- The paper presents MMLongBench-Doc, a benchmark that evaluates LVLMs’ long-context multi-modal document understanding using 130 annotated PDFs.
- It employs a three-stage annotation pipeline and analyzes expert-annotated questions to assess challenges in multi-modal document analysis.
- Experimental results reveal LVLMs underperform compared to OCR-parsed LLMs, underscoring the need for improved long-document processing.
Overview of MMLongBench-Doc
MMLongBench-Doc provides a comprehensive benchmark for assessing the capabilities of Large Vision-LLMs (LVLMs) in understanding lengthy, multi-modal documents. This paper introduces the construction of MMLongBench-Doc, which includes a diverse set of 130 PDF-formatted documents, assembled to challenge the existing models and drive advancements in document understanding.
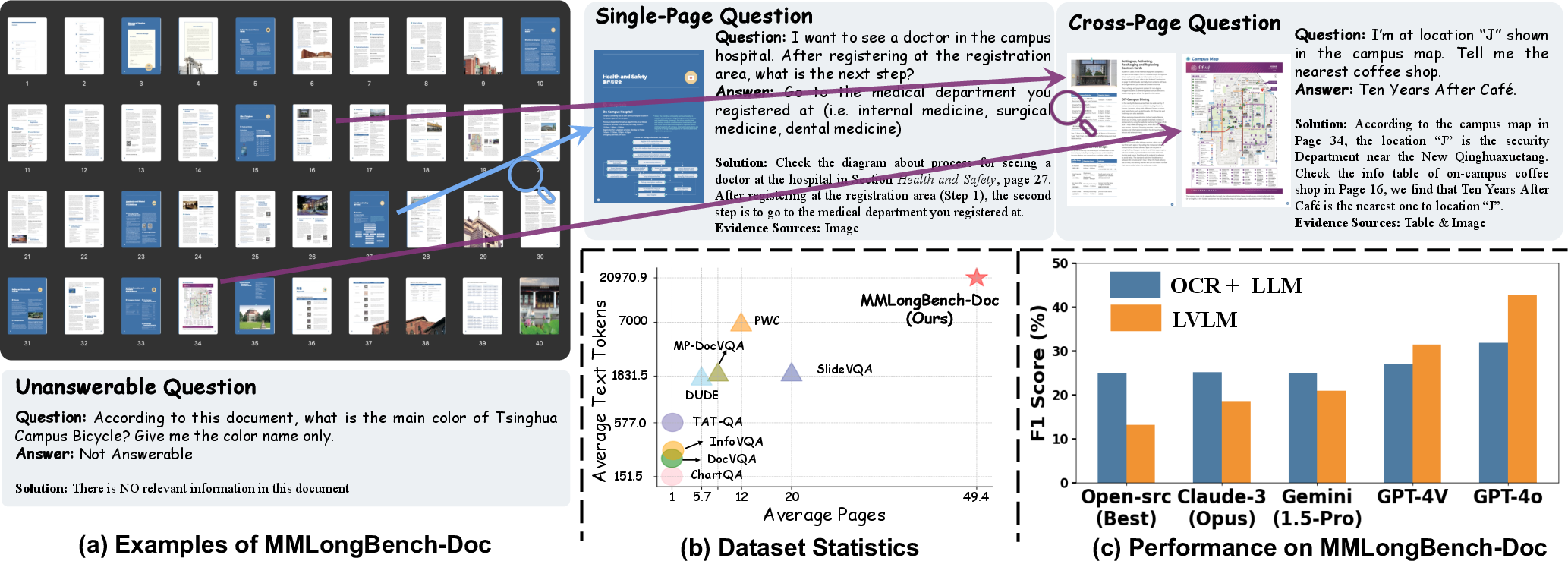
Figure 1: MMLongBench-Doc evaluates understanding abilities of LVLMs on lengthy documents that span tens of pages and incorporate multi-modal elements. Experiments (bottom-right) indicate that most LVLMs struggle, even falling behind LLMs that are fed with only OCR-parsed documents.
Dataset Construction
Document Collection
The dataset consists of documents from seven distinct domains: Research Reports, Financial Reports, Academic Papers, Brochures, Guidelines, Administration and Industrial Files, Tutorials, and Workshops. It aggregates documents from four existing datasets and new collections from sources like Arxiv and ManualsLib. Each document averages 49.4 pages and 20,971 textual tokens.
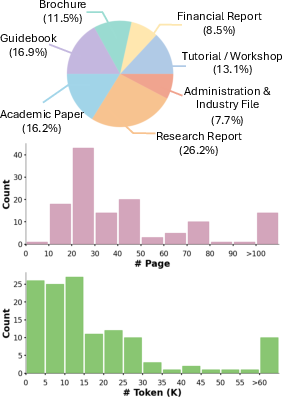
Figure 2: Detailed distribution of documents. Top: Document type. Middle: Page Number. Bottom: Token Number.
Annotation Pipeline
The construction of MMLongBench-Doc involves a three-stage annotation pipeline:
- Document Collection: Identifying and selecting documents based on size and diversity.
- Question and Answer Collection: Annotation of human-annotated questions through expert-level evaluations, edits, and creation of new questions.
- Quality Control: Implementing a semi-automatic quality assurance process to ensure high-quality annotations.
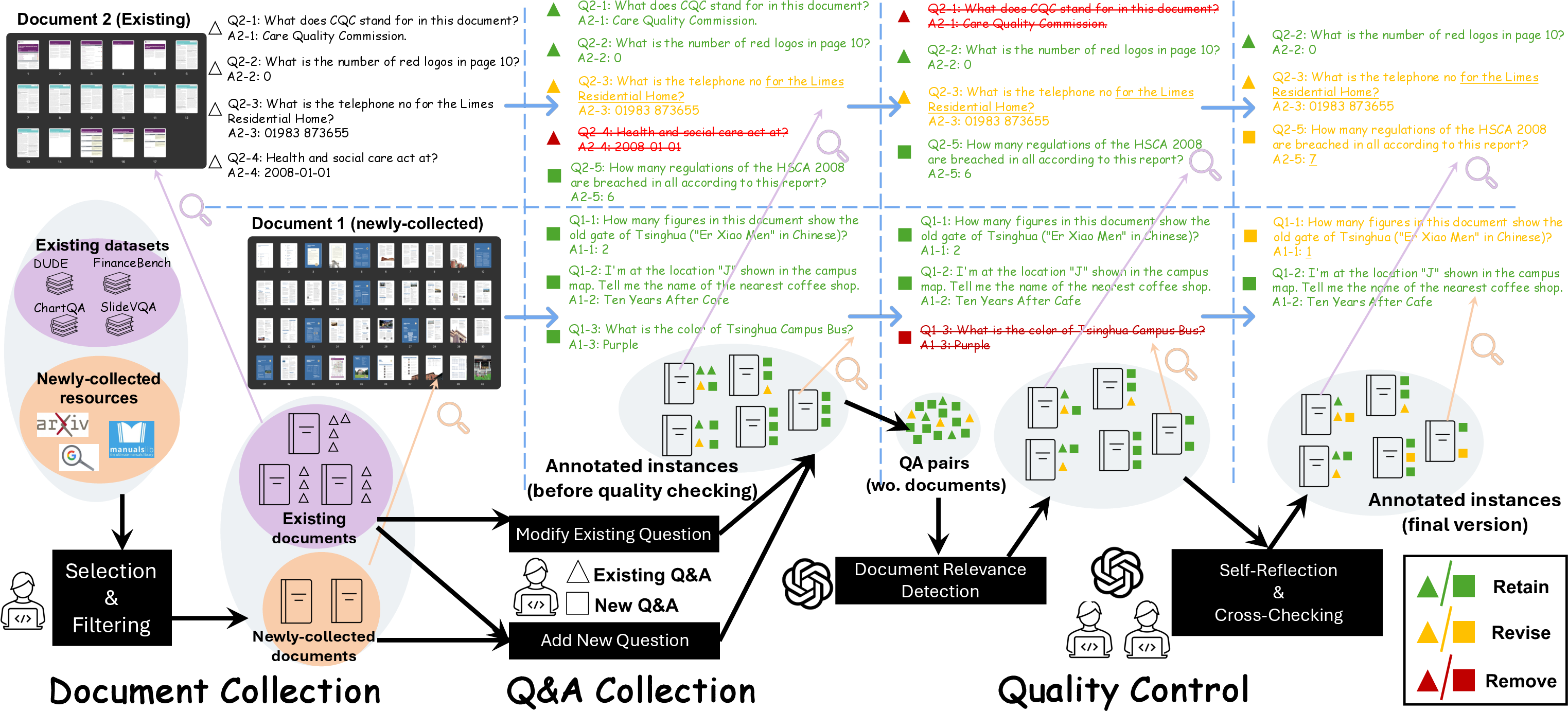
Figure 3: The annotation pipeline of MMLongBench-Doc.
Question Distribution
The benchmark comprises 1,062 expert-annotated questions, categorized into single-page, cross-page, and unanswerable questions. These questions assess various document understanding capabilities and necessitate interactions with text, layout, charts, tables, and images.

Figure 4: Detailed distribution of questions and answers. Left: Absolute position of answer evidences (the page index). Middle: Relative position (the page index/document page number). Right: Evidence page number of each question. (0: unanswerable question; >2: cross-page question).
Evaluation and Results
Experimental Setup
Fourteen LVLMs were evaluated against the benchmark, using both proprietary and open-source models. The evaluation protocol involved response generation, answer extraction, and score calculation.
The evaluation revealed significant challenges in long-context DU. Despite advancements, current LVLMs, like GPT-4o, struggle with long documents, achieving an F1 score of only 42.7%, showcasing the complexity of the task.
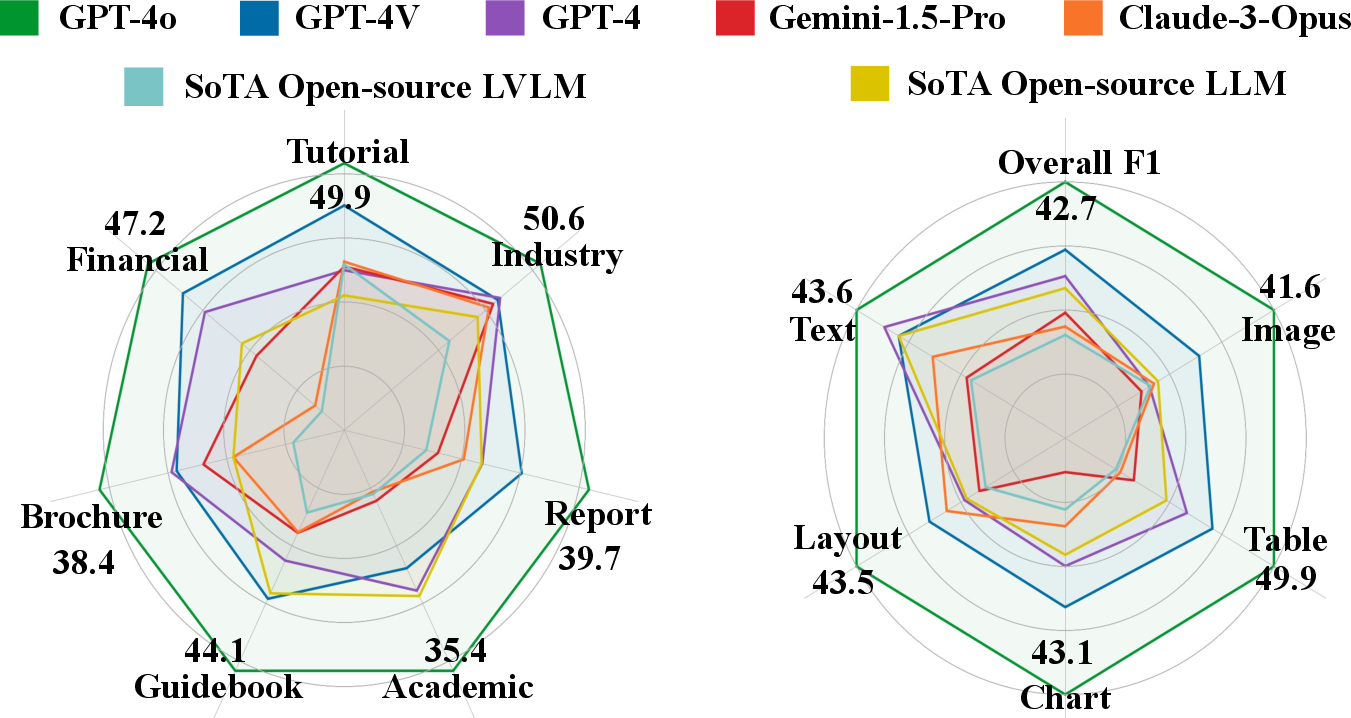
Figure 5: Fine-grained results on various document types and evidence sources.
Furthermore, the comparative analysis between LVLMs and LLMs showed LVLMs' limitations, as they often performed worse than OCR-parsed LLMs in long-context DU.
Oracle Setting
The study explored an oracle setting, demonstrating that even with direct access to relevant pages, LVLMs like InternLM-XC2-4KHD faced considerable performance degradation, leading to an improved but still unsatisfactory F1 score.
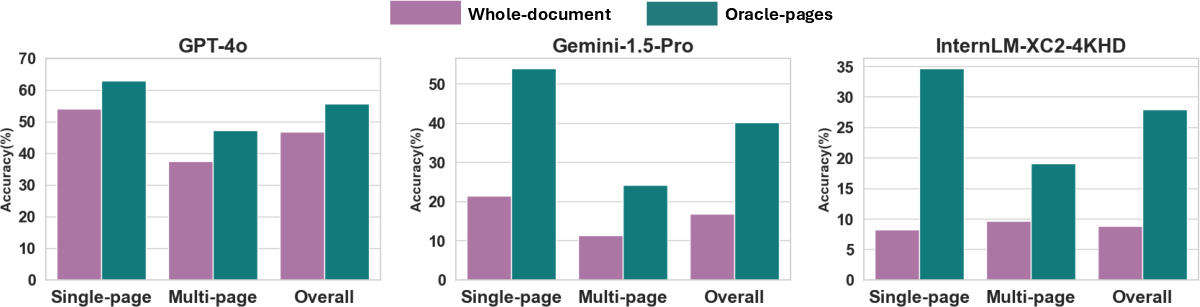
Figure 6: Performance comparisons between normal setting (feeding models with the whole documents) and oracle setting (feeding models only with the evidence pages) among three LVLMs.
Error Analysis and Case Studies
Errors are primarily due to perceptual inaccuracies and hallucinated evidence. Qualitative errors include incorrect reasoning and irrelevant answers, revealing gaps in models' understanding and processing capabilities.

Figure 7: Case Study. Evidence sources: two charts and one table. The three evidence pages of this question are zoomed in. We manually analyze the responses step-by-step: the correct extracted information and reasoning are colored in green, and the wrong ones are colored in red.
Conclusion
MMLongBench-Doc significantly contributes to the domain by presenting comprehensive challenges for long-context document understanding. The benchmark provides a pathway for improving LVLMs and serves as a foundation for future research to tackle the intricate requirements of DU tasks. The development and refinement of LVLMs can vastly benefit from addressing the shortcomings identified through this benchmark. Future research should focus on pre-training paradigms and context management to enhance the performance of LVLMs in handling multi-modal documents.