accurate VQA.
Conclusion
OneEncoder introduces an innovative approach to multimodal integration, characterized by its lightweight design and progressive alignment strategy. By leveraging pretrained modality-specific encoders and focusing training on the UP and AL, OneEncoder achieves strong performance across diverse multimodal tasks with significantly reduced computational costs. This framework is poised to expand into more complex domains and can be adapted for high-demand tasks like open-vocabulary object detection, highlighting its potential for efficient and scalable multimodal learning.

