- The paper demonstrates that adaptive LLM guidance paired with user-driven exploration significantly enhances reflective self-agency.
- It employs a hybrid pipeline integrating theme generation, Socratic questioning, and objective summarization to support personalized cognitive reflection.
- Empirical results show increased user engagement and self-agency with measurable improvements (Δmean=2.63, Cohen’s d=0.66).
ExploreSelf: User-Driven Reflective Processing of Personal Challenges via LLM-Adaptive Guidance
Motivation and Position within Prior Art
ExploreSelf addresses a critical shortcoming in technology-mediated reflective writing for well-being: the tension between structure and user autonomy. Classical approaches such as pre-defined journaling prompts, self-help workbooks, and therapeutic modules impose linearity and fixed content tracks, often limiting individuals’ agency over the trajectory of their self-exploration. Recent LLM-driven systems provide context-sensitive prompts or chat-based guidance, but the default conversational paradigm can reinforce passivity and even inadvertently foster negative thought ruts by overly steering or “therapizing” the interaction.
ExploreSelf distinguishes itself by intentionally decoupling adaptive guidance from a strictly agent-led turn-taking structure. Instead, it affords users maximal agency in steering topic selection, depth of inquiry, and the granularity of guidance received. The system design and accompanying study are firmly situated in the literature on psychological well-being, expressive writing, human-AI collaboration, and adaptive user modeling (2409.09662).
System Architecture and Generative Pipelines
ExploreSelf operationalizes expert-informed design rationales to orchestrate a hybrid pipeline of user-driven navigation and LLM-generated scaffolding. The workflow is initiated by an open narrative entry, which grounds the subsequent interactions (Figure 1).
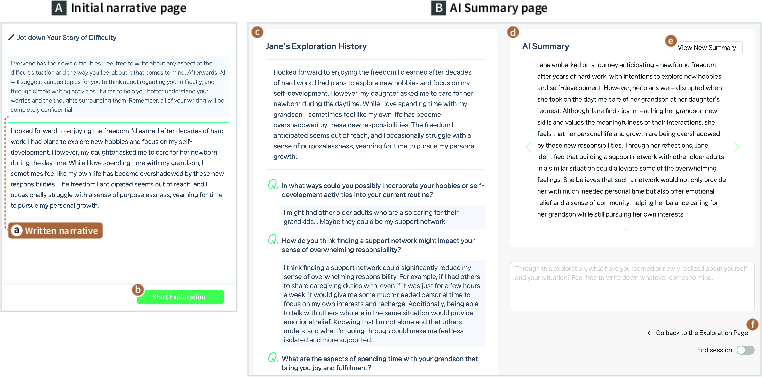
Figure 1: The Initial Narrative and AI Summary interfaces emphasize user-initiated expressive entry, history review, and externalized, LLM-generated summarization.
User interaction then branches along two tightly-coupled axes: thematic breadth and inquiry depth. The system incrementally synthesizes:
- Themes: Generated via LLMs using chain-of-thought prompting; alternatives and paraphrases are included, with explicit rationales and backward linkage to source input.
- Questions: For any theme, multiple Socratic questions are instantiated. Each question aims to elicit critical examination and metacognitive insight, not just rote elaboration.
- Keywords and Comments: Lightweight cognitive scaffolding (keywords) or contextually-aware tips, validation, or insights (comments) are LLM-generated on demand but exposed solely at user request, minimizing prescriptive imposition.
- Summaries: A reverse-propagating synthesis collapses narrative, theme, and Q/A structure into an external perspective, promoting objective self-revision.
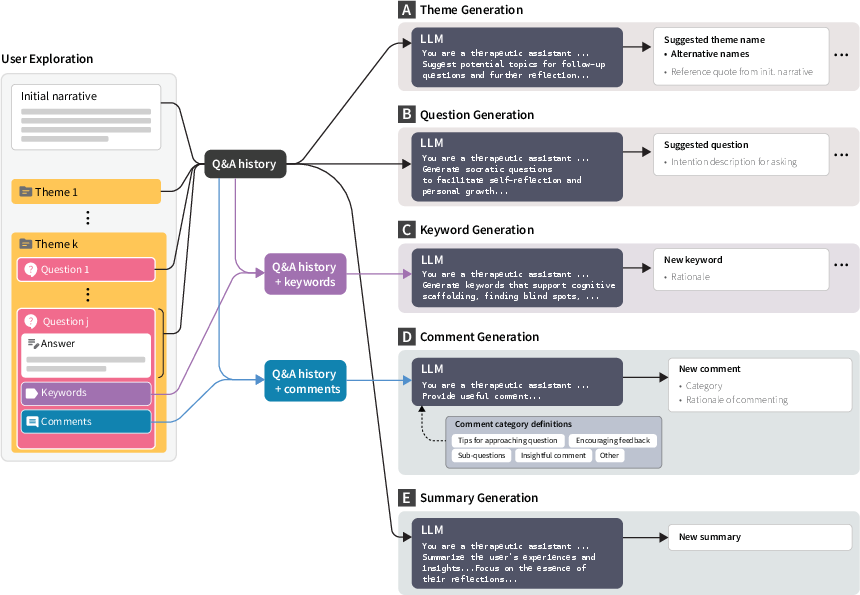
Figure 2: Five parallel, chain-of-thought LLM pipelines generate dynamic scaffolds: themes, Socratic questions, keywords, adaptive comments, and objective session summaries, all constrained by user context and history.
Technically, all guidance is chained through XML-wrapped context blocks, anchored in both initial and ongoing user input—maximizing personalization while avoiding the pathologies of de novo content imposition.
Empirical Results: Engagement, Agency, and Interactive Trajectories
A between-subjects exploratory study (N=19; broad demographic and occupational diversity; Korean language) rigorously instrumented user trajectories across all system affordances with synchronous interviews and psychometric self-efficacy/agency evaluation.
Engagement Dynamics: Participants showed idiosyncratic but consistently substantive engagement along both thematic and inquiry axes. Average narrative length was 233 syllables, total Q/A response 746 syllables, with 4.89 themes and 11.47 questions explored on average.
Interaction Chronology: The temporal allocation analysis (Figure 3) reveals heterogeneity: some users emphasize narrative initialization, others iterative Q/A, and a significant subset cycle between exploration and summary review phases.
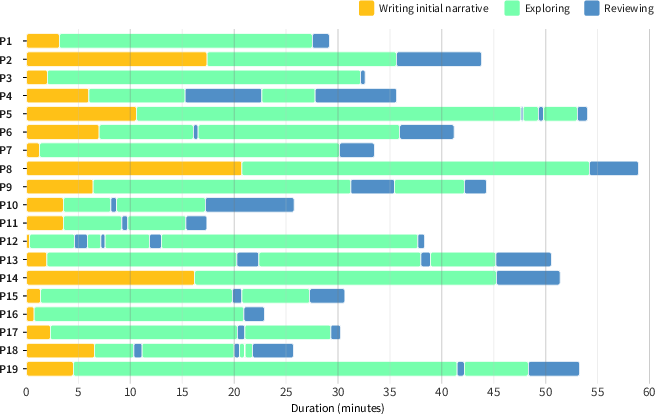
Figure 3: Participant engagement timelines highlight individualized allocation to narrative creation (yellow), active exploration (cyan), and reflective summarization (blue).
Micro-Analysis of Exploration Patterns: Qualitative event-flow reconstruction of five archetype participants demonstrates flexible traversals (Figure 4): some cluster numerous questions per theme, others cross-cut, some maximize scaffolding feature usage. This supports robust claims regarding user-driven interaction granularity and pacing.
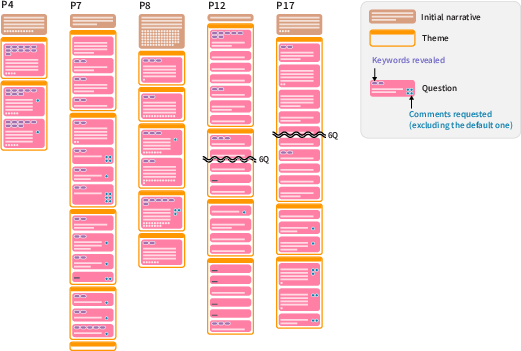
Figure 4: Participant-specific exploration traces visualize diversity in theme selection, threading depth, keyword and comment utility, and written verbosity.
Agency Shift and Theoretical Impact: Pathway subscale analysis (Self-Agency metric) documents a significant upward shift (Δmean=2.63, Cohen’s d=0.66, p<0.012). Qualitative accounts corroborate that this increase is not merely interactional but reflective—users report both moment-to-moment control over process and a heightened sense of mastery over their underlying challenges.
Theoretical and Practical Implications
ExploreSelf demonstrates that combining explicit, user-led navigation with finely-tunable, context-sensitive LLM guidance produces qualitatively distinct reflective experiences. Key implications:
- Granular User Agency in Cognitive Domains: Adaptive guidance can enhance, not erode, both process agency and metacognitive self-efficacy if scaffolding remains selectively exposed and user-steerable.
- Iterative and Objectifying Externalization: AI-generated summaries catalyze higher-order reflections, facilitating comparison between self-internalized and externalized perspectives. This is theoretically congruent with narrative self-construction and cognitive reappraisal models.
- Dynamic Emotional Regulation: Choice architecture in query selection enables users to regulate emotional overhead, selectively engaging or deferring aversive topics, contributing to lossless yet psychologically safe exploration.
Systemic implications extend to the design of LLM-driven interventions for therapy, coaching, and self-directed cognitive/emotional tasks. Modularization of chain-of-thought models and flexible persona/intent customization could generalize to further autonomy-supporting HCI applications.
Limitations and Directions for Future Research
The study’s short-term, laboratory-within-field constraints limit longitudinal ecological generalizability. Multi-session deployments would require memory-efficient episodic retrieval, semantic zooming for scalable context management, and further disambiguation of cultural biases in LLMs. Automatic detection of stagnation, rumination, and optimal intervention timing remain open methodological frontiers.
Conclusion
ExploreSelf establishes a technically and empirically robust framework for LLM-powered user-driven exploration of personal challenges. Its hybridized pipeline of agentic navigation and targeted adaptive scaffolding not only augments interactional control but substantively advances self-reflective agency—suggesting a blueprint for next-generation AI-augmented cognitive support tools in mental well-being and beyond.