- The paper introduces a novel quantised global autoencoder that leverages global tokenization to improve image compression and generation.
- The methodology employs a VQ-VAE framework with U-Net and custom affine transformations to efficiently quantize and reconstruct global image features.
- Empirical results on datasets like ImageNet and MNIST demonstrate enhanced PSNR, SSIM, and FID compared to traditional patch-based methods.
Quantised Global Autoencoder: A Holistic Approach to Representing Visual Data
Introduction
The paper "Quantised Global Autoencoder: A Holistic Approach to Representing Visual Data" presents a novel method for encoding visual data using a global perspective rather than traditional local patch-based approaches. This work leverages the principles of spectral decompositions akin to the Fourier transform but extends these ideas by learning custom basis functions through a VQ-VAE framework. This method optimizes image compression by adaptively quantizing tokens that encapsulate global rather than localized content. The approach not only offers significant advancements in compression but also holds promise for improved generative capabilities with image data.
Methodology
Global Tokenization
The core innovation in this research is the development of a quantized global autoencoder (QG-VAE) that utilizes a unique method for tokenizing images. Instead of encoding images into local patches, QG-VAE learns to decompose images into global tokens. These tokens capture the overall structural and compositional information by transposing features between channels and feature dimensions to spread the representational burden more evenly across the image.
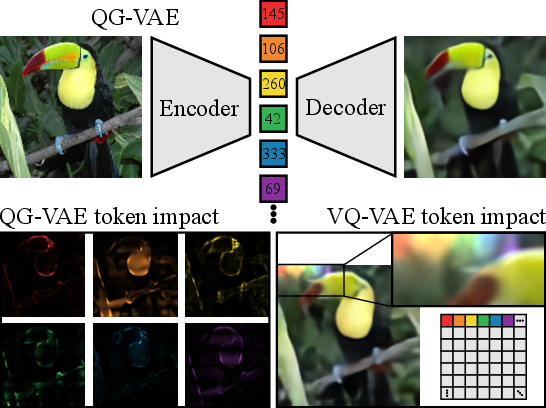
Figure 1: Our autoencoder produces a number of global tokens that represent the image, with each token influencing the colored region of the image. Example shows 256 tokens, a ratio of 64 pixels to one token for ImageNet.
The encoding process starts by processing images to create a multi-channel feature map, allowing each channel to hold comprehensive information over the entire image. A transpose operation shifts from local to global features, compressing each feature map into a quantized token.
Architectural Design
The architecture employs a U-Net to enhance image features, which are then subjected to a learned affine transformation for quantization. The advantage of this design is demonstrated through the efficient use of Voronoi diagrams to optimize codebook allocations. This method balances information content across tokens while avoiding the pitfalls of overused or underutilized codewords.
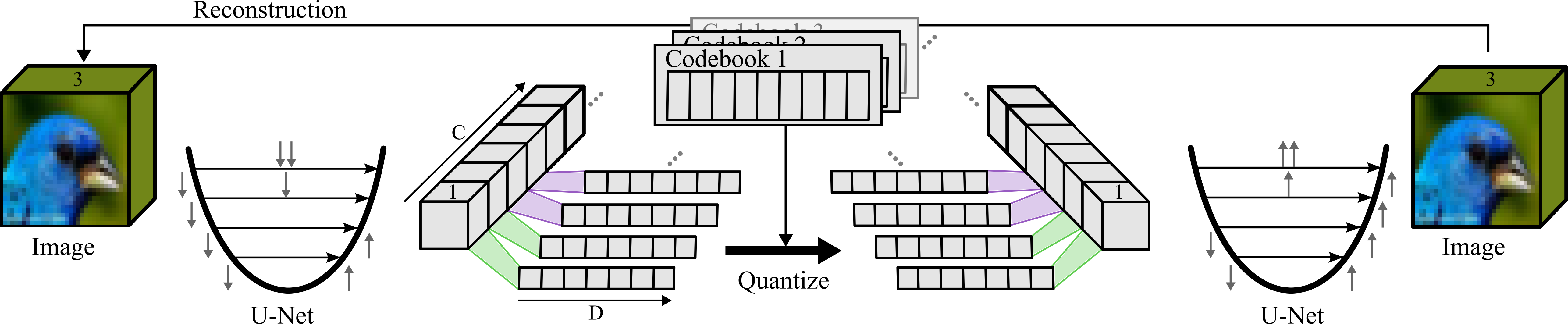
Figure 2: Our base architecture: We encode our data by increasing the input to C different feature maps in the channels with a U-Net, then compress each channel individually into a token.
Each global token is projected back into a feature map channel using a similar transformation, which is decoded into a complete image through a second U-Net. This process ensures that the representation retains a global context that is lost in traditional patch-based coding schemes.
Evaluation and Results
Compression Benchmarks
The QG-VAE approach showcases superior compression rates compared to state-of-the-art methods. By evaluating on datasets such as ImageNet, CelebA, MNIST, and CIFAR-10, the authors demonstrate significant improvements in several metrics, including PSNR, SSIM, and FID.

Figure 3: Input, output, and absolute difference between the two, produced by our autoencoder. 256 tokens/288 bytes for ImageNet.
Generative Capabilities
In addition to compression, QG-VAE supports strong generative modeling capabilities. When applied to tasks such as autoregressive generation, the learned global representation provides a linear latent space more naturally suited for generating coherent image sequences, surpassing the generative performance of traditional VQ-VAEs.
Implications and Future Work
The implications of this research extend beyond compression into practical applications in generative modeling, particularly in image synthesis and transformation tasks. The holistic representation of visual data could lead to advancements in domains requiring global image understanding, like image editing and enhancement tools, as well as in efficiency-critical applications such as UAV image processing.
Future research could explore integrating attention mechanisms to further augment the global representation capabilities of the QG-VAE, and optimizing codebook usage through more sophisticated resetting techniques.
Conclusion
The Quantised Global Autoencoder presents a compelling holistic approach to image representation that goes beyond local patch-based techniques by prioritizing a global tokenization strategy. This approach has demonstrated strong performance improvements in both compression and generation tasks, offering a versatile framework for future developments in visual data representation.