Paper2Video: Automatic Video Generation from Scientific Papers
Abstract: Academic presentation videos have become an essential medium for research communication, yet producing them remains highly labor-intensive, often requiring hours of slide design, recording, and editing for a short 2 to 10 minutes video. Unlike natural video, presentation video generation involves distinctive challenges: inputs from research papers, dense multi-modal information (text, figures, tables), and the need to coordinate multiple aligned channels such as slides, subtitles, speech, and human talker. To address these challenges, we introduce PaperTalker, the first benchmark of 101 research papers paired with author-created presentation videos, slides, and speaker metadata. We further design four tailored evaluation metrics--Meta Similarity, PresentArena, PresentQuiz, and IP Memory--to measure how videos convey the paper's information to the audience. Building on this foundation, we propose PaperTalker, the first multi-agent framework for academic presentation video generation. It integrates slide generation with effective layout refinement by a novel effective tree search visual choice, cursor grounding, subtitling, speech synthesis, and talking-head rendering, while parallelizing slide-wise generation for efficiency. Experiments on Paper2Video demonstrate that the presentation videos produced by our approach are more faithful and informative than existing baselines, establishing a practical step toward automated and ready-to-use academic video generation. Our dataset, agent, and code are available at https://github.com/showlab/Paper2Video.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a way to automatically turn a scientific paper into a full presentation video. The system, called PaperTalker, can create slides, subtitles, spoken narration in the author’s voice, a talking presenter (face and upper body), and even a moving cursor that points to the right parts of the slide—without a person having to record and edit everything by hand.
The authors also built a new benchmark, Paper2Video, with around 100 real papers paired with their author-made presentation videos and slides, so they can test how good the automatic videos are.
What questions are the researchers trying to answer?
In simple terms, they ask:
- Can we make good presentation videos automatically from scientific papers?
- How do we judge if these videos actually teach the audience well and represent the authors’ work?
- What features (slides, subtitles, speech, cursor, presenter) matter most for making a clear, engaging academic video?
How does the system work?
Think of this like building a school presentation from a big, complicated textbook:
- The paper is a long, detailed document with text, figures, and tables.
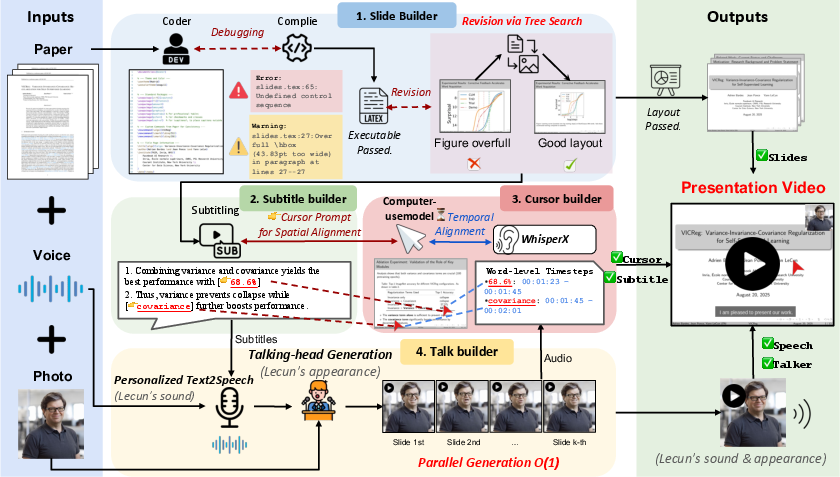
- The system breaks the job into several “mini-teams” (agents), each handling a part:
- Slide builder: Creates clean, academic-style slides using LaTeX Beamer. LaTeX is a “document coding” language many scientists use to make precise, professional slides. If there’s an error when turning code into slides, it fixes it. For layouts, it uses a smart try-and-choose method (Tree Search Visual Choice): it tries different font sizes and figure scales, renders several versions, and asks a vision-LLM (an AI that understands images and text) to pick the one that looks best. This is like testing multiple slide designs and letting a very attentive judge choose the clearest one.
- Subtitle builder: Looks at each slide and writes simple, sentence-level subtitles that explain what’s on the slide. It also produces “visual focus prompts” that describe where the viewer should look on the slide.
- Cursor builder: Turns those “look here” prompts into exact positions for a mouse cursor to point at, and matches the timing so the cursor highlights the right spot while the sentence is spoken. Think of this as an automatic laser pointer that moves at the right time.
- Talker builder: Generates speech from the subtitles using the author’s voice sample and creates a talking-head video that looks like the author is presenting. It can animate face and upper body with lip-sync.
To make it faster, the system generates content for each slide in parallel, like having several helpers work on different slides at the same time. That gives more than a 6× speedup.
How do they evaluate the videos, and what did they find?
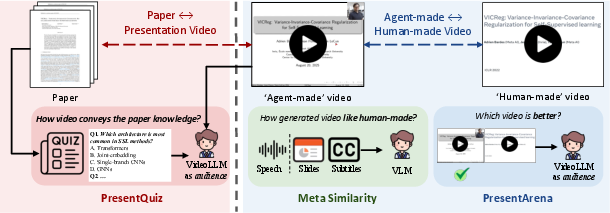
Because a good academic video isn’t just “pretty”—it should teach well—they use four custom tests:
- Meta Similarity: How close are the auto-generated slides/subtitles/speech to the real ones made by the authors? They use AI to score slide+subtitle pairs and compare voice features for speech similarity.
- PresentArena: An AI “viewer” watches pairs of videos (auto vs. human-made) and picks which one is better in clarity, delivery, and engagement.
- PresentQuiz: The AI watches the video and answers multiple-choice questions based on the paper. Higher accuracy means the video conveyed the paper’s information well.
- IP Memory: Does the video help the audience remember the authors and their work? This simulates how memorable and identity-focused the presentation is.
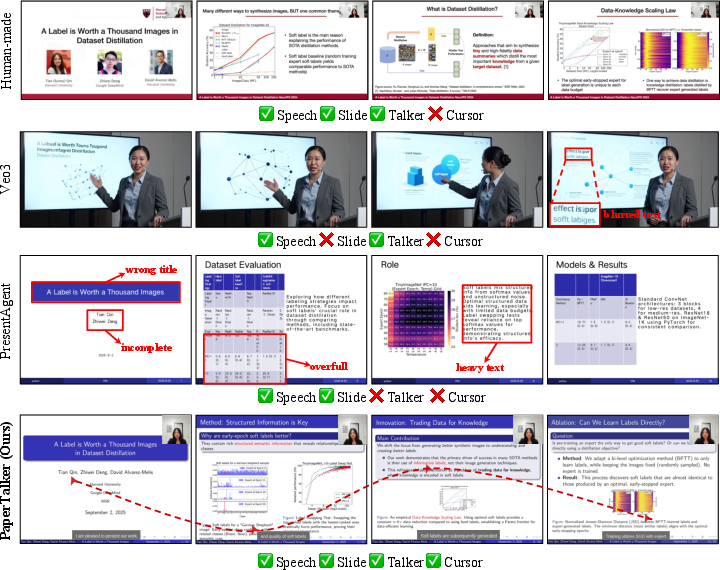
Main results:
- The PaperTalker system produced videos that matched human-made content closely and were judged clearer and more informative than other baseline methods.
- In quizzes, its videos even scored about 10% higher than human-made ones on certain information coverage tests, meaning they helped AI viewers learn the paper’s details effectively.
- Adding a presenter and a cursor improved results further: the talking-head presenter made the video more memorable, and the cursor made it easier to follow what’s being discussed.
- The system is efficient: slide-wise parallel generation made the whole process more than six times faster.
Why does this matter?
Making a good academic presentation video by hand takes hours: designing slides, recording speech, syncing subtitles, and editing. This research shows it’s possible to automate most of that work while keeping quality high. That can help:
- Researchers share their work faster and more widely.
- Students and conference attendees learn more clearly from videos that are well structured and easy to follow.
- Conferences and journals provide consistent, accessible presentation materials.
By open-sourcing the dataset and code, the authors also give the community tools to improve and build on this idea, moving toward a future where creating clear, helpful academic videos is fast, easy, and available to everyone.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored, framed as concrete, actionable gaps for future work.
- Benchmark coverage: only 101 AI-conference papers; unclear generalization to other domains (e.g., biology, physics, clinical research), longer papers (e.g., theses), or non-technical audiences.
- Input modality constraint: pipeline presumes access to the paper’s LaTeX project; no support for PDF-only inputs, scanned PDFs, or non-LaTeX authoring formats common outside CS.
- Slide reference scarcity: original slides available for only ~40% of samples, limiting strong reference-based evaluation and ablations tied to ground-truth slide design.
- Domain/style diversity: no examination of robustness to math-heavy content (dense equations), highly visual disciplines (microscopy, medical imaging), or code-heavy demonstrations.
- Dataset ethics/compliance: unclear consent, licensing, and platform ToS compliance for using/scraping author portraits, voices, and presentation assets; no documented data governance.
- Bias and representativeness: no analysis of demographic balance (gender, ethnicity, accent) among speakers or topical balance across subfields; fairness impacts unassessed.
- Longitudinal validity: no plan for benchmark updates to reflect evolving conferences, formats (e.g., lightning talks), or new modalities (interactive demos).
- Metric validity (VLM/VideoLLM dependence): heavy reliance on proprietary models as evaluators without thorough validation against expert human judgments at scale.
- Human correlation: missing correlation analysis between automated metrics (Meta Similarity, PresentArena, PresentQuiz, IP Memory) and large-sample human comprehension/usability studies.
- PresentQuiz construction: questions and answers are LLM-generated and LLM-answered; risks of leakage/format bias/shortcut exploitation not audited; no human-vetted ground truth sets.
- PresentArena reliability: pairwise preferences from a single VideoLLM (with double ordering) may still carry model-specific biases; no cross-model triangulation or statistical reliability analysis.
- Meta Similarity scope: slide+subtitle similarity judged by VLM does not measure factual correctness, coverage completeness, or logical flow; 10-second audio embedding may miss prosody/intelligibility.
- IP Memory metric: conceptualization and implementation details are deferred to the appendix; no evidence it predicts real-world author/work recall or scholarly impact among human audiences.
- Metric robustness: no stress tests on adversarial or near-duplicate content; no analysis of metric stability across model/version drift of evaluator LLMs/VideoLLMs.
- End-to-end fairness of baselines: strong generative baselines (e.g., Veo3, Wan) are prompt-limited and duration-constrained; comparisons may not reflect their best attainable performance.
- Reproducibility: core results depend on closed-source GPT-4.1/Gemini-2.5; open-model variants are partially reported or missing; prompts and seeds for evaluators are not fully disclosed.
- Cost accounting: monetary cost excludes GPU compute for TTS/talking-head and video rendering; no full-cost, wall-clock, and energy accounting across hardware profiles.
- Slide generation fidelity: figure selection, equation handling, and citation/number preservation accuracy are not quantitatively audited; factual slide errors are not systematically measured.
- Layout optimization scope: Tree Search Visual Choice adjusts only a few numeric parameters (font/scale); lacks global slide-deck coherence, color/contrast accessibility, and multi-objective layout optimization.
- Cross-slide coherence: slide-wise parallel generation ignores narrative continuity, consistent visual theming, and progressive revelation design; no modeling of cross-slide transitions or story flow.
- Cursor grounding simplification: assumption of one static cursor position per sentence is unrealistic; no modeling of within-sentence motion, laser-pointer trajectories, or gaze alignment.
- Grounding evaluation: cursor benefits shown via VLM localization QA; missing human eye-tracking/user studies and comparisons to human cursor traces for timing/position accuracy.
- Subtitle generation limits: subtitles derived from slides may omit necessary details from the paper; no checks for hallucinations, omissions, or misalignment with the paper’s true contributions.
- Presenter realism: talker lip-sync and prosody naturalness are not quantitatively evaluated; no metrics for speaker expressiveness, emotion, or co-speech gesture appropriateness.
- Personalization depth: only face/voice cloning; no control over speaking rate, emphasis, pause placement, or adaptive simplification for diverse audience expertise levels.
- Multilinguality and accents: method and benchmark are English-centric; no support or evaluation for multilingual TTS/subtitles, code-switching, or accent robustness.
- Accessibility: no audits for color contrast, font legibility at typical recording resolutions, subtitle readability, or accommodations for hearing/vision-impaired audiences.
- Ethical safeguards: no documented consent framework, watermarking, anti-impersonation protections, or provenance tracking for synthetic voice/face generation.
- Failure analysis: limited qualitative failures are shown; no systematic taxonomy of error modes (semantic omissions, factual mistakes, timing mismatches, layout failures) with frequencies.
- Robustness to long-horizon content: no scaling analysis for talks >15 minutes or >30 slides; queueing/fault tolerance for long runs and recovery from compilation/rendering failures is unspecified.
- Interaction and demos: no support for live demos, embedded animations, or code run-throughs that many technical talks require.
- User control: limited interface for authors to constrain style, theme, slide templates, or to inject must-include figures/tables; no iterative human-in-the-loop editing workflow quantified.
- Generalization beyond academic talks: applicability to educational lectures, industry tech talks, or public outreach videos (different tone/structure) is not assessed.
- Security and privacy: pipeline risk assessment (model calls, sensitive manuscripts, embargoed content) and mitigation strategies are not described.
- Licensing and release: dataset/code/weights release plan lacks detailed licensing, redaction of PII, or procedures for takedown/opt-out by authors featured in the benchmark.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can be built with the paper’s released dataset, agent, and codebase (Paper2Video benchmark and the PaperTalker multi-agent system).
- Academic presentation auto-generation for conference submissions
- Sectors: academia, software (tools), publishing
- What/How: Convert a LaTeX or PDF paper into a 2–10 minute beamer-style slide deck, synchronized subtitles, personalized TTS, cursor highlights, and a talking-head presenter; slide-wise parallel generation yields 6× throughput.
- Potential tools/workflows: “Submit-and-generate” module integrated into OpenReview/SlidesLive; Overleaf add-on to compile “Video Abstract” from the paper project; arXiv plug-in for auto video abstracts.
- Assumptions/dependencies: Author consent for voice/face cloning; availability of LaTeX/PDF and a short voice sample/photo; GPU capacity; institutional policies on synthetic media.
- Video abstracts at scale for journals, preprint servers, and society conferences
- Sectors: publishing, science communication, education
- What/How: Batch-generate standardized video abstracts with the paper’s figures/tables and cursor guidance; evaluate quality with Meta Similarity and PresentQuiz.
- Potential tools/workflows: Publisher CMS pipeline to auto-generate and host video abstracts; automated quality gate using PresentArena and PresentQuiz before release.
- Assumptions/dependencies: Content licensing; multilingual TTS availability if cross-lingual delivery is needed; VLM-based evaluation reliability.
- Institutional repositories and lab websites: automatic “Talk” pages
- Sectors: academia, R&D
- What/How: Each paper in a lab’s repository is paired with an auto-generated talk in the lab’s voice/branding; IP Memory metric used to A/B test thumbnail/avatar designs that boost recall.
- Potential tools/workflows: CI/CD for research websites that runs PaperTalker on new publications; analytics dashboard using IP Memory-style recall proxies.
- Assumptions/dependencies: Consent management; branding templates and LaTeX themes defined; storage and streaming infra.
- Corporate R&D knowledge dissemination and onboarding content
- Sectors: enterprise software, finance, pharma, energy, manufacturing
- What/How: Convert internal technical docs, RFCs, design notes, and model cards into short presentation videos with cursor-grounded highlights for faster onboarding and cross-team briefings.
- Potential tools/workflows: “Doc-to-briefing” bot in Slack/Teams; internal portal that auto-renders narrated walkthroughs of newly merged design docs.
- Assumptions/dependencies: Document structure parsers for non-LaTeX formats; data security and on-prem deployment; model guardrails to reduce hallucinations.
- Course micro-lectures and flipped-classroom content from papers
- Sectors: education, EdTech
- What/How: Generate short, slide-based lectures with personalized instructor avatars and TTS; use PresentQuiz to auto-create comprehension checks.
- Potential tools/workflows: LMS integration (Moodle/Canvas) to generate/attach mini-lectures and quizzes; instructor batch pipelines for weekly reading summaries.
- Assumptions/dependencies: Fair use and permission for paper figures; voice/face consent; institutional accessibility requirements (captions, contrast).
- Scientific outreach and public explainer videos
- Sectors: media, non-profits, government outreach
- What/How: Produce accessible explainers of complex papers with concise slides, subtitles, voiceovers, and cursor to guide attention.
- Potential tools/workflows: Science communication teams run a “press-brief-to-video” workflow; social-ready cuts with chapterization.
- Assumptions/dependencies: Simplification layer/prompting for lay audiences; branding and editorial review to mitigate misinterpretation.
- Enhanced accessibility of talks (captioning + cursor grounding)
- Sectors: accessibility, education, public sector
- What/How: WhisperX-aligned subtitles and explicit cursor focus improve cognitive tracking for viewers, including those with hearing or attention challenges.
- Potential tools/workflows: “Accessibility upgrade” pass for existing slide decks; compliance reports per video.
- Assumptions/dependencies: Accurate ASR alignment; high-contrast cursor and WCAG-compliant templates.
- Automated slide quality refinement for academic beamer decks
- Sectors: software tooling, desktop publishing
- What/How: Apply Tree Search Visual Choice to resolve overflow and optimize figure/font sizing; integrate into LaTeX build systems.
- Potential tools/workflows: Overleaf/VS Code extension that proposes layout variants and VLM-picked best candidate.
- Assumptions/dependencies: Stable LaTeX toolchain; VLM’s visual judgment aligns with user preferences.
- Evaluation-as-a-service for presentation quality
- Sectors: tooling, publishing, education
- What/How: Offer Meta Similarity, PresentArena, PresentQuiz, and IP Memory as automated metrics for talk quality, knowledge coverage, and memorability.
- Potential tools/workflows: “Presentation QA” service for conferences/courses; analytics used to iteratively improve slide scripts and visuals.
- Assumptions/dependencies: Reliability of VideoLLMs as proxy audiences; dataset/domain coverage beyond AI papers.
- Internal compliance and training videos from policy/standard documents
- Sectors: policy, healthcare, finance, energy, security
- What/How: Convert SOPs and regulatory updates into guided, cursor-highlighted walkthrough videos; auto-generate quizzes for mandatory training.
- Potential tools/workflows: HR/L&D pipeline that ingests updated policies weekly to produce short videos and assessments.
- Assumptions/dependencies: Accurate document parsing; legal review; secure deployment (on-prem).
- Developer documentation and API walkthroughs
- Sectors: software
- What/How: Turn READMEs and API specs into narrated, step-by-step video tutorials with cursor grounding; improve dev onboarding and self-service.
- Potential tools/workflows: CI job triggered on doc updates; docs site embeds videos; auto-generated PresentQuiz used as “Did you get it?” checks.
- Assumptions/dependencies: High-quality screenshots/figures or code-to-diagram tooling; model alignment to technical terminology.
- Grant proposal video summaries (PI pitches)
- Sectors: academia, government funding, non-profits
- What/How: Auto-generate a 2–3 minute summary pitch from the proposal with a personalized presenter to accompany submissions.
- Potential tools/workflows: Funding portal plug-in; lab-level content library for reuse.
- Assumptions/dependencies: Sponsor rules on AI media; privacy/consent; careful prompt controls to avoid overstating claims.
- Multi-lingual variants of presentations (where TTS supports it)
- Sectors: global education, publishing
- What/How: Use multilingual TTS to generate dubbed versions while reusing slides/cursor; extend reach of research talks.
- Potential tools/workflows: Language selection in generation UI; separate subtitle tracks; region-specific branding.
- Assumptions/dependencies: Quality of multilingual TTS; translation accuracy and terminology consistency.
Long-Term Applications
These require further research, scaling, broader model support, or policy/ethics frameworks before widespread deployment.
- End-to-end long-form, multi-shot tutorial and course generation
- Sectors: EdTech, enterprise L&D
- What/How: Extend beyond slide-bounded segments to coherent, multi-module courses with scene changes, demos, and labs; harmonize talker across modules.
- Dependencies: More robust long-context video generation; memory and continuity across slides; better cost/performance.
- Interactive presentation agents with retrieval, Q&A, and adaptive pacing
- Sectors: education, product support, developer tooling
- What/How: Video “presenter” that pauses for embedded questions, answers with citations to the paper, and adjusts explanations based on viewer feedback.
- Dependencies: Reliable grounding and on-the-fly retrieval; latency budgets for real-time interaction; UX for turn-taking and assessment.
- General “document-to-video” platform for enterprise knowledge (beyond LaTeX)
- Sectors: all industries
- What/How: Robust pipelines for Word, Google Docs, Confluence, Notion, and Markdown to rich video explainers with diagrams and cursor-guided flows.
- Dependencies: High-fidelity parsers and figure extraction; layout synthesis from noisy documents; security and governance.
- Regulatory-grade consent, watermarking, and provenance for synthetic presenters
- Sectors: policy, legal, media
- What/How: Consent workflows, tamper-resistant provenance (C2PA), and detectable watermarks for talker videos; compliance dashboards.
- Dependencies: Standards adoption; integration with identity/consent platforms; evolving deepfake legislation.
- Marketing and outreach optimization using “IP Memory” metrics
- Sectors: publishing, media, enterprise marketing
- What/How: Systematically optimize thumbnails, intros, and avatar styles to maximize recall and brand association, guided by IP Memory-style metrics.
- Dependencies: Validated correlation between proxy metrics and real-world impact; ethical A/B testing frameworks.
- Multimodal design copilots for scientific visuals and dense-text layouts
- Sectors: publishing tech, design tooling
- What/How: Expand Tree Search Visual Choice into a general-purpose visual-layout agent for posters, figures, and reports that iterates via render-and-select loops.
- Dependencies: Faster render cycles; more accurate VLM aesthetic/legibility judgments; domain-specific design priors.
- Real-time teleprompter and cursor assistant for human presenters
- Sectors: events, education, broadcast
- What/How: Live system that infers focus points on slides, suggests cursor highlights, and adapts subtitles/pace; presenter retains control.
- Dependencies: Low-latency speech understanding and grounding; ergonomic UI; reliability in live settings.
- Cross-lingual, cross-cultural science communication at scale
- Sectors: global health, international development, NGOs
- What/How: Tailor technical content into culturally adapted explainer videos per region/language with localized examples.
- Dependencies: Domain adaptation; high-quality translation and localization; partnerships for distribution and evaluation.
- Compliance-grade transformation of regulated documents to training videos
- Sectors: healthcare, finance, aviation, energy
- What/How: Certifiable conversion of standards/guidelines into training videos with traceable alignment to source clauses.
- Dependencies: Formal verification of coverage (PresentQuiz-style metrics tied to clauses); audit trails; regulator acceptance.
- Multispeaker panels and debate-style auto-generated presentations
- Sectors: media, education
- What/How: Generate panel discussions or debates summarizing contrasting papers, with avatars representing different viewpoints.
- Dependencies: Multi-agent dialogue planning; consistency of identities; managing bias and misrepresentation.
- Assistive learning analytics and personalization
- Sectors: EdTech
- What/How: Combine PresentQuiz with viewer interaction to adapt content difficulty and sequencing; produce personalized recap videos.
- Dependencies: Learner modeling; privacy-compliant analytics pipelines; longitudinal efficacy studies.
Cross-cutting assumptions and dependencies
- Model stack quality and licensing: Availability and cost of VLMs, VideoLLMs, TTS (e.g., F5), talking-head (e.g., Hallo2/FantasyTalking), ASR (WhisperX), and UI grounding; commercial licenses for deployment.
- Content availability and format: Best results with LaTeX Beamer or structured PDFs; non-LaTeX documents may need robust parsers or templates.
- Identity and ethics: Explicit consent for voice/face cloning; watermarking/provenance; adherence to institutional and legal policies on synthetic media.
- Compute and scalability: GPU resources for video synthesis; cost constraints for batch generation at publisher or enterprise scale.
- Reliability and safety: VLM/VideoLLM evaluation robustness; mitigation of hallucinations and inaccuracies; human-in-the-loop review for high-stakes content.
- Domain generalization: Paper2Video is curated from AI conferences; applying to other domains may require fine-tuning or domain-specific prompts/templates.
Glossary
- Ablation: An analysis method where components are removed or varied to assess their impact on performance. "Ablation study on cursor."
- Attentional anchor: A visual cue used to guide viewer attention to relevant content during a presentation. "a cursor indicator serves as an attentional anchor, helping the audience focus and follow the narration."
- Beamer: A LaTeX class for creating academic-style slides with structured, declarative layout. "We adopt Beamer for three reasons:"
- Chain-of-Thought (CoT) planning: A strategy where agents plan through step-by-step reasoning to organize complex tasks. "MovieAgent~\cite{wu2025automated} adopts a hierarchical CoT planning strategy"
- CLIP-based similarity: A metric using CLIP embeddings to measure how closely visual and textual content align. "e.g., FVD, IS, or CLIP-based similarity"
- Cosine similarity: A measure of similarity between two vectors (e.g., embeddings) based on the cosine of the angle between them. "compute the cosine similarity between the embeddings"
- Cursor grounding: Mapping textual or spoken references to precise on-screen cursor positions aligned with timing. "a GUI-grounding model coupled with WhisperX for spatial-temporal aligned cursor grounding"
- Declarative typesetting: A specification-driven layout approach where the system determines placement from parameters rather than explicit coordinates. "LaTeX’s declarative typesetting automatically arranges text block and figures"
- Diffusion models: Generative models that synthesize media by iteratively denoising from noise, widely used for images and videos. "Recent advances in video diffusion models~\cite{sd_video,wan,vbench,vbench++} have substantially improved natural video generation"
- Double-order pairwise comparisons: A robust evaluation where two items are compared in both orderings to mitigate bias. "perform double-order pairwise comparisons between generated and human-made videos."
- FVD: Frechet Video Distance, a metric for evaluating video generation quality by comparing feature distributions. "e.g., FVD, IS, or CLIP-based similarity"
- GUI-grounding: Aligning model actions or pointers to graphical user interface elements based on visual understanding. "a GUI-grounding model coupled with WhisperX for spatial-temporal aligned cursor grounding"
- IP Memory: A metric assessing how effectively a presentation helps audiences recall authors and their work (intellectual property). "we introduce (iv) IP Memory, which measures how well an audience can associate authors and works after watching presentation videos."
- LaTeX: A typesetting system commonly used for academic documents and slides. "we employ LaTeX code for slide generation from sketch"
- Long-context inputs: Inputs comprising lengthy, dense documents requiring models to process extended sequences across modalities. "long-context inputs from research papers"
- Multi-agent framework: A system composed of specialized cooperating agents that handle different subtasks to achieve a complex goal. "we propose PaperTalker, the first multi-agent framework for academic presentation video generation."
- Multi-image conditioning: Guiding generative models using multiple images as context or constraints. "enable multi-image conditioning."
- Overfull layout issues: LaTeX/slide rendering problems where content exceeds the allocated space, causing overflow. "suffers from overfull layout issues and inaccurate information"
- Pairwise winning rate: The percentage of times a method's output is preferred over another in pairwise comparisons. "attains the highest pairwise winning rate among all baselines"
- PresentArena: An evaluation where a VideoLLM acts as a proxy audience to judge which presentation video is better. "PresentArena — We use a VideoLLM as a proxy audience to perform double-order pairwise comparisons between generated and human-made videos."
- PresentQuiz: A quiz-based metric measuring how well a presentation conveys paper knowledge to an audience model. "we introduce (iii) PresentQuiz, which treats the VideoLLMs as the audience and requires them to answer paper-derived questions given the videos."
- Rasterize: Convert vector or PDF slide content into pixel images for downstream processing. "we rasterize them into images"
- Reflow: Automatic rearrangement of content when layout parameters change to maintain coherent formatting. "structured syntax automatically reflows content as parameter changes."
- Spatial-temporal alignment: Coordinating spatial positions (e.g., cursor) with timing from speech/subtitles for synchronized guidance. "achieve cursor spatial-temporal alignment"
- Talking-head rendering: Generating a video of a presenter’s face/head synchronized to speech for delivery. "subtitling, speech synthesis, and talking-head rendering"
- Text-to-speech (TTS): Synthesizing speech audio from text, optionally conditioned on a speaker’s voice. "merely combines PPTAgent with text-to-speech to produce narrated slides."
- Tree Search Visual Choice: A layout refinement method that generates multiple visual variants and selects the best using a VLM’s judgment. "we propose a novel method called Tree Search Visual Choice."
- UI-TARS: A model for grounding and interacting with user interfaces to locate or manipulate on-screen elements. "by UI-TARS~\cite{qin2025ui}"
- VideoLLM: A LLM augmented with video understanding capabilities for evaluation or reasoning over videos. "We use a VideoLLM as a proxy audience"
- VideoQA: Video question answering; evaluating understanding by asking questions about video content. "We conduct a VideoQA evaluation."
- VLM (Vision-LLM): A model that jointly understands visual and textual inputs for tasks like evaluation and generation. "We employ a VLM to evaluate the alignment of generated slides and subtitles with human-designed counterparts."
- Visual-focus prompt: A textual cue specifying which region or element on a slide the narration refers to, used for cursor grounding. "its corresponding visual-focus prompt ."
- WhisperX: A tool for accurate speech transcription with word-level timestamps for alignment in long-form audio. "we then use WhisperX~\cite{bain2023whisperx} to extract word-level timestamps"
- Word-level timestamps: Precise timing information for each word in audio, enabling fine-grained synchronization. "extract word-level timestamps"
Collections
Sign up for free to add this paper to one or more collections.

