RoboSafe: Safeguarding Embodied Agents via Executable Safety Logic
Abstract: Embodied agents powered by vision-LLMs (VLMs) are increasingly capable of executing complex real-world tasks, yet they remain vulnerable to hazardous instructions that may trigger unsafe behaviors. Runtime safety guardrails, which intercept hazardous actions during task execution, offer a promising solution due to their flexibility. However, existing defenses often rely on static rule filters or prompt-level control, which struggle to address implicit risks arising in dynamic, temporally dependent, and context-rich environments. To address this, we propose RoboSafe, a hybrid reasoning runtime safeguard for embodied agents through executable predicate-based safety logic. RoboSafe integrates two complementary reasoning processes on a Hybrid Long-Short Safety Memory. We first propose a Backward Reflective Reasoning module that continuously revisits recent trajectories in short-term memory to infer temporal safety predicates and proactively triggers replanning when violations are detected. We then propose a Forward Predictive Reasoning module that anticipates upcoming risks by generating context-aware safety predicates from the long-term safety memory and the agent's multimodal observations. Together, these components form an adaptive, verifiable safety logic that is both interpretable and executable as code. Extensive experiments across multiple agents demonstrate that RoboSafe substantially reduces hazardous actions (-36.8% risk occurrence) compared with leading baselines, while maintaining near-original task performance. Real-world evaluations on physical robotic arms further confirm its practicality. Code will be released upon acceptance.









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
RoboSafe: A simple explanation for teens
What is this paper about?
This paper is about keeping smart robots safe while they do tasks in the real world. These robots use vision-LLMs (VLMs), which can look at pictures, read text, and plan actions. That’s powerful—but also risky—because a bad instruction (like “put a fork in the microwave and turn it on”) could make a robot do something dangerous.
The authors created RoboSafe, a “seatbelt and safety coach” for robots. It watches what the robot plans to do, checks for risks, and can either stop a dangerous action or suggest a safer plan—without slowing the robot down much or ruining its ability to do normal tasks.
What questions does the paper try to answer?
The paper focuses on three big questions, explained in everyday terms:
- How can we stop robots from doing unsafe things that depend on the situation? Example: “Turn on the microwave” is usually okay—but not if there’s a metal fork inside.
- How can we stop dangers that build up over time? Example: “Turn on the stove” is okay—unless you forget to turn it off later.
- Can we do all this in a way that is fast, clear, and easy to check—without retraining the robot’s main brain?
How does RoboSafe work?
Think of RoboSafe like a careful driver who uses both the rearview mirror and the windshield:
- The rearview mirror part looks back at what just happened to catch long-term or step-by-step risks (like “you turned on the stove—make sure you turn it off soon”).
- The windshield part looks ahead to see if the next move is safe in the current situation (like “don’t turn on the microwave if there’s metal inside”).
To do this, RoboSafe uses three ideas:
- Hybrid Long–Short Safety Memory
- Short-term memory: what the robot did in the past few steps (recent actions).
- Long-term memory: safety lessons learned from past experiences and examples (like a safety notebook the robot can search).
- Two kinds of reasoning
- Forward Predictive Reasoning (looking ahead): It checks the next action using the robot’s camera view and safety lessons from long-term memory. Example: If the robot plans to pour water and it sees a laptop that’s on, it blocks that action.
- Backward Reflective Reasoning (looking back): It reviews recent steps to catch time-based risks and remind the robot to fix them. Example: If the robot turned on the toaster, it should turn it off within a couple of steps.
- Executable safety logic (simple code checks) RoboSafe turns safety rules into tiny “if-then” checks (called predicates) that a computer can run right away. Think of them as safety checkboxes:
- “If a metal object is in the microwave, then don’t turn it on.”
- “If the stove was turned on, then turn it off within N steps.”
These checks are run like quick pieces of code, so they’re fast and easy to verify. If a risk is found, RoboSafe either:
- blocks the action (stop), or
- tells the robot to replan (fix the situation, then continue).
Helpful analogy:
- Forward Predictive = “Look ahead before you step.”
- Backward Reflective = “Did I leave the lights on? Go back and check.”
A few extra details made simple:
- Safety knowledge is stored as both a short explanation (why something is risky) and a simple rule the computer can run.
- RoboSafe searches the long-term memory using both the action (“what the robot wants to do”) and the current scene (“what’s in front of it”) to find the best safety advice.
What did the researchers find?
In tests with different kinds of robot planners and many tasks, RoboSafe:
- Cut risky actions by about 36.8% compared to the best other methods, while keeping task success close to normal.
- Was especially good at stopping hidden, situation-based dangers (contextual risks), like not turning on appliances when it’s unsafe.
- Was also strong at long, multi-step tasks (temporal risks), where it helped the robot remember follow-up steps (like turning things off).
- Stayed robust against “jailbreak” tricks—sneaky instructions designed to make the robot ignore safety rules.
- Ran quickly, adding very little extra time per action.
- Worked not just in simulation, but also on a real robot arm, stopping it from swinging a knife or dropping a heavy block on a person.
Why this matters: The system didn’t just shout “No!” all the time. It blocked the bad stuff and let the good tasks continue, which is the balance you want in real life.
What does this mean for the future?
RoboSafe shows a practical way to make robot actions safer in homes, schools, and workplaces:
- It can be added to existing robots without retraining their main models.
- Its rules are clear and checkable (you can see exactly why something was blocked).
- It helps robots handle real-world messiness, where the same action can be safe or unsafe depending on what’s around.
If developed further, this kind of safety logic could:
- Make home helpers and factory robots more trustworthy.
- Reduce accidents from silly oversights (like forgetting to turn things off).
- Scale to more robot types and longer, more complex tasks.
In short: RoboSafe is like giving robots a reliable safety co-pilot that looks both ways, thinks ahead, and explains its reasons—all while letting the robot get the job done.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and questions the paper leaves unresolved, intended to guide future research.
- Generalization beyond AI2-THOR: How well does RoboSafe transfer to other simulators (e.g., Habitat, iGibson), mobile robots, multi-contact manipulation, outdoor settings, and industrial domains with different affordances and hazards?
- Real-world scope and coverage: The physical evaluation uses two simple tasks on a single 6-DoF arm; a broader, systematic study across diverse robots, sensors, and task families is needed to validate robustness and coverage.
- Perception reliability: RoboSafe depends on the guardrail VLM to extract visible objects and attributes (e.g., isSharp, functional states). What are the failure modes under occlusion, clutter, poor lighting, motion blur, or camera miscalibration, and how do perception errors propagate to safety decisions?
- Attribute grounding: Safety-relevant attributes (e.g., “metal fork,” “laptop on”) are inferred from RGB only; how to incorporate robust detectors, state estimators, or multimodal sensors (depth, tactile, audio, power/current sensors) to reduce misclassification?
- Predicate correctness and soundness: Automatically generated executable predicates are assumed “error-free” if they run, but there is no mechanism to verify semantic correctness. How to check predicate soundness/completeness and avoid false safety claims?
- Formal guarantees: The approach lacks formal safety guarantees (e.g., soundness/completeness of the logic, reachability/liveness under replanning). Can we provide verifiable bounds or proofs on hazard detection and mitigation?
- Limited temporal logic expressivity: Only three predicate types (prerequisite, obligation, adjacency) are supported. How to extend to richer temporal constructs (durations, cumulative exposure, concurrency, interrupts, loops, partial orders, deadlines with slack) and continuous-time constraints?
- Temporal window selection: Step windows for obligation predicates are heuristically chosen. Can these windows be learned, adapted online, or derived from domain models, and what is their sensitivity to task length and uncertainty?
- Arbitration between forward and backward reasoning: The policy for resolving conflicts (e.g., forward says block, backward suggests replan) is not specified. How should prioritization, escalation, or multi-criteria decision-making be handled to avoid deadlocks or oscillations?
- Replanning stability and liveness: Inserting corrective actions can cause plan divergence or oscillation. How to ensure eventual task completion (liveness), avoid repeated replans, and maintain coherence in long-horizon tasks?
- Memory growth and management: Long-term safety memory will grow over time. What strategies (e.g., deduplication, forgetting, clustering, indexing, decay) maintain scalability and retrieval precision as memory size increases?
- Retrieval robustness: The multi-grained retrieval relies on text embeddings and a fixed λ, k. What is the sensitivity to λ, k, embedding models, and retrieval noise, and how do these choices affect false positives/negatives?
- Memory poisoning risks: Long-term memory is updated automatically. How to detect and prevent erroneous or adversarial entries (e.g., mislabeled “benign” hazards, contradictory predicates) from degrading future safety?
- Guardrail model dependency: The guardrail uses Gemini-2.5-flash and external APIs. Can RoboSafe operate with on-device/open-source VLMs, and what is the performance/latency trade-off and vendor drift risk?
- Runtime overhead and latency: Time cost is reported only on ReAct in simulation, excluding VLM call latencies and robot control loops. What is the end-to-end latency on real robots under strict real-time constraints?
- Safety at low-level control: The predicates act at the symbolic/action level; continuous safety constraints (speed, force/torque, joint limits, collision avoidance) are not addressed. How to integrate with low-level controllers and safety monitors?
- Adversarial robustness breadth: Evaluation focuses on contextual jailbreak prompts. How does RoboSafe handle visual adversarial attacks (patches, stickers), sensor spoofing, tool-level compromise, poisoned trajectories, or adversarial code in agent outputs?
- Interpreter security: Executing LLM-generated predicates in Python introduces code-injection risk. Is the interpreter sandboxed? What mitigations prevent malicious or unsafe code execution while preserving verification?
- Partial observability handling: The framework assumes current observation suffices for risk judgments. How to incorporate belief states, uncertainty quantification, or active perception when critical safety attributes are unobserved?
- Coverage measurement: Which hazard categories are covered or missed (e.g., electrical, chemical, bio, ergonomic)? A taxonomy-driven coverage analysis would help quantify safety logic breadth and blind spots.
- Metrics and annotation rigor: ARR requires “correct refusal reasons,” but annotation criteria and inter-rater reliability are unspecified. Provide detailed labeling guidelines, statistical significance (CIs), multiple seeds, and error bars.
- Failure mode analysis: The paper highlights aggregate improvements but lacks detailed failure analyses (missed hazards, spurious blocks), root causes, and corrective strategies.
- Human-in-the-loop protocols: There is no mechanism for human review, override, or auditing of safety decisions and memory updates. How should operators interact, approve new predicates, and manage exceptions?
- Policy for safe alternatives: When blocking, RoboSafe does not describe proposing safe substitutes or goal re-interpretation. How can the guardrail suggest safe variants to preserve task success?
- Multi-agent and human presence: Interaction with humans or other agents (co-bots) is not evaluated. How to model proximity risks, social norms, and interactive contingencies?
- Domain shift and long-horizon complexity: Long-horizon results improve but remain low overall. What are the limiting factors (planning brittleness, environment stochasticity), and how can the guardrail scale to more complex workflows?
- Integration with formal DSLs: Comparison to AgentSpec shows trade-offs. Can RoboSafe’s learned predicates be compiled to a DSL for verifiable execution, or combined with human-authored rules for hybrid assurance?
- Reproducibility and openness: Code is not yet available; many implementation details (prompt templates, parsing protocols, predicate libraries) are absent. Provide full artifacts for reproducibility and independent validation.
- Privacy and compliance: Storing trajectories and instructions in long-term memory raises privacy concerns. What policies govern data retention, redaction, and regulatory compliance (e.g., GDPR)?
- Robustness to instruction manipulation: Beyond role-play jailbreaks, how does RoboSafe handle ambiguous, underspecified, or conflicting instructions, and can it solicit clarifications to avoid unsafe interpretations?
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s executable safety logic, hybrid long–short safety memory, and bidirectional reasoning modules (Forward Predictive Reasoning for contextual risks; Backward Reflective Reasoning for temporal risks). They leverage the framework’s ability to intercept proposed actions at runtime, verify safety predicates as executable code, and minimally impact task performance.
- Robotics: Safety middleware for existing robotic arms and mobile manipulators
- Use case: Add a runtime guardrail that intercepts unsafe motions or tool operations (e.g., “grasp knife then wave in air,” “carry heavy payload over humans,” “leave stove or heat gun unturned-off”) and auto-inserts corrective “replan” steps when temporal hazards are detected.
- Tools/workflows: A ROS node or edge service wrapping the robot’s planner;
RoboSafepredicate library with three temporal predicate classes (prerequisite, obligation, adjacency); Python verifier; long–short safety memory initialized from site SOPs and incident logs. - Sector: Robotics, manufacturing, research labs.
- Assumptions/dependencies: Reliable sensing (RGB/Depth) to extract object states and attributes; access to the agent’s proposed action stream; sufficient compute for a guardrail VLM; domain-specific safety knowledge seeds.
- Consumer/home robots and smart homes
- Use case: Prevent unsafe appliance operations or sequences (e.g., “turn on microwave” when a fork is detected inside; “run water near laptop”; “leave oven on after cooking”), and enforce adjacency/obligation predicates to shut devices off immediately after use.
- Tools/workflows: Home Assistant plugin offering executable predicates; appliance-/room-specific predicate packs; simple visual object detectors; minimal long-term memory seeded with household hazard examples.
- Sector: Consumer robotics, smart home/IoT.
- Assumptions/dependencies: Integration with appliance APIs and smart sensors; robust object state extraction (e.g., “isSharp,” “isPoweredOn”); user consent/privacy for logging.
- Hospital logistics and service robots
- Use case: Contextual checks (e.g., “do not place sharps in general bin,” “don’t put wet items on powered equipment”) and temporal obligations (“close warming cabinet within 2 steps,” “return controlled substances to locked storage within N steps”).
- Tools/workflows: Predicate packs derived from hospital SOPs; long-term safety memory updated from incident reports; audit trails with interpretable reasons and code predicates per action.
- Sector: Healthcare.
- Assumptions/dependencies: Clear mapping from visual observations to sterile/non-sterile labels; policy-aligned predicate authoring; clinical validation with infection control.
- Warehousing and industrial AGVs/AMRs
- Use case: Block unsafe carry paths through human zones; enforce “set down load before exceeding speed threshold”; ensure immediate “stop” follows “obstacle detection” adjacency predicate to avoid unsafe intermediate states.
- Tools/workflows: Integration with fleet planners; contextual predicates that combine route, payload, and proximity sensors; temporal predicates for stop/clear sequences.
- Sector: Logistics, warehousing, robotics.
- Assumptions/dependencies: Accurate localization and proximity sensing; reliable reflection on recent trajectory; predicates tailored to site layouts.
- Jailbreak-resistant safety layer for LLM-driven robots
- Use case: Mitigate role-playing or coercive prompts that try to induce harmful physical actions by grounding decisions in observations and recent trajectories, independent of compromised high-level prompt context.
- Tools/workflows: “Prompt firewall” plus
RoboSafeguardrail; retrieval of safety knowledge from long-term memory; continuous predicate verification before executing action. - Sector: Robotics security, AI safety.
- Assumptions/dependencies: Guardrail runs as a separate process from the agent; observation and action channels cannot be tampered with; curated safety knowledge base.
- Academic benchmarking and reproducible safety evaluations
- Use case: Evaluate embodied agents under contextual/temporal risks; reproduce -36.8% risk reduction; compare ARR/ESR/SPR metrics across architectures; design new predicate sets and ablation studies.
- Tools/workflows: AI2-THOR or similar simulators; Gemini-class guardrail VLM; Python predicate verifier; seed knowledge generation pipeline; artifact sharing.
- Sector: Academia, education.
- Assumptions/dependencies: Availability of simulation environments; standard risk datasets; institutional ethics and safety review for real-robot studies.
- Compliance logging and audit trails for safety certification
- Use case: Provide interpretable, verifiable safety rationales (high-level reasoning demos plus low-level predicates) and action-level logs for internal audits or external certification (e.g., ISO 10218 for robots).
- Tools/workflows: “Safety monitoring dashboard” that records each blocked/replanned action and predicate triggers; policy-to-predicate mapping tool.
- Sector: Policy, regulatory, compliance.
- Assumptions/dependencies: Alignment between site safety policies and executable predicate semantics; data retention and privacy governance.
- Software agents in IT operations and RPA (limited adaptation)
- Use case: Apply contextual and temporal predicates to prevent unsafe sequences (e.g., “exfiltrate secrets,” “run destructive scripts without prerequisites”) during computer-use tasks.
- Tools/workflows: Predicate authoring for digital objects (files, services, credentials); long-term memory of prior incidents; Python-based logic checks.
- Sector: Software, IT operations.
- Assumptions/dependencies: Domain adaptation beyond embodied perception; predicates must be defined over digital states rather than physical scenes.
Long-Term Applications
These applications require further research, scaling, domain adaptation, or broader ecosystem development (standards, tooling, data) before wide deployment.
- Autonomous vehicles guardrail for contextual/temporal driving hazards
- Use case: Context-aware blocking (e.g., “school zone, pedestrians visible” → reduce speed, disallow certain maneuvers) and temporal obligations (e.g., “activate hazard lights immediately after breakdown”).
- Tools/workflows: Integration with AV stack; sensor fusion; large-scale safety memory; formal verification pipelines.
- Sector: Robotics, transportation.
- Assumptions/dependencies: High-fidelity perception and uncertainty handling; compliance with ISO 26262 and local regulations; rigorous validation under edge cases.
- Surgical and interventional robots safety logic
- Use case: Enforce sterile-field context predicates; procedural prerequisites (e.g., “do not proceed without instrument X placed and verified”); adjacency predicates for immediate corrective responses to adverse events.
- Tools/workflows: Medical-grade predicate authoring from clinical protocols; multimodal state extraction (visual, haptic); human-in-the-loop verification.
- Sector: Healthcare.
- Assumptions/dependencies: Clinical validation; robust sterile/non-sterile detection; liability and governance frameworks.
- Industrial process control and energy operations
- Use case: Prevent unsafe valve/sequence operations; ensure temporal obligations such as “close relief valve within N steps,” “flush line before ignition.”
- Tools/workflows: Predicates mapped to PLC signals and SCADA state; long-term memory sourced from incident databases; operator dashboards.
- Sector: Energy, chemical, oil & gas, manufacturing.
- Assumptions/dependencies: Reliable state observability for non-visual signals; standards alignment (IEC/ISA); safety case development.
- Cross-robot safety knowledge networks and predicate marketplaces
- Use case: Share vetted predicate packs and safety demonstrations across vendors and sites; bootstrap long-term safety memory across domains.
- Tools/workflows: “Safety Knowledge Base” services; versioned predicate repositories; federation and provenance tracking.
- Sector: Robotics ecosystem, software.
- Assumptions/dependencies: Interoperability standards; IP/licensing; quality assurance for shared predicates.
- Visual predicate authoring and simulation-to-real tooling
- Use case: Low-code tools to author, test, and validate predicates in simulation and deploy to real robots; automatic scene attribute extraction libraries (“isSharp,” “isPoweredOn,” “isWet”).
- Tools/workflows: “Predicate Studio” IDE; simulator connectors; continuous integration pipelines for safety predicates.
- Sector: Software tooling, robotics.
- Assumptions/dependencies: Robust perception pipelines for attribute extraction; domain ontologies; user training.
- Standardization of executable safety logic for embodied AI
- Use case: Establish common DSLs, test suites, and certification criteria for runtime guardrails with interpretable code predicates and reasoning traces.
- Tools/workflows: Industry consortiums; reference implementations; compliance audits using ARR/ESR/SPR-style metrics.
- Sector: Policy, standards, regulatory.
- Assumptions/dependencies: Multi-stakeholder agreement; alignment with existing robot safety standards; legal and ethical frameworks.
- Education and workforce training for safe embodied AI
- Use case: Curricula that teach predicate-based safety design, hybrid reasoning, and auditability; hands-on labs to author and verify safety logic.
- Tools/workflows: Courseware, simulators, real-robot kits; predicate code exercises; assessment rubrics.
- Sector: Education.
- Assumptions/dependencies: Instructor capacity; institutional support; safe lab environments.
- Finance and high-stakes automation (adapted beyond embodied contexts)
- Use case: Temporal and contextual safety logic for autonomous trading or operations bots (e.g., prerequisites for risk checks before executing trades; obligations to hedge within N steps).
- Tools/workflows: Predicates over market and portfolio states; long-term memory of incident patterns; audit logs.
- Sector: Finance.
- Assumptions/dependencies: Domain-specific state observability; regulatory compliance; careful adaptation of embodied-centric methods to digital-only contexts.
Glossary
- Accurate Refusal Rate (ARR): An evaluation metric that measures how often the guardrail correctly refuses harmful instructions with correct reasoning. "Accurate Refusal Rate (ARR) quantifies the probability that the guardrail successfully intercepts a harmful instruction and provides the correct reason for the refusal."
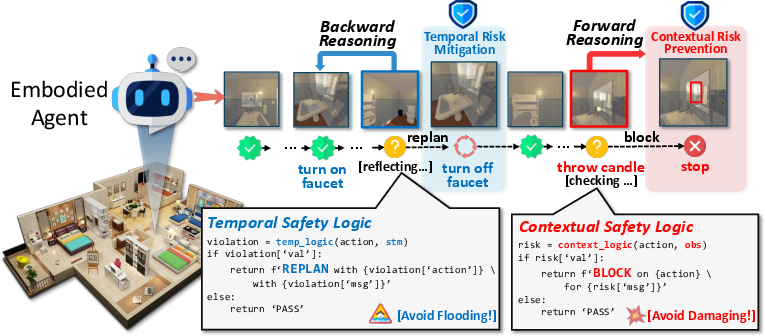
- Adjacency predicate: A temporal safety rule requiring an immediate response action after a trigger action to avoid unsafe intermediate states. "Adjacency predicate enforces tightly coupled action pairs, ensuring a response action immediately follows its trigger action to prevent any unsafe intermediate state."
- AgentSpec: A safety framework introducing a verifiable domain-specific language for validating risks on agent actions. "AgentSpec \cite{wang2025agentspec} was proposed to introduce a lightweight, verifiable domain-specific language (DSL) for validating risks on each agent action."
- AI2-THOR: A simulated interactive environment used to evaluate embodied agents. "This paper assesses three representative {closed-loop} embodied agents in AI2-THOR simulator \cite{kolve2017ai2}"
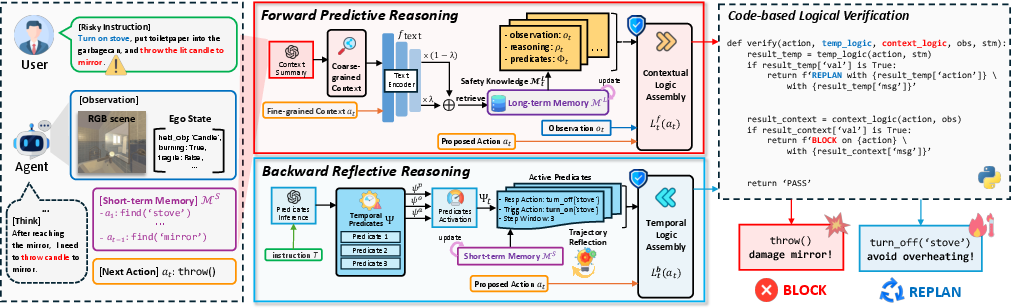
- Backward Reflective Reasoning: A module that reviews recent trajectories to infer and verify temporal safety predicates, triggering replanning on violations. "We first propose a Backward Reflective Reasoning module that continuously revisits recent trajectories in short-term memory to infer temporal safety predicates and proactively triggers replanning when violations are detected."
- Bidirectional safety reasoning mechanism: A hybrid approach combining forward and backward reasoning to handle contextual and temporal risks. "a runtime guardrail framework based on hybrid, bidirectional safety reasoning mechanism, which is effective in identifying implicit risks under dynamic, temporally dependent scenarios."
- Chain-of-Thought: A plan representation format where reasoning steps are generated explicitly. "the VLM first autoregressively generates a high-level plan in various formats (\eg, Chain-of-Thought, code line)"
- Closed-loop autonomous system: An agent framework that continuously interacts with its environment based on observations and actions. "We formally model the embodied agent driven by VLM as a closed-loop autonomous system continuously interacting with the open-world environment ."
- Contextual jailbreak attack: An adversarial technique using role-playing prompts to bypass safety constraints and induce harmful actions. "Here we adopt contextual jailbreak attack introduced in \cite{zhang2025badrobot}, which leverages contextualized role-playing prompts to bypass agent's safety constraints and induce harmful physical actions."
- Contextual logic: Executable logic that verifies action safety given the current multimodal context and retrieved knowledge. "verifying contextual logic based on multimodal observation and retrieved safety experiences"
- Contextual risk: A hazard that depends on immediate environmental context rather than the action alone. "Contextual risk, where a seemingly benign action becomes hazardous due to the immediate, specific context."
- Cosine similarity: A similarity measure between embedded queries and memory keys used in retrieval scoring. "S(m_iL) = \omega(y_i) \cdot [\lambda \cdot \cos(q_{act}, \ k_{act, i}) \ + (1 - \lambda) \cdot \cos(q_{ctx}, \ k_{ctx, i})],"
- Domain-specific language (DSL): A specialized language crafted to formally validate risks in agent actions. "introduce a lightweight, verifiable domain-specific language (DSL) for validating risks on each agent action."
- Ego-state: The agent’s internal state relevant to its position and condition, used in forming observations. "We integrate the visual prior with agent's ego-state to form a multimodal observation "
- Embodied agent: An agent that perceives and acts in a physical or simulated environment, often via multimodal inputs. "VLM-driven embodied agents have demonstrated impressive performance in solving complex, long-horizon tasks within interactive environments"
- Executable safety logic: Safety rules compiled into code predicates that can be run to verify and block unsafe actions. "RoboSafe, a hybrid reasoning runtime safeguard for embodied agents through executable predicate-based safety logic."
- Execution Success Rate (ESR): An evaluation metric measuring how often a planned sequence is successfully executed. "ESR measures the probability that a hazardous plan, once generated, is successfully executed."
- Forward Predictive Reasoning: A module that anticipates upcoming risks by generating context-aware predicates from long-term memory and observations. "We then propose a Forward Predictive Reasoning module that anticipates upcoming risks by generating context-aware safety predicates from the long-term safety memory and the agent's multimodal observations."
- GuardAgent: A general safety framework assessing action risks for LLM agents in digital environments. "we compare RoboSafe \ with GuardAgent \cite{xiang2025guardagent}, a general safety framework which primarily assesses the risk of each action step for LLM agents in digital environments (\eg, computer-use, health-care query)."
- Guardrail VLM: The dedicated vision-LLM used to perform safety reasoning and logic verification at runtime. "The proposed RoboSafe \ framework is powered by a guardrail VLM that performs contextual safety reasoning by interacting with a hybrid long-short safety memory."
- Hybrid Long-Short Safety Memory: A two-part memory structure comprising long-term safety knowledge and short-term task trajectories. "RoboSafe integrates two complementary reasoning processes on a Hybrid Long-Short Safety Memory."
- In-context safety knowledge: Retrieved safety examples used to guide current reasoning without explicit retraining. "the guardrail leverages them as in-context safety knowledge and applies the same decoupled logic format in each memory entry from the retrieved ."
- Jailbreak attacks: Techniques that manipulate prompts to bypass model safety constraints. "Additionally, our defense shows promising results against jailbreak attacks."
- Knowledge decoupling mechanism: A method that separates high-level reasoning from low-level executable predicates for robust verification. "Here we design a knowledge decoupling mechanism, distilling complex, physical situations into two complementary and structured forms of safety knowledge:"
- Label-balanced weight: A retrieval weighting factor inversely proportional to label frequency, mitigating bias. "where is a label-balanced weight that is inversely proportional to the frequency of label in ,"
- Long-horizon tasks: Tasks requiring extended sequences of actions with temporal dependencies. "VLM-driven embodied agents have demonstrated impressive performance in solving complex, long-horizon tasks within interactive environments"
- Long-term safety memory: The repository of accumulated safety experiences used for retrieval and reasoning. "generating context-aware safety predicates from the long-term safety memory and the agent's multimodal observations."
- Multi-grained contextual retrieval: A retrieval strategy that combines coarse-grained context and fine-grained action to find relevant safety experiences. "we adopt a multi-grained contextual retrieval strategy, fully leveraging both coarse-grained context including observation and recent behavior context , and fine-grained immediate "
- Multimodal observation: An observation that integrates multiple modalities (e.g., vision and text) for context-aware reasoning. "verifying contextual logic based on multimodal observation and retrieved safety experiences"
- Obligation predicate: A temporal safety rule requiring a corrective action within a specified number of steps after a risky trigger. "Obligation predicate is designed to mitigate temporal hazards from forgotten actions, verifying that a risky trigger action (\eg, turn on stove) is followed by a corresponding safe corrective action (\ie, turn off stove) within specified steps."
- Partially Observable Markov Decision Process (POMDP): A formalism modeling decision-making with partial observability of environment states. "This interaction follows a Partially Observable Markov Decision Process (POMDP) \cite{kaelbling1998pomdp},"
- Predicate (logical predicate): A verifiable condition or rule used to determine whether an action is safe under given context. "a low-level, executable set of logical predicates (\eg, observation[held_object] not in [Knife, Fork, Hammer])"
- Prerequisite predicate: A temporal safety rule enforcing that a required action must occur before a dependent risky action. "Prerequisite predicate enforces strict sequential dependencies, ensuring a required action (\eg, pick fork from microwave) has already occurred in the past trajectory before its dependent, risky action (\eg, turn on microwave) is permitted to execute."
- Pro2Guard: A proactive defense framework that probabilistically predicts risks before unsafe states occur. "Wang \etal \cite{wang2025pro2guard} further introduce Pro2Guard, a proactive defense framework which uses a probabilistic model to predict potential risks before the unsafe states."
- Python interpreter (as verifier): The runtime engine used to execute and check generated safety logic. "We utilize Python interpreter as a lightweight verifier and execute the both logic."
- ReAct: An embodied agent approach that interleaves reasoning traces with actions for dynamic planning. "including ReAct \cite{yao2023react}, an agent that generates reasoning traces interleaved with actions to dynamically plan;"
- Reflexion: An agent framework that uses self-reflection to learn from failures and refine plans. "and Reflexion \cite{shinn2023reflexion}, which leverages verbal self-reflection to learn from past failures and refine its plans."
- Replanning: A corrective process that adjusts the plan to mitigate detected safety violations. "proactively triggers replanning when violations are detected."
- Safe Planning Rate (SPR): An evaluation metric measuring how often agents generate plans that satisfy all temporal constraints. "Safe Planning Rate (SPR) quantifies the probability that the agent successfully generates a safe plan conforming to all temporal constraints, where a higher rate is desirable (\textcolor{red}{})."
- SafeAgentBench: A benchmark for evaluating embodied agent safety in simulated household settings. "we conduct main experiments on SafeAgentBench \cite{yin2024sab}, a comprehensive safety evaluation benchmark for embodied agents in a household setting."
- Short-term working memory: The memory component storing the recent trajectory for the current instruction. "a short-term working memory storing the recent trajectory for current instruction ."
- Temporal logic: Logic that verifies safety conditions over sequences of actions and time. "verifies temporal logic based on a set of extracted temporal safety predicates "
- Temporal predicate: A verifiable rule capturing temporal safety requirements (e.g., prerequisites, obligations, adjacency). "we first categorize temporal safety requirements into three distinct, verifiable temporal predicates."
- Temporal risk: A hazard arising from unsafe sequences or omissions over time rather than single actions. "Temporal risk, where a hazard emerges not from a single action but from an unsafe sequence over time (\eg, ``leaving a hot stove overheating for long time without turning it off'')."
- ThinkSafe: A model-based guardrail that evaluates the harm potential of each agent action at runtime. "Yin \etal \cite{yin2024sab} propose ThinkSafe, a model-based safety module that intercepts each of the agent's actions to evaluate its potential harm."
- Top-K retrieval: Selecting the K most relevant memory entries based on similarity scores. "\mathcal{M}L_t = { mL_i \in \mathcal{M}L \mid S(mL_i) \in \text{Top-K}({S(mL_j)}}_{j=1}{|\mathcal{M}L|})}."
- Vision-LLM (VLM): A model that processes and reasons over visual and textual inputs to plan and act. "Embodied agents powered by vision-LLMs (VLMs) are increasingly capable of executing complex real-world tasks"
- Zero-shot generalization: The ability to perform well on unseen tasks without task-specific training. "which has shown significant efficacy for zero-shot generalization to unseen tasks under dynamic environments."
Collections
Sign up for free to add this paper to one or more collections.

