- The paper proposes a semi-parametric framework using a persistent memory to improve LLM-driven reinforcement learning agents.
- It employs the RLEM pipeline to incorporate past experiences into in-context learning, yielding up to a 4% performance boost across benchmarks.
- Ablation studies confirm that n-step bootstrapping and the use of discouraged actions are key to preventing repetitive failures and ensuring consistency.
LLMs Are Semi-Parametric Reinforcement Learning Agents
Introduction
The paper "LLMs Are Semi-Parametric Reinforcement Learning Agents" (2306.07929) introduces Rememberer, an LLM-based agent framework designed to enhance decision-making capabilities by integrating a long-term experience memory. Unlike LLM agents with transient working memory, Rememberer leverages Reinforcement Learning with Experience Memory (RLEM) to update and utilize past interaction experiences without fine-tuning model parameters, positioning itself as a semi-parametric RL agent. The experimental findings indicate that Rememberer outperforms state-of-the-art benchmarks by 4% and 2% in success rates across two task sets.
Methodology
RLEM Pipeline
RLEM enables LLM agents to learn from interaction experiences via a persistent external memory, contrasting traditional RL approaches that primarily modify model parameters.
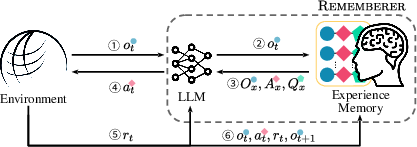
Figure 1: Pipeline of RLEM and architecture of Rememberer.
Experience Memory
The experience memory maintains a record of task information, observations, actions, and associated Q value estimations, treated as non-parametric augmentations to the LLM. Experiences are sourced from interactions with the environment, recorded without exhaustive explorations due to limited training trajectories.
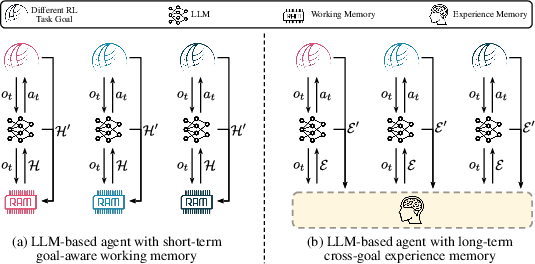
Figure 2: Comparison of the LLM-based agents with short-term working memory and long-term experience memory.
Usage of Experience
Stored experiences serve as dynamic exemplars for few-shot in-context learning. The memory is queried based on task and observation similarity functions to construct prompts that guide LLM decision-making through encouraged and discouraged action forecasts.

Figure 3: Exemplar for WebShop. YAML markups are adopted to avoid confusing the keywords like ``Observation:'' with the colon-ended titles in the page representation.
Experimental Results
Task Setup
Evaluations on WebShop and WikiHow task sets employed GPT-3.5 (text-davinci-003) API for implementation. Experiments demonstrated a significant performance increase, affirming the efficacy of equipping LLMs with a persistent memory to exploit interaction experiences.
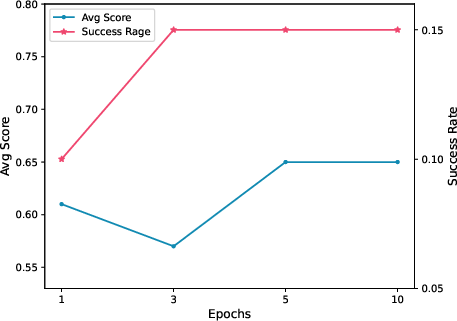
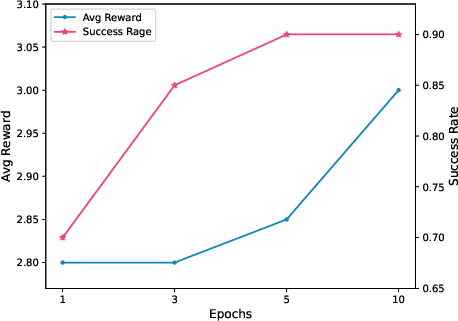
Figure 4: Capability evolving on WebShop.
Performance Metrics
In WebShop, Rememberer attained an average score of 0.68 with a 0.39 success rate, surpassing both previous SOTA methodologies and RL/IL benchmarks. On WikiHow, Rememberer achieved a 2.63 average reward and 0.93 success rate.
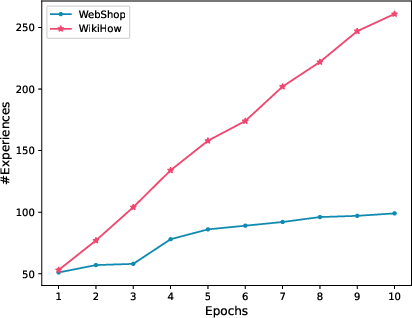
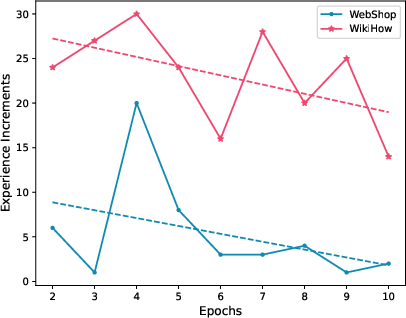
Figure 5: Number of experiences in each training epoch.
Ablation Studies
Multiple ablation studies corroborated the pivotal role of n-step bootstrapping in refining Q value estimations, denoting improved agent decision-making consistency. The inclusion of discouraged actions in feedback further proved crucial in preventing repetitive failures.
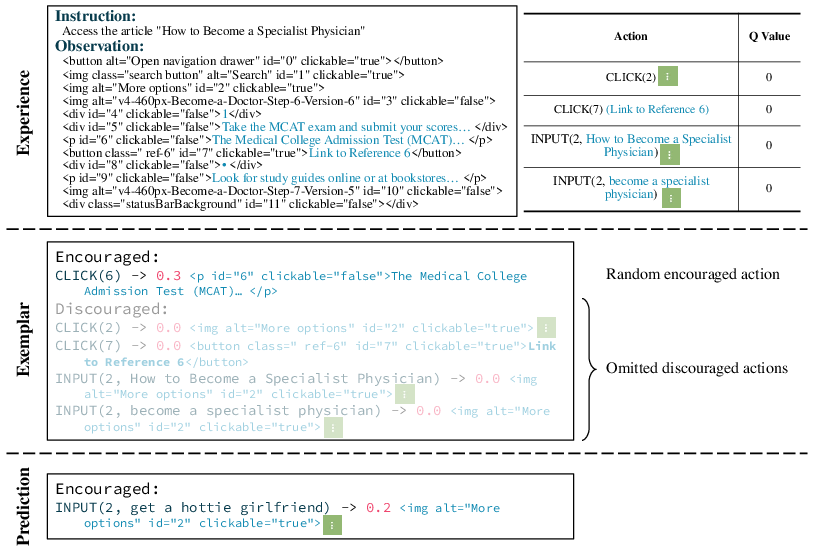
Figure 6: Case of the ablation study on the discouraged actions. As there are no valuable actions to encourage in the experience, a random action is generated. When the discouraged actions with low value are omitted, the LLM may repeat the failure with the same pattern.
Implications and Future Work
The Rememberer framework prescribes a scalable alternative to fine-tuning-intensive RL implementations for LLM-based agents, enhancing efficiency through persistent memory utilization. Future research should adapt Rememberer to environments with extensive observation and elaborate the integration of contemporary RL techniques under RLEM.
Conclusion
The paper advances the paradigm of semi-parametric LLM agents, demonstrating compelling performance enhancements through structured memory integration, positioning Rememberer as a robust framework for decision-making tasks reliant on episodic memory akin to human cognitive processes.