- The paper demonstrates that small language models, fine-tuned on domain-specific data, achieve higher accuracy compared to large models in cloud supply chain tasks.
- SLMs operate with significantly reduced latency and lower token counts, optimizing response times and computational efficiency.
- The study highlights the cost-effectiveness and adaptability of SLMs in edge computing environments, indicating broader potential in specialized applications.
Small LLMs for Application Interactions: A Case Study
Introduction
The paper "Small LLMs for Application Interactions: A Case Study" investigates the utilization of Small LLMs (SLMs) for enhancing natural language interactions within specific applications. Unlike LLMs, which require extensive computational resources and can be latency-prone, SLMs afford practical advantages in specialized settings where tasks are well-defined. This paper focuses on a Microsoft internal application for cloud supply chain fulfiLLMent, revealing that SLMs not only achieve higher accuracy than LLMs in task execution but also operate with reduced running time.
Methodology and Implementation
SLM Operation and Data Utilization
SLMs such as Phi-3, Llama 3, and Mistral v0.2 were evaluated for their performance in facilitating tasks within a cloud fulfiLLMent application. The primary mechanism of these models involves fine-tuning with high-quality, curated datasets to enhance accuracy and efficiency, allowing them to operate effectively on modest-sized datasets through offline fine-tuning, as shown in Figure 1.
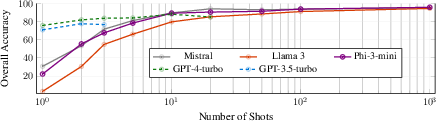
Figure 1: Overall accuracy as a function of the number of the per-task examples. For LLMs, the examples are given in the prompt, and for SLMs they are used for the offline fine tuning.
System Architecture
The paper details the system architecture incorporating SLMs to convert user queries into executable tasks using APIs. Queries undergo a filtering process to determine if they are relevant to the domain; otherwise, the SLM provides alternative guidance. This flow is depicted in Figure 2, illustrating the logical progression from user input to code generation.
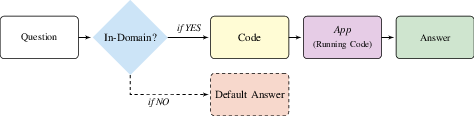
Figure 2: Logical flow. User queries are first processed to determine if they are in-domain. For in-domain queries, generates the relevant code snippet that is executed to provide the answer. Otherwise, the SLM will return a default response (e.g., guide the user about supported tasks.
Evaluation
The paper provides a comprehensive comparison of SLMs against LLMs such as GPT-3.5 and GPT-4. SLMs demonstrate superior overall accuracy across various benchmarks with less reliance on prompt-sized data. Fine-tuning allows SLMs to excel in coder and F-1 performance metrics, demonstrating their effective query handling.
Cost and Latency Analysis
Understanding resource constraints, the paper evaluates latency and token counts for SLMs and LLMs. SLMs significantly lower the average input token count, which optimizes processing speed, achieving response times of a few seconds compared to minutes for LLMs, as demonstrated in production logs like Figure 3.
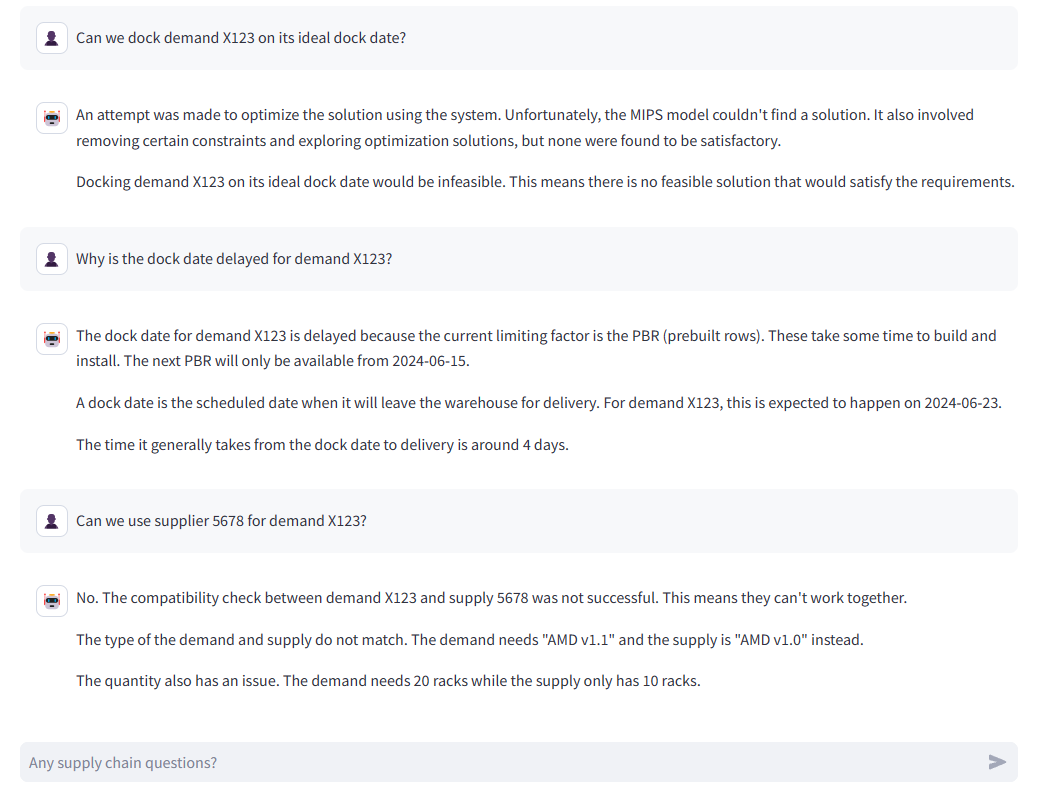
Figure 3: An example of an interaction log from production.
Training and Inference Cost
SLMs offer cost-effectiveness with low training expenses, projected around $10 for 1000-shot training, demonstrating negligible incremental costs per query. This cost efficiency supports viability in resource-constrained environments.
Discussion and Implications
The paper posits that SLMs are a compelling choice for domain-specific applications due to their localized, efficient processing capabilities. Their deployment potential spans edge computing scenarios where connectivity and data transfer are limiting factors. Furthermore, the paper underscores the transformative impact of data quality over model scale, which is pivotal in SLM technology.
Conclusion
The investigation into SLMs reveals substantial advantages in specialized tasks within applications, demonstrating that smaller models can outperform larger counterparts when customized for domain-specific requirements. The implications for computational efficiency, cost-effectiveness, and adaptability to edge computing are significant, fostering further research into expanding SLM applicability across diverse sectors.