- The paper introduces BlockPruner, a method that decomposes Transformer layers into MHA and MLP blocks to target finer-grained redundancies without significant performance loss.
- The iterative search algorithm employs perplexity measures to accurately assess block importance, outperforming traditional layer-level pruning techniques.
- Experimental results demonstrate that BlockPruner achieves superior compression on models like Llama2, Baichuan2, and Qwen1.5 while maintaining robust downstream performance.
BlockPruner: Fine-grained Pruning for LLMs
The paper "BlockPruner: Fine-grained Pruning for LLMs" by Longguang Zhong et al. presents an innovative approach to the structured pruning of LLMs. The proposed method, named BlockPruner, enhances model compression by targeting finer-grained redundancies within LLM layers, specifically focusing on MHA and MLP blocks.
Introduction
The paper identifies that the increasing size and complexity of LLMs have resulted in substantial computational demands, challenging their deployment in resource-limited environments. Traditional model compression techniques, including knowledge distillation, quantization, and pruning, aim to reduce these demands without significantly impacting performance. BlockPruner diverges from traditional approaches by addressing redundancies at a finer level of granularity within layers.
Recent studies reveal that LLMs contain redundant layers, which can be pruned without severely affecting performance. While these methods preserve the model's overall architecture, they overlook redundancies within MHA and MLP blocks. Recognizing this, BlockPruner segments Transformer layers into MHA and MLP blocks, assessing their importance using perplexity measures, followed by a heuristic pruning search.
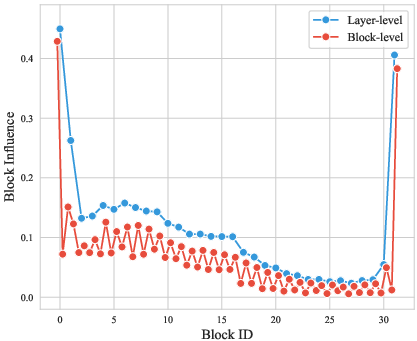
Figure 1: Block Influence (BI) scores \citep{men2024shortgpt} for Llama2-7B indicate finer-grained redundancies at the block level compared to layer level.
Methodology
Minimal Residual Block
BlockPruner operates by decomposing each Transformer layer into two residual blocks: MHA and MLP (Figure 2). This decomposition allows for finer control over pruning decisions, targeting specific blocks rather than entire layers.
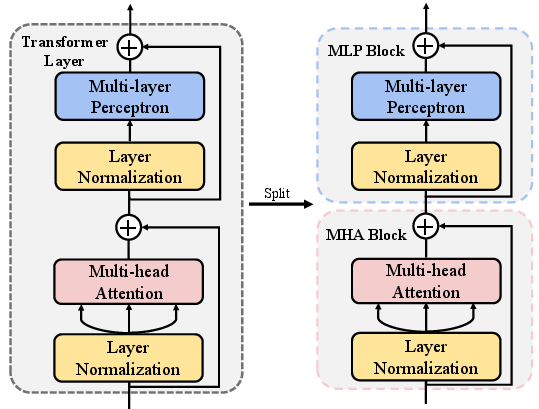
Figure 2: Illustration depicting that a Transformer layer can be subdivided into two residual blocks.
Block Importance
The method assesses block importance through perplexity, a measure reflecting the impact of removing a block on the model's overall performance. This global metric captures the block's cumulative influence, as opposed to local measurements like Block Influence or Relative Magnitude.
Iterative Search for Block Pruning
BlockPruner iteratively removes blocks with the lowest importance scores, employing a calibration dataset to ensure minimal degradation. The iterative search algorithm differs from traditional static pruning approaches, which often remove blocks indiscriminately.
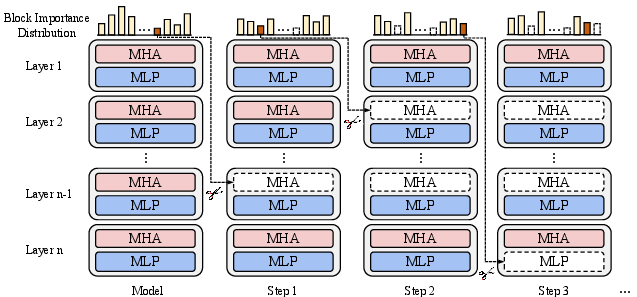
Figure 3: Overview of our BlockPruner, illustrating the iterative pruning process.
Experimental Results
BlockPruner was applied to various LLMs, including Llama2, Baichuan2, and Qwen1.5, across several benchmarks. The results showed that BlockPruner achieves more granular pruning with less performance loss compared to other state-of-the-art methods.
Main Results
BlockPruner consistently outperformed baselines such as SliceGPT, LaCo, ShortGPT, and RM, as shown in Table \ref{tab:main_res}. The approach demonstrated robustness across different pruning ratios, maintaining higher average scores in downstream tasks.
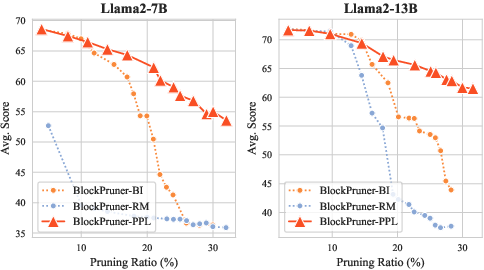
Figure 4: The impact of different block importance metrics on the pruning performance of BlockPruner.
Ablation Study
An ablation study revealed that each component of the BlockPruner algorithm contributes significantly to its effectiveness. Removing the search procedure or substituting block pruning with layer pruning led to substantial performance declines.
Redundancies Between MHA and MLP
Experiments focusing on individual MHA and MLP blocks revealed that MHA blocks exhibit higher redundancy, thus are more frequently pruned with minimal impact on performance. This confirms the nuanced approach of BlockPruner in targeting specific redundancies at the block level.
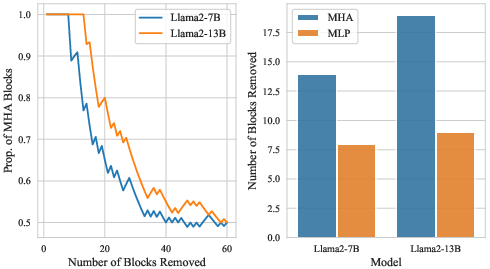
Figure 5: The proportion of MHA blocks removed during the pruning process.
Impact of Dataset on Pruning
The choice of calibration dataset affects pruning efficacy. The Alpaca dataset, aligned with downstream tasks, consistently delivered better results than other datasets.
Conclusion
BlockPruner presents a novel fine-grained pruning strategy targeting block-level redundancies in LLMs, resulting in efficient model compression with minimal performance degradation. By leveraging perplexity measures and dynamic pruning algorithms, BlockPruner offers a comprehensive solution to optimize LLMs for deployment in resource-constrained environments.
Limitations
Future work should explore alternative block importance metrics and optimization algorithms to refine pruning processes further. Moreover, extending this approach to even larger LLMs could amplify its applicability across diverse applications. The scalability of BlockPruner ensures its adaptability for pruning larger models in subsequent studies.