- The paper demonstrates that LLMs struggle to simulate reliable human Theory of Mind in open-ended prompts, even with prompt tuning.
- It details the methodology involving prompt tuning and sentiment extraction from Reddit's ChangeMyView interactions.
- Empirical evaluations show that even advanced models like GPT-4 fall short of human benchmarks in nuanced reasoning tasks.
Do LLMs Exhibit Human-Like Reasoning? Evaluating Theory of Mind in LLMs for Open-Ended Responses
The paper "Do LLMs Exhibit Human-Like Reasoning? Evaluating Theory of Mind in LLMs for Open-Ended Responses" explores the challenges and limitations of LLMs in simulating Theory of Mind (ToM) reasoning, particularly in the context of open-ended questions. Understanding ToM enables the recognition of differing intentions, emotions, and beliefs among individuals, which is essential for effective communication and interaction. This paper provides a comprehensive analysis of LLMs' capacities in perceiving and integrating human-like mental states into their reasoning processes.
Theory of Mind in LLMs
Theory of Mind (ToM) refers to the cognitive capability to attribute mental states to oneself and others, allowing for the interpretation and prediction of behaviors. In the computational field, ToM is invaluable for developing AI that can engage in nuanced social reasoning. The study utilized data from Reddit's ChangeMyView platform, where crafting persuasive responses requires complex social reasoning. By examining LLM-generated responses against human responses on this platform, the research aimed to assess the fidelity of LLMs in mimicking human ToM reasoning.
Despite their success in tasks like summarization and translation, LLMs face significant hurdles in reliably demonstrating ToM reasoning in open-ended scenarios, as their responses often lack the depth and nuance typical of human reasoning. Advanced models such as GPT-4, while improved, still exhibit notable struggles in aligning with human ToM capabilities (2406.05659).
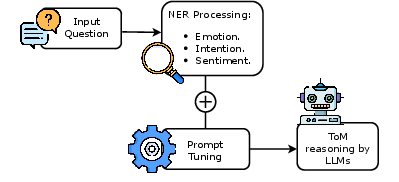
Figure 1: ToM reasoning process via prompt tuning.
Enhancements via Prompt Tuning
To address LLM deficiencies, the paper introduced a prompt tuning method designed to better capture human intentions and emotions. This approach involved tailoring prompts to elicit responses that are influenced by the mental states of the questioner, such as their intentions and emotions. The study leveraged a carefully crafted prompt template and iterative enhancements inspired by the Chain of Thought methodology. This allowed for the examination of whether LLMs can generate responses that better align with complex human reasoning.
The methodology involved extracting sentiments, emotions, and intentions from questions and embedding this contextual information into prompts. Although incorporating these elements led to improvements in LLM performance, these enhancements still fall short of replicating human-level reasoning, highlighting critical areas for potential model refinement.
Empirical Findings and Limitations
The empirical results indicate that while models like GPT-4 perform better than Llama2-Chat-13B and Zephyr-7B in most evaluated metrics, there remains a significant disparity when compared to human reasoning benchmarks. The experiments revealed that understanding and integrating nuanced human emotions and intentions into AI reasoning processes remains challenging for LLMs.
The human-based evaluations and comparison metrics such as ROUGE-L, BLEURT, and BERTScore confirmed that while prompt tuning enhances performance, LLMs do not fully bridge the gap to human-like ToM reasoning. A notable finding was the persistent influence of subjectivity in reasoning tasks, impacting consistency across different evaluators and models.
Conclusion and Future Work
In conclusion, this study highlights the limitations of current LLMs in achieving robust Theory of Mind reasoning, particularly in open-ended responses. Despite some advancements through prompt tuning, there remains a considerable gap between human and machine ToM reasoning capabilities.
Future work will focus on developing more sophisticated methods for integrating human-like mental states into AI models and evaluating their impact on reasoning quality. This includes exploring alternative training methodologies or model architectures that better capture the complexity of human thoughts and emotions. Additionally, further investigation is needed to evaluate whether LLMs can inherently account for mental states without explicit prompt tuning. Such advancements are critical for evolving LLMs into more empathetic and context-aware interactive agents.