- The paper introduces a novel CKA-based pruning method that optimizes neural network size by removing redundant layers.
- It employs a three-phase process—analysis, optimization, and recovery—to ensure minimal accuracy loss during pruning.
- Experimental results show up to 50% reduction in model parameters for transformer models, enhancing efficiency and integration with methods like Wanda.
Introduction
The paper introduces MPruner, a novel pruning technique designed to optimize the size of neural networks by leveraging Centered Kernel Alignment (CKA) similarity metrics to inform layer pruning decisions. The crux of the methodology involves multi-layer cluster-wise analysis that identifies and prunes redundant layers based on their global information contribution to the network's functionality. This strategy is driven by the need to reduce the over-parametrization in neural models, especially in transformer-based architectures, without inducing accuracy losses.
Methodology
MPruner comprises three distinct phases:
- Analysis Stage: The model is examined to gather multi-layer cluster-wise information using CKA values, which measure inter-layer similarity.
- Optimization Stage: Layers deemed redundant, based on their CKA similarity, are removed in this phase, utilizing a defined pruning granularity.
- Recovery Stage: The pruned model undergoes retraining to consolidate any accuracy losses incurred during pruning.
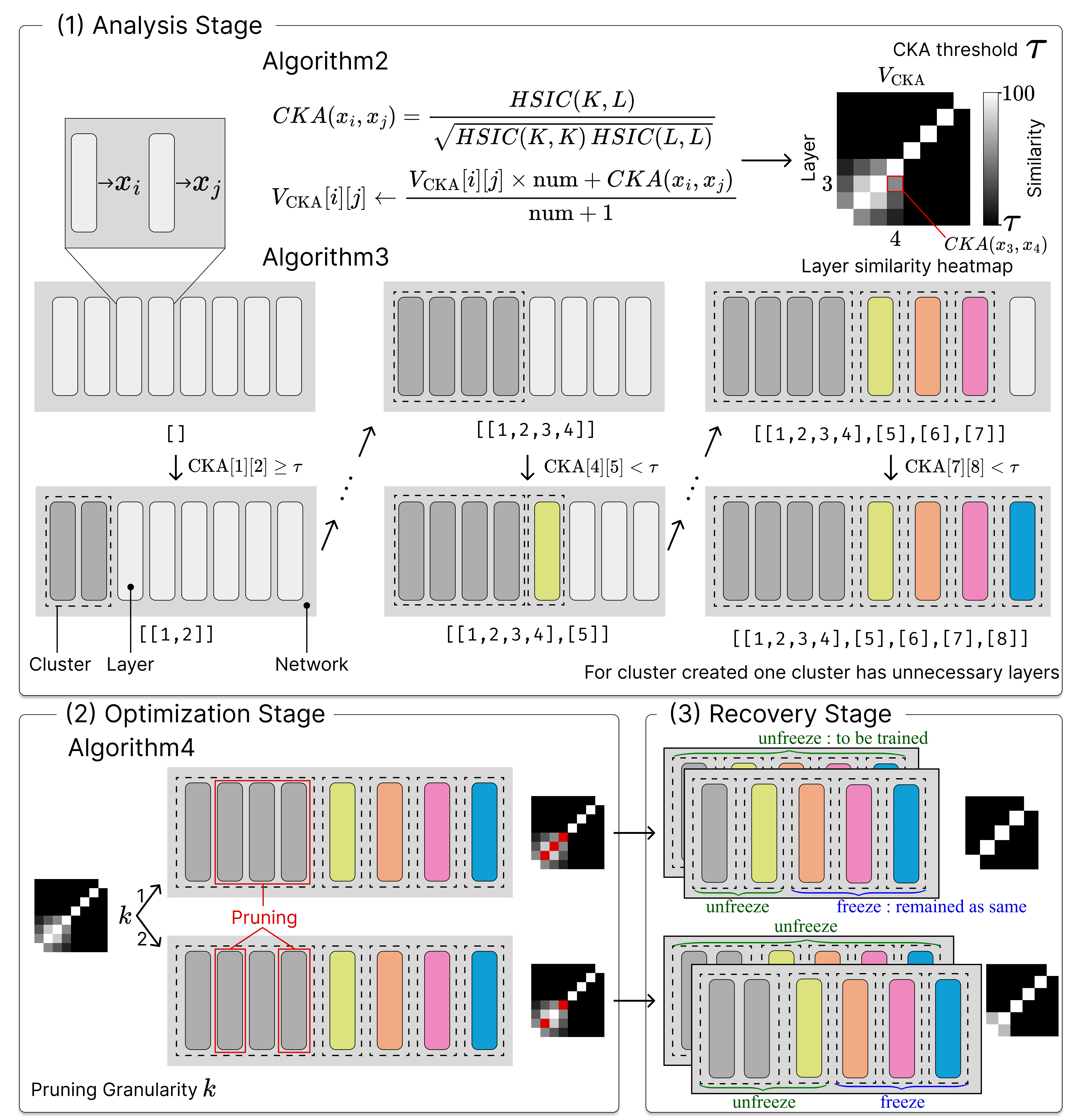
Figure 1: Three Phases of MPruner demonstrating the layered approach towards pruning using CKA metrics and retraining strategy.
The main algorithm iteratively calculates CKA scores between layers, selects clusters for pruning, and adjusts its strategy based on performance thresholds. This iterative process stops when no more layers can be pruned safely, ensuring minimal impact on model accuracy.
Experimental Results
The paper reports extensive testing of MPruner across various architectures, highlighting its versatility and efficiency:
- Transformer Models: Applied to both BERT and T5-based models, MPruner successfully reduced model sizes by up to 50%, demonstrating substantial parameter reductions with no significant accuracy losses. For instance, experiments on BERT for the Dair AI Emotion dataset showed a halved number of encoder layers while maintaining accuracy at 92% or higher.
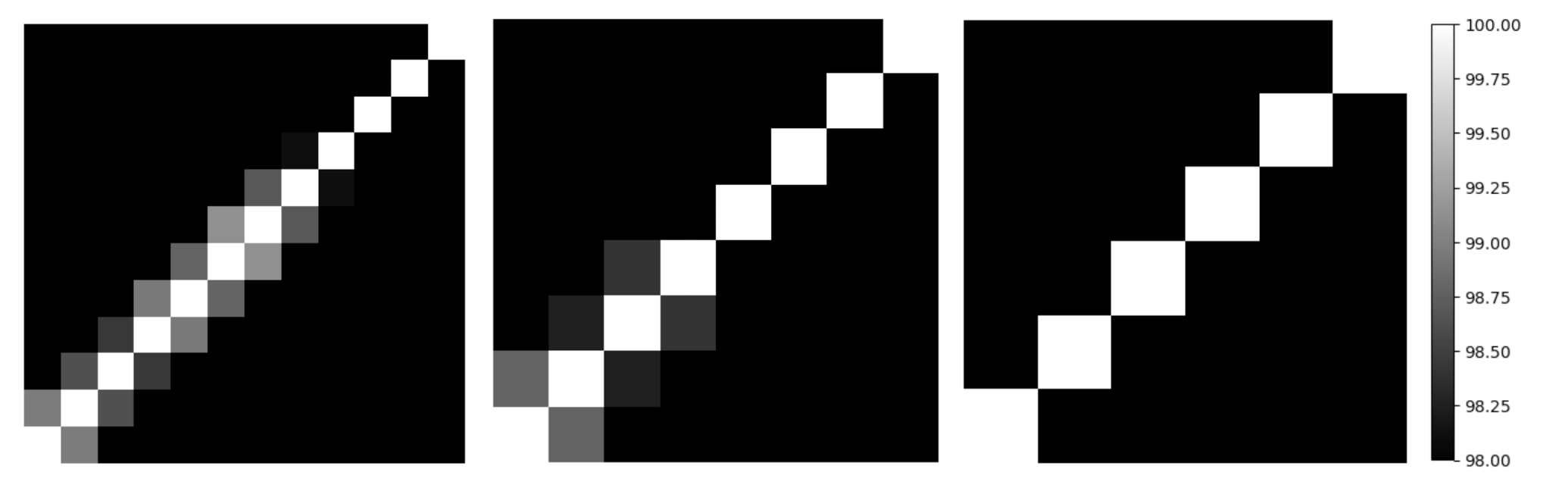

Figure 2: Clustering Heatmaps for Bert, illustrating the iterative pruning process with CKA similarity outcomes.
- CNN Models: The application on ResNet variants showed that while CNNs are more sensitive to pruning, MPruner still achieved effective size reductions. ResNet50 and ResNet152 experiments indicated that excessive pruning could lead to noticeable accuracy drops, but adjustments in granularity helped mitigate this effect.
- Integration Capability: MPruner’s potential to augment other pruning methods like Wanda was demonstrated, showing improvements in inference times and further parameter reductions when layers are pruned using MPruner first.
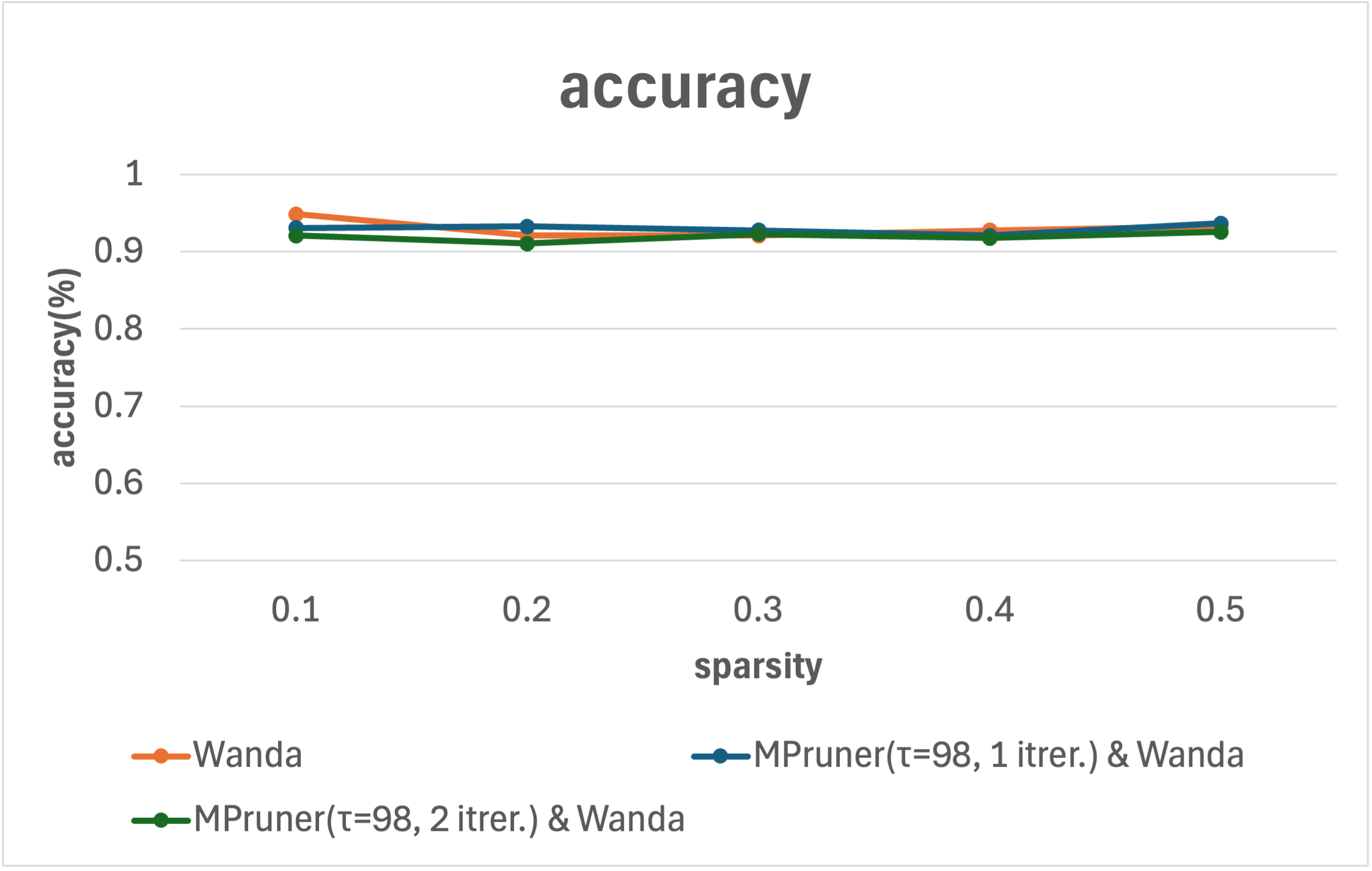
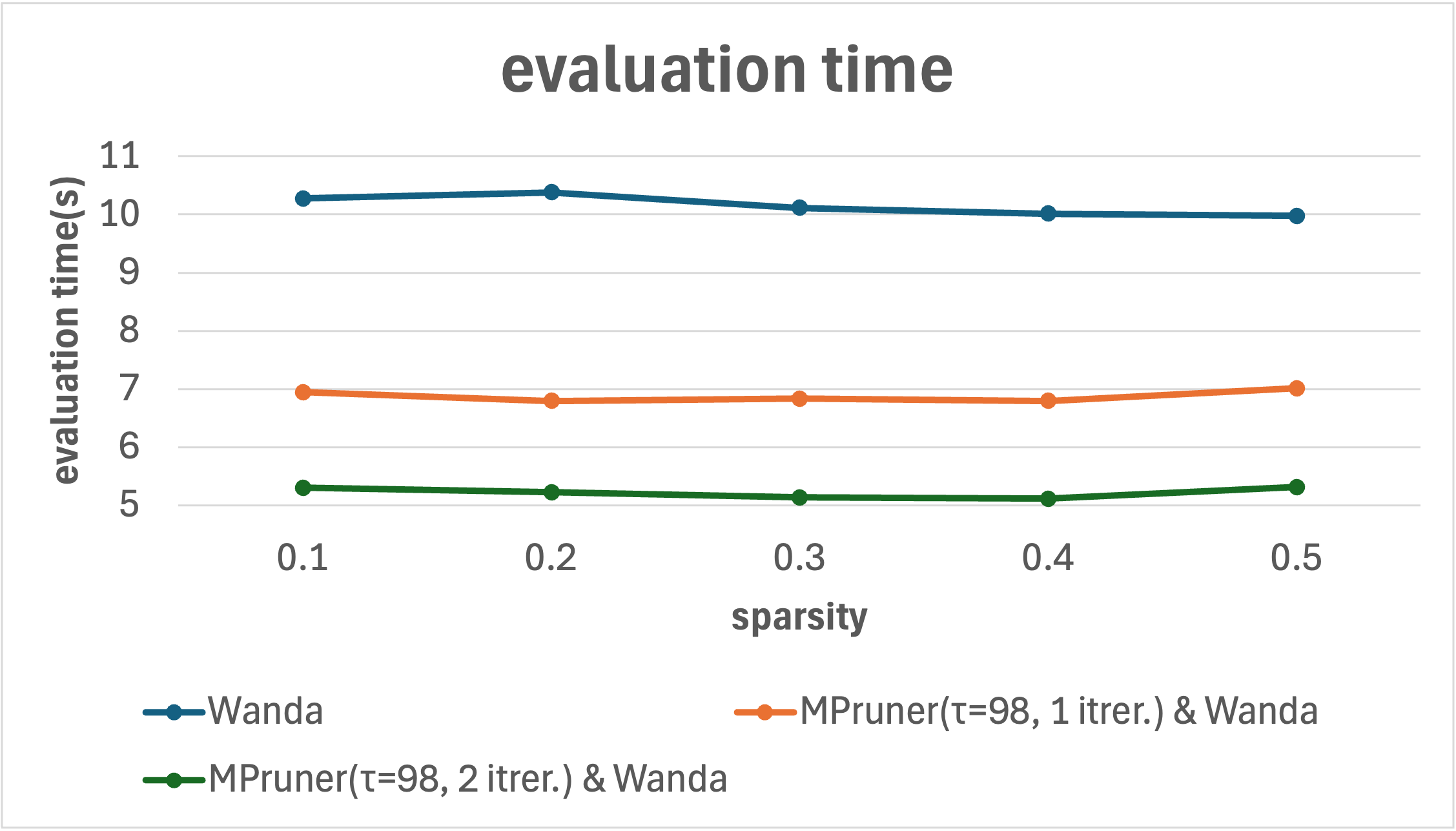
Figure 3: Result of Wanda, and Integration of Wanda and MPruner showcasing improvements in performance metrics.
Discussion and Implications
MPruner addresses the challenge of over-parametrization by offering a mathematically grounded methodology for pruning, setting it apart from previous techniques that often rely on local layer evaluations. Its reliance on CKA similarity ensures that layer reductions are backed by rigorous similarity evaluations, providing a balance between efficiency and functionality.
Conclusion
MPruner exemplifies an advanced approach to optimizing neural networks, particularly advantageous for transformer models. The integration of CKA metrics ensures a mathematically robust framework for pruning, capable of significant model size reductions with minimal accuracy trade-offs. Future explorations may include extending MPruner’s methodologies to larger models like GPT and further integrations with other NAS algorithms to enhance its utility and scalability in various AI applications.

