Reflection Before Action: Designing a Framework for Quantifying Thought Patterns for Increased Self-awareness in Personal Decision Making
Abstract: When making significant life decisions, people increasingly turn to conversational AI tools, such as LLMs. However, LLMs often steer users toward solutions, limiting metacognitive awareness of their own decision-making. In this paper, we shift the focus in decision support from solution-orientation to reflective activity, coining the term pre-decision reflection (PDR). We introduce PROBE, the first framework that assesses pre-decision reflections along two dimensions: breadth (diversity of thought categories) and depth (elaborateness of reasoning). Coder agreement demonstrates PROBE's reliability in capturing how people engage in pre-decision reflection. Our study reveals substantial heterogeneity across participants and shows that people perceived their unassisted reflections as deeper and broader than PROBE's measures. By surfacing hidden thought patterns, PROBE opens opportunities for technologies that foster self-awareness and strengthen people's agency in choosing which thought patterns to rely on in decision-making.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about helping people think better before making big life choices, like whether to move, buy a house, have children, or change jobs. Instead of jumping straight to advice or answers (like many chatbots do), the authors want to boost self-awareness: to help people notice how they are thinking. They introduce a new idea called pre-decision reflection (PDR) and a tool called PROBE that measures how someone is reflecting before they decide.
Think of it like this: before choosing a path in a maze, the paper helps you notice which parts of the maze you’re paying attention to and how carefully you’re looking, so you can choose more confidently.
What questions were the researchers asking?
In simple terms, the paper tries to answer:
- How can we help people notice their own thought patterns before they make a big decision?
- Can we measure those thought patterns in a fair, reliable way?
- What kinds of thinking do people actually use before deciding—and where are the blind spots?
- Do people think they reflect more deeply and broadly than they really do?
How did they study it?
A new idea: Pre-Decision Reflection (PDR)
PDR means pausing to think about your situation and options before you decide—without rushing to a solution. It’s not about judging past actions, and it’s not about getting advice; it’s about noticing your beliefs, feelings, plans, worries, and more, right now.
The PROBE framework: measuring thought patterns
PROBE looks at two things in someone’s reflection:
- Breadth: How many different “angles” or categories of thought they used (like changing camera angles on a scene).
- Depth: How much they explained or explored each thought (like zooming in to see details, reasons, and examples).
To make this clear, PROBE uses seven easy-to-spot thought categories:
| PROBE category | What it means in everyday words |
|---|---|
| Belief | Your opinions or assumptions (e.g., “Renting is throwing money away.”) |
| Awareness of Difficulties | Noticing obstacles or risks (e.g., “Childcare is expensive.”) |
| Experience | Bringing in past events or things you’ve seen (yours or others’) |
| Feeling | Naming emotions (e.g., “I feel anxious but excited.”) |
| Intention | Stating a plan or what you’re leaning toward |
| Insight | Making a new connection that helps you understand better |
| Alternative Perspective | Considering how others might see it or a viewpoint different from your own |
Breadth is about how many of these you use. Depth is about how well you explain each thought—do you give reasons, examples, or “how/why” details, not just quick statements?
Who took part and what did they do?
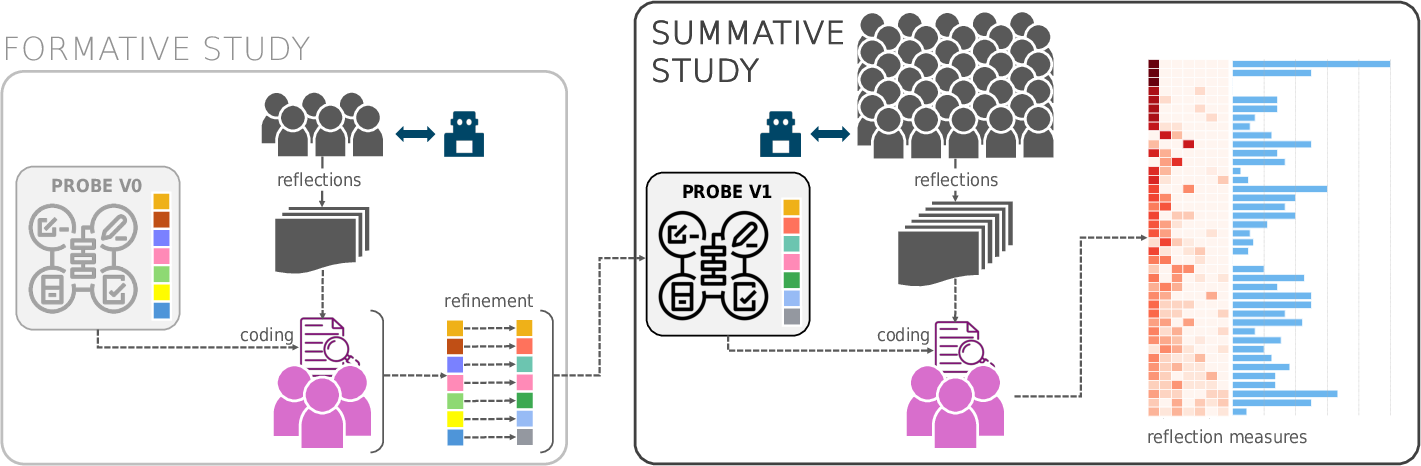
- 46 adults were recruited online. A small group (6) helped refine the tool; a larger group (40) tested it.
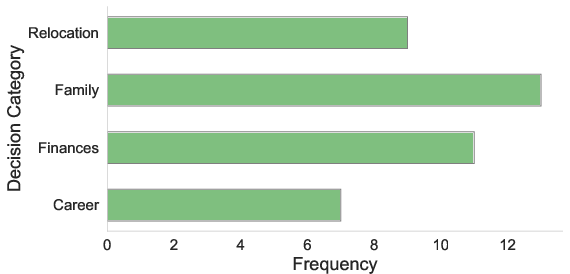
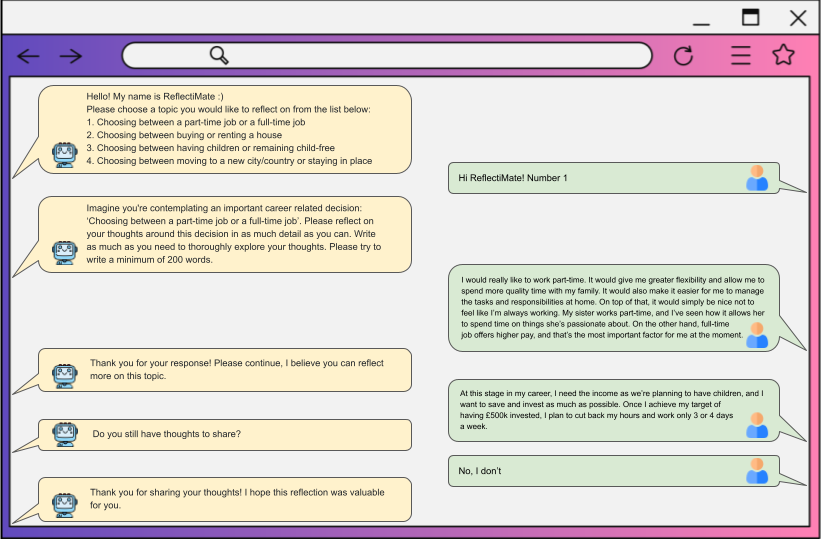
- Each person picked a big life decision to think about (career, family, finances, relocation).
- They typed their reflections in a simple, passive chat with a bot that didn’t give advice—it just encouraged them to keep talking.
- Afterward, they rated how broad and deep they thought their reflection was.
How did the researchers check the measurements?
Several trained coders read the reflections and tagged each sentence using the seven PROBE categories, and marked whether each thought was elaborated (depth) or not. Different coders agreed with each other a lot, which shows the method is reliable.
What did they find—and why does it matter?
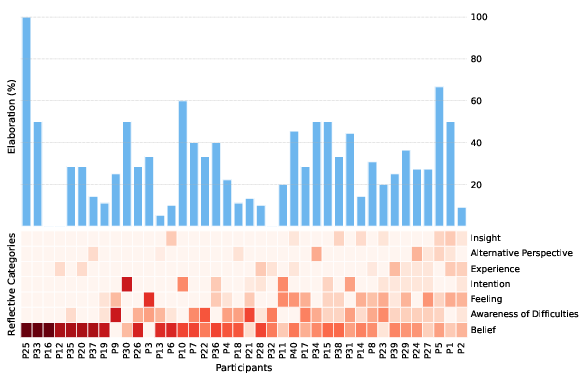
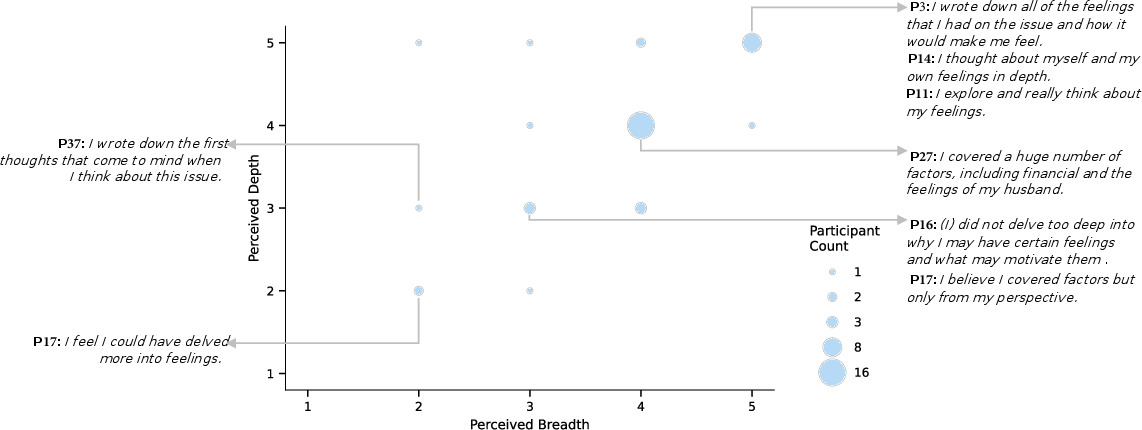
- People’s thought patterns were very different from each other. Some used many categories (good breadth), others used only one or two. Some explained their thinking well (good depth), but many did not.
- Most people leaned heavily on Beliefs and Awareness of Difficulties (opinions and obstacles).
- Few people used Alternative Perspectives (other viewpoints) or Insights (new connections). These two seemed hardest—and might be where support is most needed.
- Depth was often low. About 80% of people did not elaborate on most of their thoughts. In other words, many statements were quick and surface-level (e.g., “I think X”) without reasons or examples.
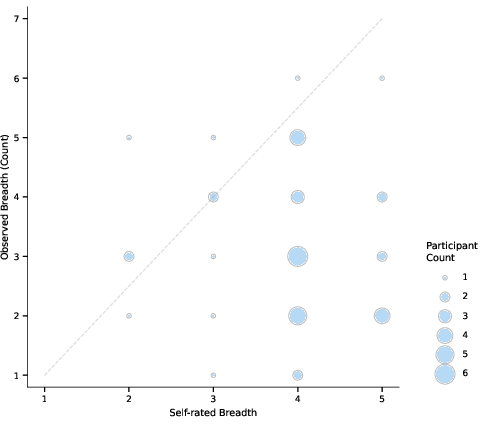
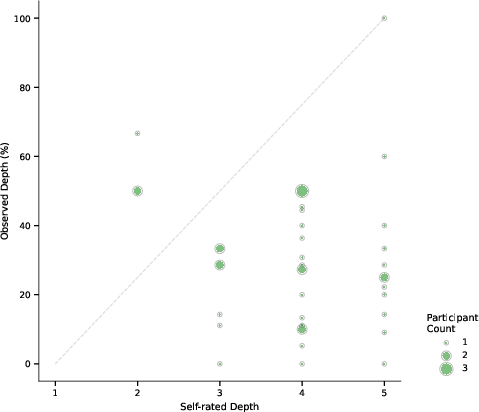
- People thought they reflected better than they actually did. Self-ratings of breadth and depth were generally high—even when the measured breadth/depth was modest. This suggests we’re not always great at judging our own thinking.
- Most participants (about 80%) said they would like a helpful assistant to guide their reflection—not to give answers, but to ask good questions, point out blind spots, and encourage deeper thinking.
Why it matters: Noticing how you think before deciding can prevent narrow, rushed choices. It can also protect your independence: instead of a chatbot telling you what to do, you become more aware and in control of your own decision-making.
What could this change in the real world?
- Better decision tools: PROBE can power future apps or chatbots that don’t push advice but instead mirror your thinking back to you—showing which thought categories you’re using (and missing), and nudging you to add depth where needed.
- Stronger self-awareness: By seeing your “thinking map” (your breadth and depth across categories), you can choose which patterns to rely on and which to strengthen.
- Safer AI conversations: Many AI systems rush to give answers. This work encourages AI that helps you reflect first—leading to decisions that fit your values and situation.
In short: The paper introduces a clear, reliable way to measure how people think before deciding. It shows where people often get stuck and offers a path to more thoughtful, confident choices—by reflecting before acting.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces PROBE and shows it can be reliably applied to short, written pre-decision reflections, but it leaves several issues unresolved that future work could address:
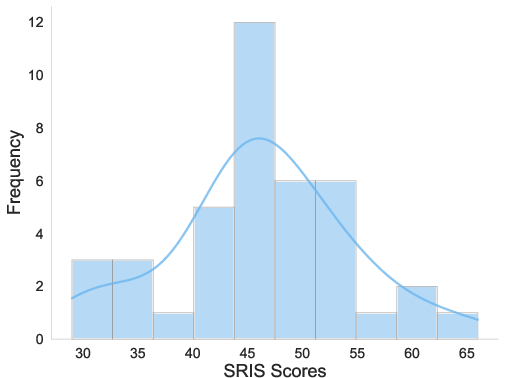
- Construct validity of PROBE’s measures is untested: no evidence of convergent/discriminant validity with existing instruments (e.g., SRIS, TSRI, RRTT), no factor structure analysis, and no test–retest reliability to establish stability over time.
- Predictive validity is unknown: it remains untested whether higher PROBE breadth/depth predicts downstream outcomes (e.g., decision quality, confidence, satisfaction, reduced regret, well-being, agency).
- Ecological validity is limited: reflections were one-off, brief (median ≈15 minutes), and collected in an online study; it is unclear how PROBE performs in real, high-stakes, longitudinal decision processes.
- Generalizability of findings is uncertain: the Prolific sample, decision topics, and English-language setting may not represent diverse cultures, languages, ages, education levels, or clinical populations.
- Topic effects are unexplored: whether decision domain (e.g., finances vs. family) systematically shapes category use and elaboration was not analyzed or controlled.
- Within-person stability is unknown: how consistent an individual’s PROBE profile is across different decisions or across time remains untested.
- Length/verbosity confounds are not fully controlled: frequency-based breadth may be inflated by longer texts, and % elaboration may penalize prolific thinkers; normalization strategies and sensitivity analyses are needed.
- Depth is operationalized as binary elaboration at the thought level; more nuanced rubrics (multi-level depth scales) and cross-rater calibration for depth quality are not developed.
- Per-category reliability is not reported: overall κ values are substantial, but reliability for each category (especially “Insight” and “Alternative Perspective”) and for depth judgments is unknown.
- Category set completeness is unvalidated: potential missing aspects (e.g., values/identity, trade-off reasoning, risk/uncertainty, norms/constraints, scenario generation, information gaps) are not examined.
- Boundary clarity between categories (e.g., “Experience” vs. “Alternative Perspective” when referencing others) needs refinement to reduce coder ambiguity.
- Miscalibration between perceived and measured breadth/depth is described but not modeled: predictors of overconfidence and interventions to improve metacognitive calibration are untested.
- Relationship to trait reflectiveness (SRIS) is not analyzed: whether SRIS predicts PROBE breadth/depth or profile types remains an open question.
- Medium effects are untested: how PROBE scores vary by modality (chat vs. free-form journaling vs. voice) or by the presence of social context (e.g., therapist, peer) is unknown.
- Agent influence is not characterized: the passive agent’s prompts may shape reflection, but there is no comparison to free writing, alternative prompt styles, or varying levels of proactivity.
- Socratic interventions are not evaluated: which prompt strategies (e.g., counterfactuals, perspective-taking prompts) most effectively increase “Alternative Perspective” and “Insight” without steering decisions is unknown.
- Integration with LLMs is untested: how to align LLMs to promote reflection (rather than provide solutions), and whether PROBE-guided, adaptive prompting improves breadth/depth safely, remains open.
- Personalization strategies are undeveloped: how to tailor interventions to specific PROBE profiles (e.g., high depth/low breadth vs. high breadth/low depth) and measure their efficacy is not addressed.
- Risks of maladaptive rumination are unmeasured: guardrails to prevent harm (e.g., increased anxiety, perseveration) and ways to detect/mitigate rumination during PDR are not specified.
- Joint decision-making is not considered: applying PROBE to dyadic or group contexts (e.g., partners deciding about children or relocation) and capturing inter-perspective dynamics remains unexplored.
- Cross-cultural and multilingual validity is untested: measurement invariance across cultures/languages and adaptations for non-English contexts are not established.
- Automation/scalability is absent: no NLP models are provided to automatically detect categories and elaboration; annotated datasets, coding manuals, and benchmarks are not released.
- Ethical and privacy implications are under-specified: protocols for handling sensitive reflective data (on-device processing, differential privacy, user control, consent, and explainability) need to be designed and evaluated.
- Downstream impact of PROBE-informed feedback is unknown: whether presenting users with their thought profile actually increases self-awareness, metacognitive regulation, and prudent decision behaviors has not been tested.
- Decision-type adaptivity is unclear: guidelines for what constitutes “sufficient” breadth/depth given decision characteristics (irreversibility, stakes, time pressure) are not proposed or validated.
- Premature closure is unexamined: whether high “Intention” early in PDR predicts narrowed exploration and how to counteract premature commitment is unknown.
- Links to cognitive biases are not operationalized: how PROBE signals (e.g., low “Alternative Perspective”) map to specific biases (bounded awareness, confirmation bias) and can trigger targeted de-biasing is not established.
- Longitudinal outcomes are absent: there is no follow-up to compare PROBE profiles with actual choices made, subsequent adjustments, or later satisfaction/regret months after reflection.
Practical Applications
Immediate Applications
The following applications can be deployed now using the PROBE framework’s categories (Belief, Awareness of Difficulties, Experience, Feeling, Intention, Insight, Alternative Perspective), frequency-based breadth, and elaboration-based depth measures, alongside simple conversational and journaling workflows.
- PROBE-guided “reflection-first” chat interactions in consumer AI assistants
- Sectors: software, education, healthcare, finance, daily life
- Tools/products/workflows: system prompts or custom GPTs that scaffold user reflections across the seven PROBE aspects before offering advice; lightweight UI badges showing breadth (covered categories) and depth (elaborated vs. non-elaborated thoughts)
- Assumptions/dependencies: LLMs can follow structured prompts; user consent and clarity about non-prescriptive support; high-stakes decisions require escalation to human professionals
- Structured worksheets/checklists for coaches, therapists, and counselors
- Sectors: healthcare (mental health), HR/career coaching, education (student advising)
- Tools/products/workflows: printable/interactive PROBE templates; session scripts that cue diversification (e.g., Alternative Perspective) and depth (prompting elaboration)
- Assumptions/dependencies: practitioner training to avoid inducing rumination; privacy and data handling practices; PROBE captures patterns, not outcomes or diagnoses
- Financial advisory intake for home-buy/rent decisions using PROBE
- Sectors: finance, real estate
- Tools/products/workflows: CRM plugins that capture clients’ beliefs, risk perceptions (Awareness of Difficulties), alternative options, and intentions prior to modeling scenarios
- Assumptions/dependencies: advisors avoid prescriptive bias; suitability screening for complex cases; cultural variability in financial norms
- HR portals for job-change and contract-type decisions (full-time vs. part-time)
- Sectors: HR, enterprise software
- Tools/products/workflows: pre-decision reflection modules embedded in employee self-service portals; dashboards surfacing overreliance on single aspects (e.g., Belief-only fixation)
- Assumptions/dependencies: confidentiality; opt-in participation; safeguards against managerial misuse of reflection data
- Journaling apps with PROBE tags and guided prompts
- Sectors: consumer software/wellness
- Tools/products/workflows: tag schema (e.g., Feeling, Insight) and prompt packs that nudge users to broaden categories and deepen reasoning; simple breadth/depth indicators per entry
- Assumptions/dependencies: minimal annotation burden; avoid promoting excessive rumination; respect for user privacy
- University and school advising for program choice and relocation decisions
- Sectors: education
- Tools/products/workflows: advising forms and chat flows that reveal narrow thought patterns (e.g., missing Alternative Perspectives); student-facing summaries of thought coverage
- Assumptions/dependencies: inclusive, culturally sensitive prompts; trained advisors; clear limits of the tool (not outcome recommendations)
- Team pre-mortem/reflection before strategic decisions
- Sectors: enterprise, product management
- Tools/products/workflows: meeting templates that enforce coverage of PROBE aspects (assumptions, risks, stakeholder perspectives) and capture elaboration; action items tied to gaps
- Assumptions/dependencies: psychological safety; moderation to balance depth with decision velocity
- Research instrumentation for metacognition studies
- Sectors: academia/HCI
- Tools/products/workflows: use PROBE as a coding scheme in studies; report breadth/depth profiles and inter-rater reliability; compare self-perception vs. measured patterns
- Assumptions/dependencies: coder training; awareness that PROBE evaluates thought patterns, not decision quality or outcomes
- “Reflection checklist” policy guidance for high-stakes consumer AI
- Sectors: policy/regulation, software
- Tools/products/workflows: voluntary developer guidelines that require reflection prompts before prescriptive outputs in domains like health, finance, and law
- Assumptions/dependencies: industry adoption; clear risk-tiering; warnings and referral pathways for complex or sensitive cases
Long-Term Applications
These applications require further research, scaling, automation, evaluation, and/or standards development to reach dependable deployment.
- Automated PROBE classifiers for breadth/depth detection in text
- Sectors: software/AI, academia
- Tools/products/workflows: NLP models trained on PROBE-coded corpora to detect categories and elaboration in real time; APIs that score and visualize user reflection patterns
- Assumptions/dependencies: high-quality labeled datasets, multilingual/cultural generalization, fairness audits, robustness to domain shifts
- Adaptive reflective agents that personalize prompts to user profiles
- Sectors: software/AI, wellness, education
- Tools/products/workflows: agents that diagnose overuse/underuse of PROBE aspects and dynamically steer conversation to diversify and deepen thought; RL objectives balancing reflection and user satisfaction
- Assumptions/dependencies: avoidance of manipulative steering; guardrails to prevent rumination; outcome evaluations (e.g., user agency, satisfaction, harm reduction)
- Clinical decision support that augments informed consent with PDR
- Sectors: healthcare
- Tools/products/workflows: patient-facing modules prior to choosing treatments, capturing feelings, risks, alternative perspectives; clinician dashboards highlighting where reflection needs scaffolding
- Assumptions/dependencies: regulatory clearance; integration with EHRs; evaluations of effect on comprehension, decisional conflict, and equity
- Reflection-aware AI standards and certification
- Sectors: policy/regulation, software
- Tools/products/workflows: standards bodies define minimum reflective scaffolding for high-stakes AI; certifications that audit whether systems promote reflection before advice
- Assumptions/dependencies: cross-stakeholder consensus; compliance incentives; clear scope limiting overreach and preserving user autonomy
- Curricular integration of metacognitive training with PROBE metrics
- Sectors: education
- Tools/products/workflows: K–12 and higher ed modules with dashboards tracking students’ breadth/depth over time; teacher development on facilitating reflection without bias
- Assumptions/dependencies: alignment with learning outcomes; safeguards against grading metacognition as performance; cultural adaptability
- Workplace analytics for leadership and risk management
- Sectors: enterprise, finance, energy
- Tools/products/workflows: reflection profiles (team/leader) tied to pre-mortems, scenario planning, and governance; aggregate analytics to reduce bounded awareness in critical decisions
- Assumptions/dependencies: strong privacy and ethics; avoid punitive uses; demonstrate value without adding undue process friction
- Civic deliberation platforms measuring diversity and depth of public input
- Sectors: policy/civic tech
- Tools/products/workflows: PROBE-based analytics of community comments to surface underrepresented perspectives and shallow reasoning; facilitation tools that expand thought coverage
- Assumptions/dependencies: transparent methods; mitigation of bias and moderation risks; inclusivity across languages and literacy levels
- Reflective layers in recommender and decision engines
- Sectors: consumer platforms, finance/credit, energy (tariff choices)
- Tools/products/workflows: pre-recommendation scaffolds prompting users to articulate beliefs, consider alternatives and risks; “reflection summaries” that inform subsequent model suggestions
- Assumptions/dependencies: careful UX to avoid friction and drop-off; evaluations of impact on outcomes and fairness; domain-specific compliance
- Longitudinal self-awareness tracking and mental health monitoring
- Sectors: healthcare/wellness, personal knowledge management
- Tools/products/workflows: personal knowledge graphs storing reflection patterns over time; alerts for unbalanced thought profiles (e.g., persistent risk focus or belief fixation)
- Assumptions/dependencies: strong consent and privacy; clinical validation; differentiation between healthy reflection and rumination
- Cross-language/cultural adaptations and domain specialization
- Sectors: global software, healthcare, finance, education
- Tools/products/workflows: localized PROBE taxonomies (e.g., culturally tuned categories, examples); domain-specific prompt libraries (e.g., oncology decisions, mortgage choices)
- Assumptions/dependencies: participatory design; ongoing validation across populations; maintenance of taxonomy drift
- RLHF and training objectives that reward reflection facilitation
- Sectors: AI research/development
- Tools/products/workflows: new instruction-tuning datasets and reward models that prefer “reflection-first” behaviors; benchmarks tracking breadth/depth improvements
- Assumptions/dependencies: measurable success criteria beyond user satisfaction; careful balance to prevent unhelpful verbosity; alignment with safety policies
- Enterprise risk committees using PROBE dashboards
- Sectors: finance, energy, aerospace, healthcare
- Tools/products/workflows: decision rooms with real-time reflection analytics during high-stakes reviews; alerts for narrow patterns (e.g., missing Alternative Perspectives)
- Assumptions/dependencies: integration with existing governance tools; training for facilitators; evidence that reflection improves decision quality without excessive delay
Notes on feasibility across applications:
- PROBE measures thought patterns (breadth and elaboration) rather than “correctness” of decisions; downstream outcome improvements should be evaluated empirically.
- Many applications benefit from human oversight to avoid oversteering and to manage risks of rumination, decision fatigue, or misplaced confidence.
- Ethical, privacy, and cultural considerations are central, especially when storing or analyzing reflective content and when deploying in high-stakes contexts.
Glossary
- Alternative Perspective: A PROBE category capturing thoughts that adopt viewpoints beyond the self. "Alternative Perspective. Originally labeled "Perspective", this category was renamed to "Alternative Perspective" to better reflect its intent: capturing thoughts that adopt perspectives beyond the self."
- Belief: A PROBE category for first-person opinions, assumptions, or convictions about the decision. "Belief. This category captures segments of reflection where the individual expresses personal opinions, assumptions, or convictions about the decision at hand."
- Bounded awareness: A cognitive limitation where individuals focus too narrowly and overlook important information. "One such limitation is bounded awareness~\cite{bounded1,bounded}, where individuals focus narrowly on a single category of thought, without realizing the restrictiveness of their perspective."
- Cohen’s κ: A statistic measuring inter-rater agreement for two coders, correcting for chance. "Cohenâs = .79 (substantial agreement) for the double-coded subset."
- Deliberation studies: A research area on structured reasoning and discussion that informs measures of elaboration. "We instead assessed the elaborateness of reasoning within each reflective aspect, drawing on concepts from deliberation studies \cite{Deliberation1}."
- Fleiss’ κ: A statistic measuring agreement among multiple coders, correcting for chance. "Fleissâ = .69 (substantial agreement) for the triple-coded subset, and Cohenâs = .79 (substantial agreement) for the double-coded subset."
- Formative study: An exploratory evaluation used to refine methods or frameworks before confirmatory testing. "The formative study served as an exploratory validation step to examine the applicability of adapted framework (PROBE v.0) (see Table \ref{table:CS_initial}) to the domain of pre-decision reflection (PDR)."
- Human-Computer Interaction (HCI): A field studying the design and use of interactive systems by people. "Schönâs framing of reflection \cite{schon} has been widely adopted in HCI research \cite{review1}."
- Human Research Ethics Committee (HREC): An institutional body that reviews studies for ethical compliance. "with ethics approval obtained from our universityâs Human Research Ethics Committee (HREC)."
- Inception annotation platform: A specialized tool for annotating text data used in qualitative coding. "They independently coded the six reflections using the adapted categories in the Inception annotation platform \cite{inception};"
- Inter-coder reliability: The degree of agreement among multiple coders applying the same coding scheme. "Inter-coder reliability was assessed using standard measures: Fleissâ = .69 (substantial agreement) for the triple-coded subset, and Cohenâs = .79 (substantial agreement) for the double-coded subset."
- LLMs: AI systems trained on vast text corpora to generate and understand language. "When making significant life decisions, people increasingly turn to conversational AI tools, such as LLMs."
- Likert scale: A psychometric response scale (e.g., 1–5) used to measure attitudes or perceptions. "participantsâ self-rated breadth and depth of reflection, collected via a post-questionnaire on a 5-point Likert scale, showed very little variation"
- Metacognitive awareness: Conscious understanding of one’s own thinking and decision processes. "However, LLMs often steer users toward solutions, limiting metacognitive awareness of their own decision-making."
- Metacognitive knowledge: Knowledge about one’s cognitive processes, strategies, and when to apply them. "Recognizing oneâs patterns of thoughts during decision making can foster metacognitive knowledge \cite{flavell1979, schraw1998, lai2011}, as it involves understanding how one thinks and reasons."
- Metacognitive regulation: The monitoring and control of one’s thinking to improve reasoning or learning. "Active use of this awareness can promote metacognitive regulation \cite{schraw1998, lai2011}, facilitating deeper pre-decision reflection and more deliberate decisions."
- Personal informatics systems: Technologies that help individuals collect and reflect on personal data to gain insights. "For example, personal informatics systems provide individuals with insights into their past behaviors by allowing them to review personal data \cite{PIS}, such as sleep patterns \cite{sleeptight}, thereby facilitating reflection-on-action."
- Pre-Decision Reflection (PDR): Reflective thinking performed before making a significant choice, focusing on one’s context and thoughts. "We introduce the term Pre-Decision Reflection (PDR) to address the above challenges and knowledge gaps, and develop a framework for assessing PDR"
- PROBE: The paper’s framework that evaluates PDR along breadth (diversity) and depth (elaboration). "We introduce PROBE, the first framework that assesses pre-decision reflections along two dimensions: breadth (diversity of thought categories) and depth (elaborateness of reasoning)."
- Reflection-for-action: Reflection oriented toward informing future decisions and actions. "This type of reflection is sometimes referred to as reflection-for-action \cite{killion}, to show forward-looking orientation of the outcome of the reflection."
- Reflection-in-action: Reflection occurring during an activity to adjust decisions in real time. "Reflection-in-action refers to the process of reflecting during task execution, allowing individuals to evaluate the situation and adjust decisions in real time \cite{reflection-in-action}."
- Reflection-on-action: Retrospective reflection after an activity to analyze and learn from it. "Reflection-on-action, in contrast, is a post hoc process that enables individuals to reconstruct and analyze past events."
- Reinforcement Learning from Human Feedback (RLHF): A training method where models learn policies guided by human preference signals. "The optimization of LLMs through RLHF \cite{ouyang2022training} rewards helpfulness and user satisfaction, resulting in a tendency to produce solution-centric responses."
- Reflection, Rumination, and Thought in Technology (RRTT) scale: An instrument to measure reflection- and rumination-related processes in tech contexts. "the Reflection, Rumination, and Thought in Technology (RRTT) scale \cite{RRTscale} in \citet{yin2025travelgalleria}."
- Self-Reflection and Insight Scale (SRIS): A psychometric scale that measures individuals’ tendencies toward self-reflection and insight. "measured beforehand in the pre-questionnaire using the Self-Reflection and Insight Scale (SRIS)."
- Summative study: A confirmatory evaluation conducted after refinement to assess reliability and effectiveness. "The summative study served as a confirmatory evaluation of PROBE."
- System Usability Scale (SUS): A standardized questionnaire for assessing perceived usability of systems. "using generic measures such as the System Usability Scale (SUS) \cite{SUS} in \citet{Grayscale} and \citet{participatory}"
- Technology-Supported Reflection Inventory (TSRI): A survey instrument for assessing technology’s support for reflection. "or with specialized instruments designed to assess reflection support, such as the Technology-Supported Reflection Inventory (TSRI) \cite{TSRI} in \citet{selvreflect}"
Collections
Sign up for free to add this paper to one or more collections.