- The paper proposes contextual pruning to shrink LLMs while retaining core, domain-specific functionalities.
- It details targeted pruning strategies for linear, activation, and embedding layers using normalized L1-norm and token frequency metrics.
- Evaluations with perplexity and MCQ tests demonstrate significant size reduction with maintained or improved task performance.
Mini-GPTs: Efficient LLMs through Contextual Pruning
The paper "Mini-GPTs: Efficient LLMs through Contextual Pruning" proposes a method to reduce the size of LLMs by applying contextual pruning. This technique focuses on retaining core functionalities of models like Phi-1.5 while significantly decreasing their computational demands, thus maintaining efficiency and domain-specific performance.
Introduction and Motivation
The paper addresses the significant computational and environmental costs associated with LLMs. Model pruning, a well-explored area in model optimization, serves as the foundation for this research. Contextual pruning is a targeted approach that removes non-essential weights from a network, focusing on domain-specific needs like law, healthcare, and finance. This contrasts with broader training datasets, which often include redundant information for specialized applications (Figure 1).
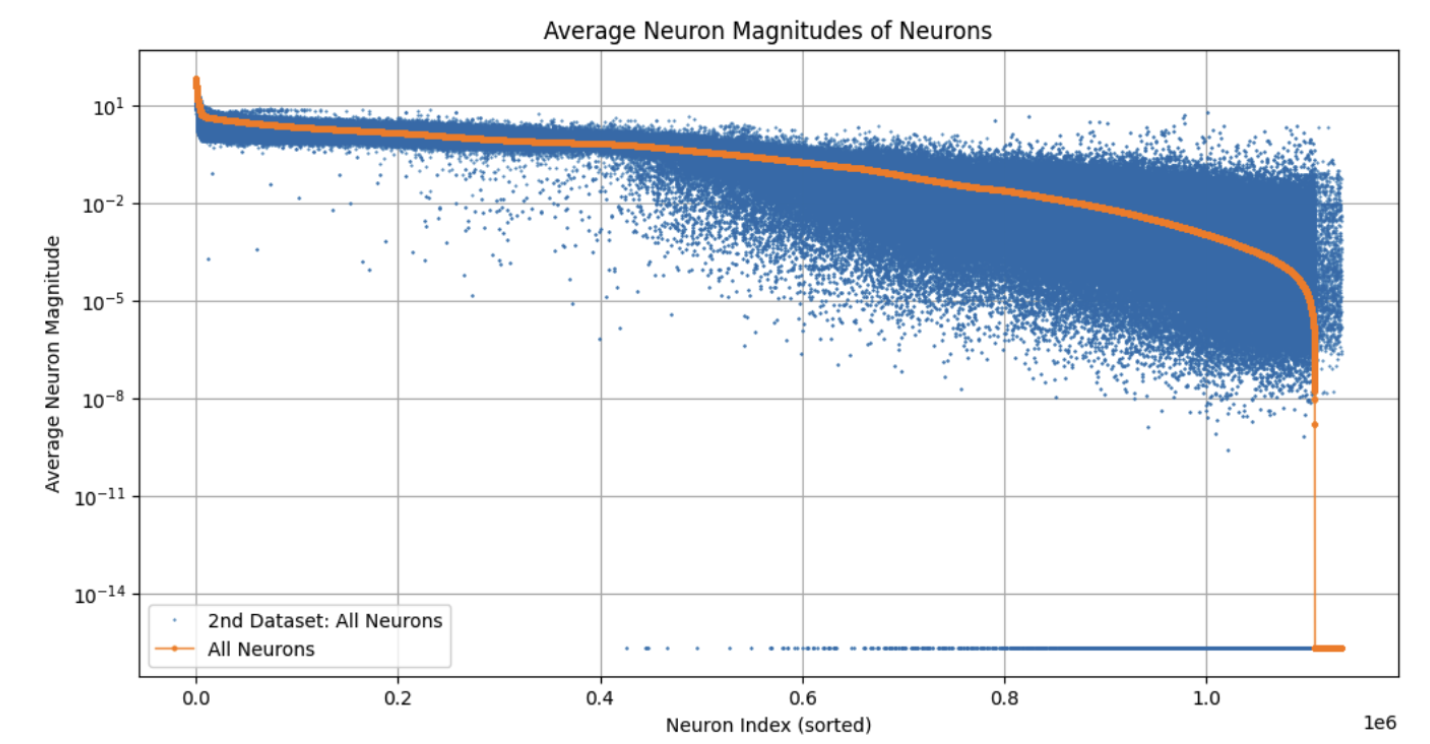
Figure 1: Comparison between magnitudes of neurons between skyrim and healthcare domains.
Methodology
Data Collection and Model Selection
The research utilizes datasets from diverse domains to evaluate pruning impacts. Selected models include GPT-like architectures such as Phi-1.5, Opt-1.3, and Llama-1.3. These models are robust in various NLP tasks and come with pre-configured BPE tokenizers in HuggingFace, contributing to their widespread use.
Contextual Pruning Techniques
Contextual pruning was applied primarily to linear layers, activation layers, and embeddings, each targeting specific model components.
Linear Layer Pruning
The linear layers are pruned by analyzing neuron outputs and calculating the normalized L1-norm of each neuron for dataset-specific pruning (Figure 2). This method identifies underutilized neurons across datasets and enables targeted pruning.
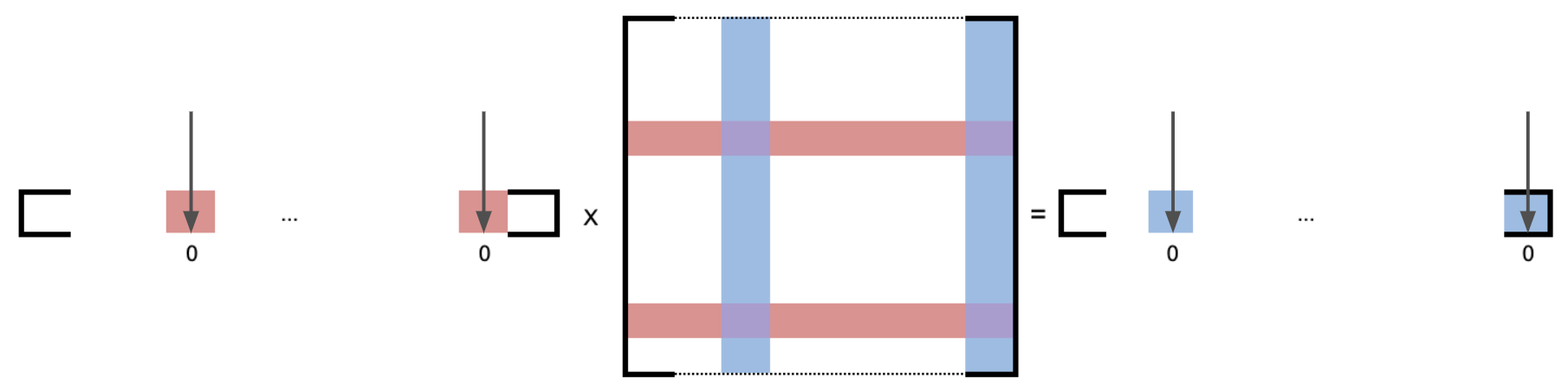
Figure 2: Linear Layer Pruning.
Activation Layer Pruning
For activation layers, the method only considers outputs to determine non-essential neurons. Similar to linear layers, if a neuron’s normalized L1-norm is below the threshold, it is pruned from the prior layer's transpose weight matrix (Figure 3).
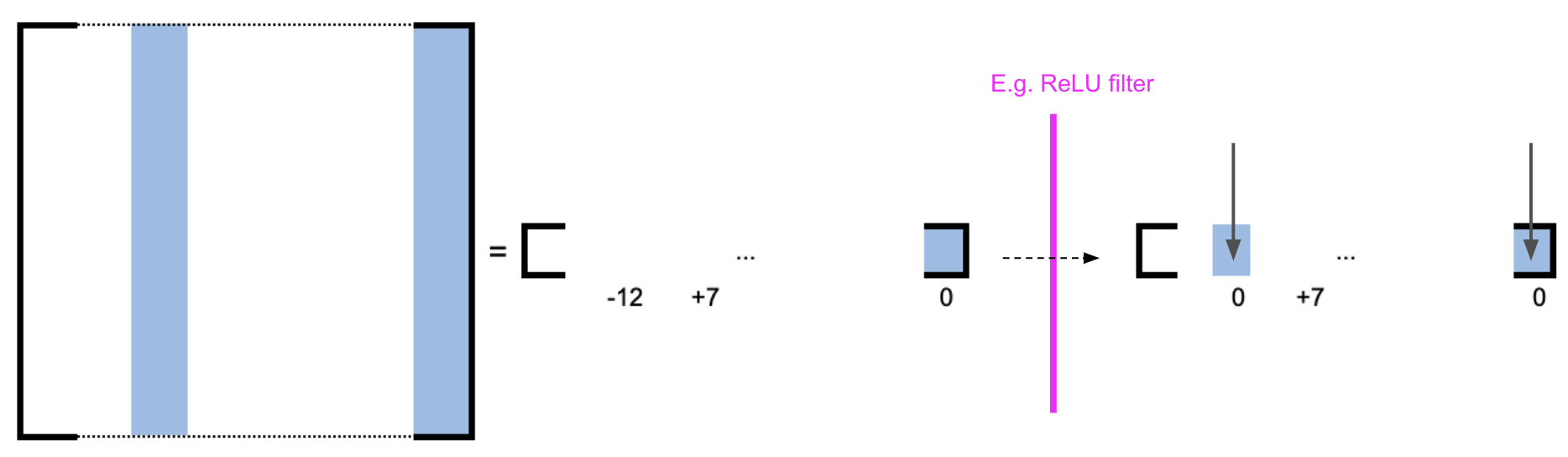
Figure 3: Activation Layer Pruning.
Embedding Layer Pruning
Embedding layers undergo pruning based on token frequency within each dataset. This necessitates large calibration sets to ensure accurate pruning decisions, as smaller datasets might not reflect true token necessity (Figure 4).
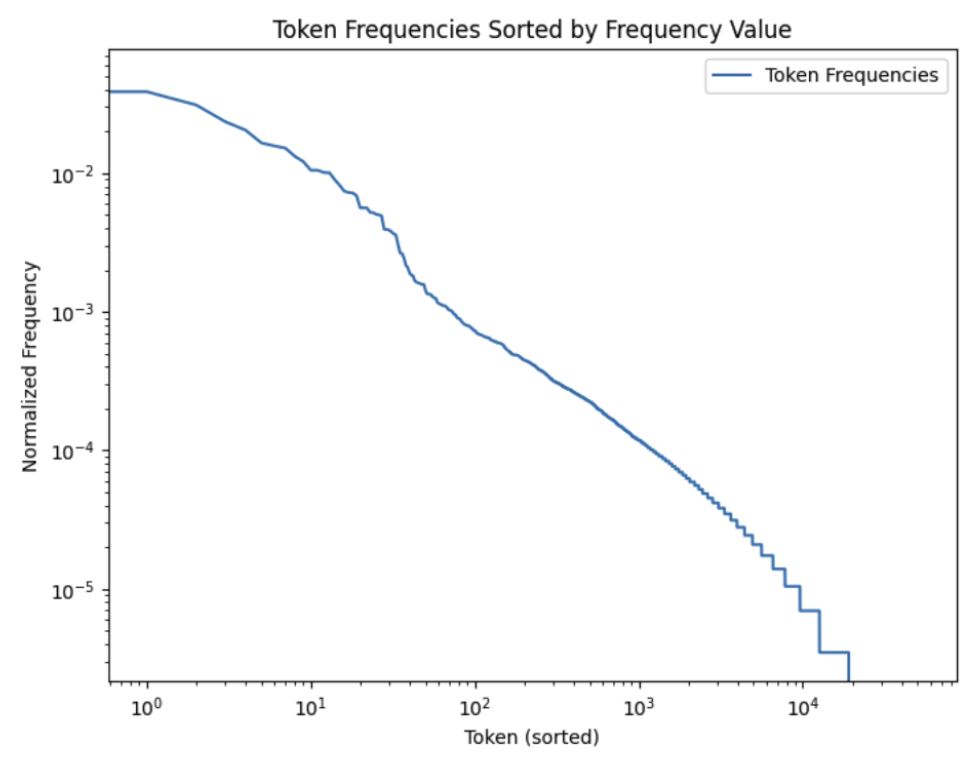
Figure 4: Embedding Layer Pruning.
Evaluation and Results
Perplexity and MCQ Testing
Perplexity, a standard metric for evaluating LLMs, and MCQ testing were employed to assess performance post-pruning. The experiments showed improved or maintained perplexity and competitive MCQ performances, indicating effective trade-offs between model size and task performance.
Large Pruning Threshold Exploration
Exploration into larger pruning thresholds (10−1) provided insight into the limits of pruning. Significant size reduction was achieved, but results suggested potential overfitting, necessitating further study to mitigate such effects.
Conclusion and Future Work
Contextual pruning as a methodology for developing Mini-GPTs showcases promising results in maintaining domain-specific performance with reduced resource usage. Future research will focus on several key areas:
- Max Neuron Magnitude Pruning: Exploring pruning based on neuron magnitude thresholds.
- Larger Dataset Fine-Tuning: Mitigating overfitting with larger datasets to enhance model robustness.
- Integration with Optimization Techniques: Combining pruning with quantization for better performance.
- Expansion to More Models: Applying the approach to newer models like Phi-2 to observe universal applicability.
This research lays a foundation for more sustainable and efficient LLM applications, particularly beneficial for industries requiring on-prem installations, such as healthcare and gaming.

