Dial-insight: Fine-tuning Large Language Models with High-Quality Domain-Specific Data Preventing Capability Collapse
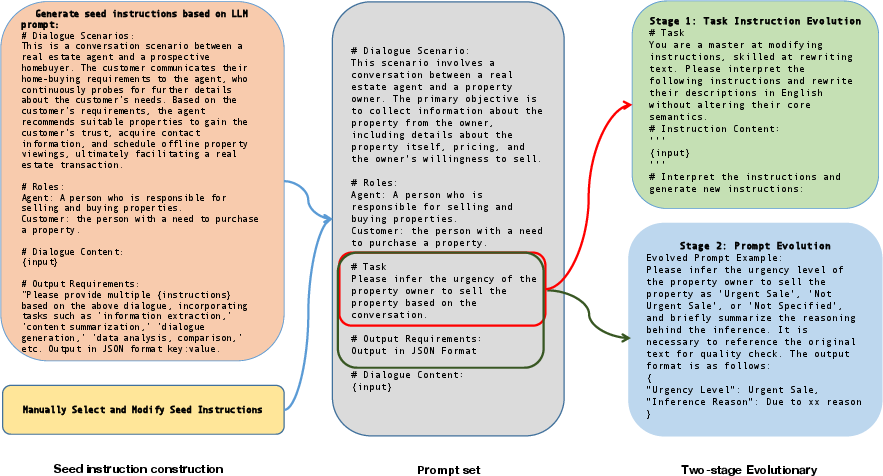
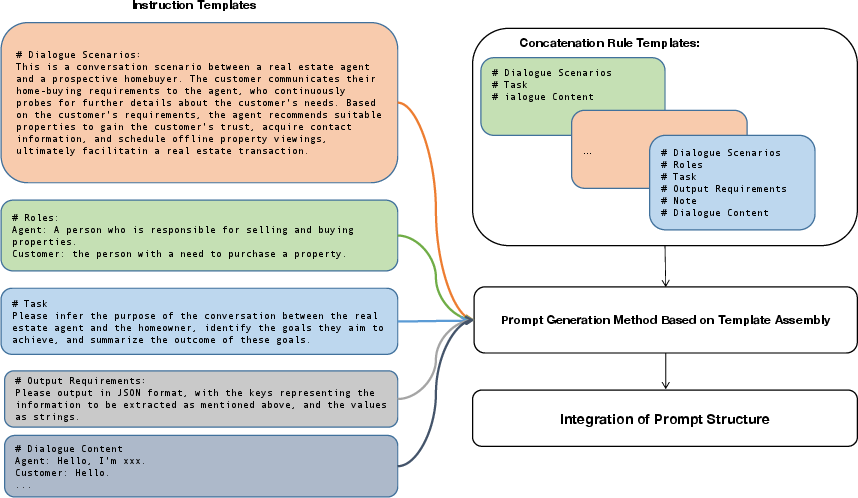
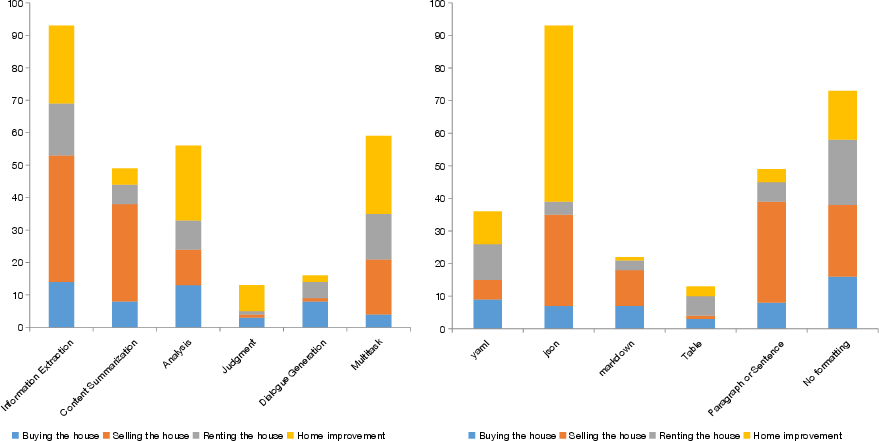
Abstract: The efficacy of LLMs is heavily dependent on the quality of the underlying data, particularly within specialized domains. A common challenge when fine-tuning LLMs for domain-specific applications is the potential degradation of the model's generalization capabilities. To address these issues, we propose a two-stage approach for the construction of production prompts designed to yield high-quality data. This method involves the generation of a diverse array of prompts that encompass a broad spectrum of tasks and exhibit a rich variety of expressions. Furthermore, we introduce a cost-effective, multi-dimensional quality assessment framework to ensure the integrity of the generated labeling data. Utilizing a dataset comprised of service provider and customer interactions from the real estate sector, we demonstrate a positive correlation between data quality and model performance. Notably, our findings indicate that the domain-specific proficiency of general LLMs can be enhanced through fine-tuning with data produced via our proposed method, without compromising their overall generalization abilities, even when exclusively domain-specific data is employed for fine-tuning.
- Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
- Yi: Open foundation models by 01.ai.
- Qwen technical report. arXiv preprint arXiv:2309.16609.
- Shai: A large language model for asset management.
- Reinforcement learning from statistical feedback: the journey from ab testing to ant testing.
- Measuring massive multitask language understanding. Cornell University - arXiv,Cornell University - arXiv.
- C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. Advances in Neural Information Processing Systems, 36.
- Sajed Jalil. 2023. The transformative influence of large language models on software development. arXiv preprint arXiv:2311.16429.
- Mixtral of experts. arXiv preprint arXiv:2401.04088.
- Cmmlu: Measuring massive multitask language understanding in chinese. arXiv preprint arXiv:2306.09212.
- From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning. arXiv preprint arXiv:2308.12032.
- Csds: A fine-grained chinese dataset for customer service dialogue summarization. arXiv preprint arXiv:2108.13139.
- Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744.
- Wanjuan-cc: A safe and high-quality open-sourced english webtext dataset. arXiv preprint arXiv:2402.19282.
- Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv: Learning.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Self-instruct: Aligning language model with self generated instructions.
- Chathome: Development and evaluation of a domain-specific language model for home renovation. arXiv preprint arXiv:2307.15290.
- Wizardlm: Empowering large language models to follow complex instructions.
- Glm-130b: An open bilingual pre-trained model.
- When scaling meets llm finetuning: The effect of data, model and finetuning method. arXiv preprint arXiv:2402.17193.
- A survey of large language models. arXiv preprint arXiv:2303.18223.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.