- The paper introduces a large-scale slide-enriched audio-visual corpus that leverages multi-modal inputs to improve ASR accuracy.
- It details a structured creation pipeline involving candidate video search, segmentation, and validation with over 95% confidence in transcript alignment.
- The benchmark system employs a Contextualized CTC/AED model with contextual biasing, achieving a notable WER of 13.09% on the development set.
SlideSpeech: A Large-Scale Slide-Enriched Audio-Visual Corpus
Introduction
The paper "SlideSpeech: A Large-Scale Slide-Enriched Audio-Visual Corpus" (2309.05396) addresses the challenge of enhancing Automatic Speech Recognition (ASR) models by exploiting multi-modal inputs, particularly focusing on textual information from slides in online conference scenarios. This study fills a gap in leveraging real-time synchronized slides that accompany audio presentations, by compiling the SlideSpeech corpus comprising 1,705 videos over 1,000 hours and implementing benchmark systems utilizing this textual information.
Corpus Development
Creation Pipeline
A structured pipeline is introduced for constructing the SlideSpeech corpus, which involves several stages: candidate video searching, segment generation, and validation.
- Candidate Video Searching: Content is sourced primarily from YouTube, targeting playlists indicative of educational or conference material, ensuring over 50% of video content corresponds to slide presentations. The videos are downloaded using
yt-dlp.
- Candidate Segments Generation: Using state-of-the-art in-house VAD and ASR systems, segmented video content is transcribed. This ASR system is highly accurate, with scores exceeding 95%.
- Candidate Validation: Validation employs YouTube subtitle files and an ASR-generated transcript, using the Smith-Waterman algorithm for aligning subtitles with transcript segments to calculate a confidence metric. Segments with greater than 95% confidence form the L95 subset.
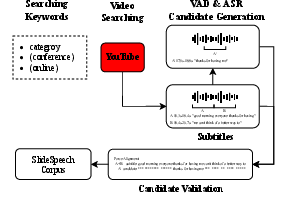
Figure 1: Diagram of our Creation pipeline.
Corpus Characterization
SlideSpeech exhibits considerable diversity, covering 22 domain categories including computer science, history, and musical instruments, ensuring its relevance for developing generalized ASR models (Table \ref{diversity}).
Benchmark System
Pipeline and Contextual Bias ASR
The core pipeline for multi-modal ASR comprises text detection and OCR for extracting slide text to use as contextual input for ASR. The proposed benchmark system employs the Contextualized CTC/AED model, integrating a context encoder and a biasing layer using multi-head attention mechanisms to enrich speech embeddings with context from slide text.
The contextual ASR model utilizes a bias list generated via keyword extraction from OCR text for training, along with a simulation approach for enriching the contextual biasing list.

Figure 2: Diagram of our benchmark pipeline.
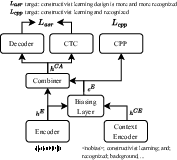
Figure 3: Diagram of Contextualized CTC/AED Model.
Results and Discussion
Evaluations in terms of WER, U-WER, and B-WER demonstrate that SlideSpeech effectively improves ASR performance, particularly for recognizing specialized terms. The baseline model trained on L95 achieved a notable WER of 13.09% on the development set, with contextual ASR exhibiting even lower error rates when leveraging keyword biasing lists, emphasizing the importance of slide text in correcting recognition errors.
These empirical results underline the ability of text-enhanced ASR systems to correct misrecognized proprietary terms, facilitated by keyword extraction and effective contextual biasing mechanisms.

Figure 4: Qualitative results on the SlideSpeech dataset. The ground truth (GT), audio-only baseline (A), and benchmark system (AV) are depicted with errors and corrections highlighted.
Conclusion
The SlideSpeech corpus offers crucial insights into multi-modal ASR improvements through comprehensive integration of slide text information. The benchmark system showcased quantifiable improvements in recognition accuracy through targeted contextual ASR strategies. The study sets a precedent for further exploration into optimizing ASR systems for multi-modal data environments, providing a robust foundation for future research and application developments.

