- The paper introduces a unified video completion framework that handles arbitrary spatio-temporal synthesis through a novel hybrid conditioning strategy.
- It employs spatial zero-padding and Temporal RoPE interpolation to decouple spatial and temporal conditioning, achieving precise alignment and content fidelity.
- Empirical results show that VideoCanvas outperforms traditional methods in reference fidelity, temporal coherence, and creative video editing capabilities.
Unified Spatio-Temporal Video Completion via In-Context Conditioning: An Analysis of VideoCanvas
Introduction
The paper "VideoCanvas: Unified Video Completion from Arbitrary Spatiotemporal Patches via In-Context Conditioning" (2510.08555) introduces a novel framework for video generation that unifies a broad spectrum of controllable video synthesis tasks under a single paradigm. The core contribution is the formalization and solution of arbitrary spatio-temporal video completion, where a model generates coherent videos from user-specified patches at any spatial location and timestamp. This approach subsumes prior rigid formats—such as first-frame image-to-video, inpainting, outpainting, and video extension—into a flexible, generalizable system. The authors address the fundamental challenge of temporal ambiguity in causal VAEs by proposing a hybrid conditioning strategy that decouples spatial and temporal control, leveraging In-Context Conditioning (ICC) with zero new parameters.

Figure 1: VideoCanvas enables arbitrary spatio-temporal video completion, filling in missing regions from user-specified patches or frames.
Task Definition
Arbitrary spatio-temporal video completion is defined as generating a video X^ from a set of user-provided spatio-temporal conditions P={(pi,mi,ti)}i=1M, where each pi is an image, mi is a spatial mask, and ti is a timestamp. The model must satisfy X^[ti]⊙mi≈pi for all i, while completing unconditioned regions with plausible content.
Hybrid Conditioning Strategy
The principal technical challenge arises from causal VAEs, which compress multiple pixel frames into a single latent slot, introducing ambiguity in frame-level conditioning. The proposed solution is a hybrid strategy:
- Spatial Conditioning: Conditional patches are placed on a full-frame canvas with zero-padding, then encoded independently by a frozen VAE. Empirical analysis (see Figure 2) demonstrates that spatial zero-padding is well-tolerated by hybrid video VAEs, preserving content fidelity in non-zero regions.

Figure 2: Hybrid video VAEs robustly reconstruct images with large spatial zero-padded regions, enabling precise spatial control.
- Temporal Conditioning: Temporal ambiguity is resolved via Temporal RoPE Interpolation, which assigns each conditional token a fractional temporal position ti/N (where N is the VAE stride). This enables fine-grained alignment of conditional frames within the latent sequence, circumventing the limitations of integer-only slot assignment.
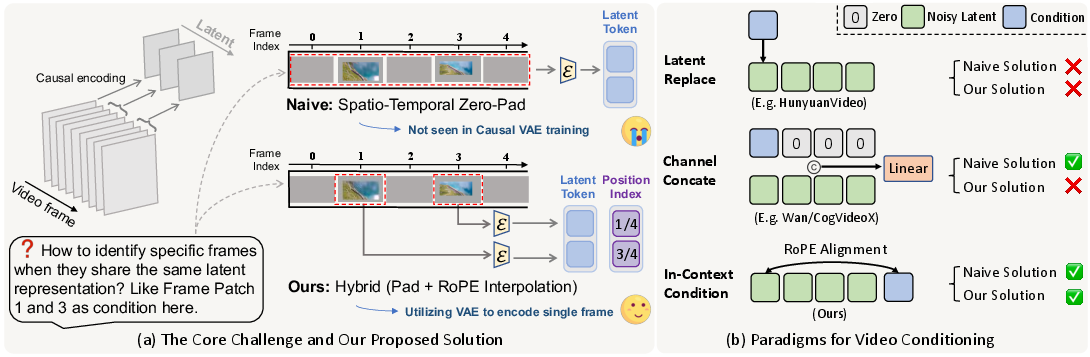
Figure 3: Temporal ambiguity in causal VAEs is resolved by combining spatial padding and Temporal RoPE Interpolation for pixel-frame-aware conditioning.
In-Context Conditioning (ICC) Pipeline
The ICC paradigm treats all inputs—content and conditions—as tokens in a unified sequence, processed jointly by self-attention. Conditional tokens are concatenated with the noisy latent sequence, and temporal alignment is achieved via RoPE Interpolation. The DiT backbone is fine-tuned with a flow matching objective, supervising only non-conditional regions. This design requires no architectural changes or additional parameters.
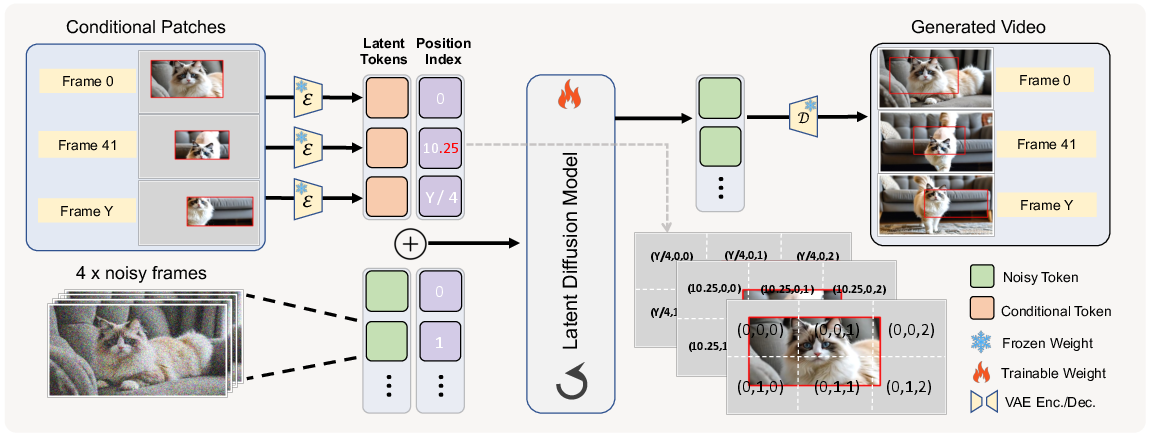
Figure 4: VideoCanvas pipeline: spatial zero-padding for patch placement, independent VAE encoding for temporal decoupling, and RoPE Interpolation for fine-grained alignment.
Empirical Analysis
Ablation: Pixel-Frame Alignment Strategies
A comprehensive ablation compares four alignment strategies: Latent-space Conditioning, Pixel-space Padding, w/o RoPE Interpolation, and the full method with RoPE Interpolation. Results show that:
- Pixel-space Padding achieves temporal precision but degrades quality due to VAE signal corruption (see Figure 5).
- Latent-space Conditioning collapses motion, yielding static outputs.
- w/o RoPE Interpolation misaligns PSNR peaks due to slot misassignment.
- RoPE Interpolation achieves exact alignment and highest fidelity.
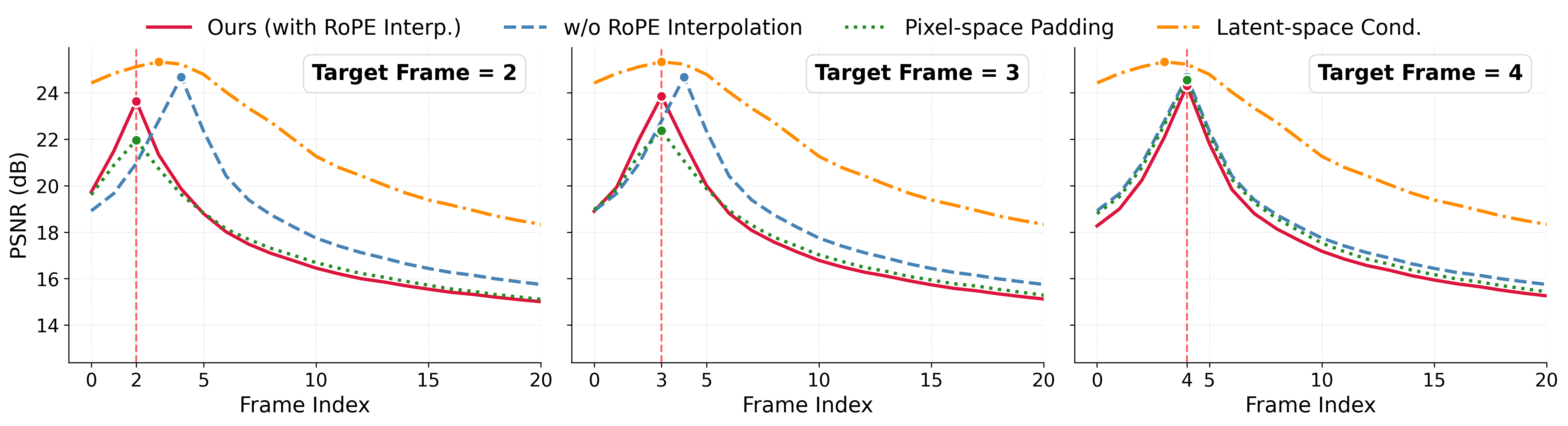
Figure 6: Per-frame PSNR for single-frame I2V: RoPE Interpolation peaks at the target frame, outperforming alternatives in fidelity and alignment.

Figure 5: Temporal zero-padding causes severe degradation in VAE reconstructions, validating the necessity of RoPE Interpolation.
Paradigm Comparison
On the VideoCanvasBench benchmark, ICC consistently outperforms Latent Replacement and Channel Concatenation across reference fidelity (PSNR, FVD), perceptual metrics (Aesthetic Quality, Imaging Quality, Temporal Coherence, Dynamic Degree), and user preference. Latent Replacement yields high PSNR but low Dynamic Degree, indicating motion collapse. Channel Concatenation improves dynamics but suffers from identity drift and requires significantly more parameters. ICC achieves the best balance of fidelity, dynamics, and human preference.

Figure 7: ICC paradigm yields superior results compared to Latent Replacement and Channel Concatenation across diverse tasks.
Applications and Capabilities
Flexible Temporal and Spatio-Temporal Control
VideoCanvas enables fine-grained control over arbitrary timestamps (AnyI2V) and arbitrary spatial regions (AnyP2V), supporting complex interpolation and extrapolation scenarios. The model synthesizes plausible motion and context from sparse patches, maintaining object identity even with minimal input.

Figure 8: Results on Any-timestamp Patches to Videos demonstrate robust spatio-temporal reasoning from sparse conditions.

Figure 9: Results on Any-timestamp Images to Videos showcase flexible temporal interpolation and extrapolation.
Creative Video Transition and Long-Duration Extension
The framework supports creative transitions between non-homologous clips, generating seamless semantic evolution (Figure 10). Long-duration synthesis is achieved by autoregressive completion, maintaining temporal consistency over extended horizons and enabling seamless looping (Figure 11).

Figure 10: VideoCanvas generates smooth transitions between distinct scenes, demonstrating creative synthesis capabilities.
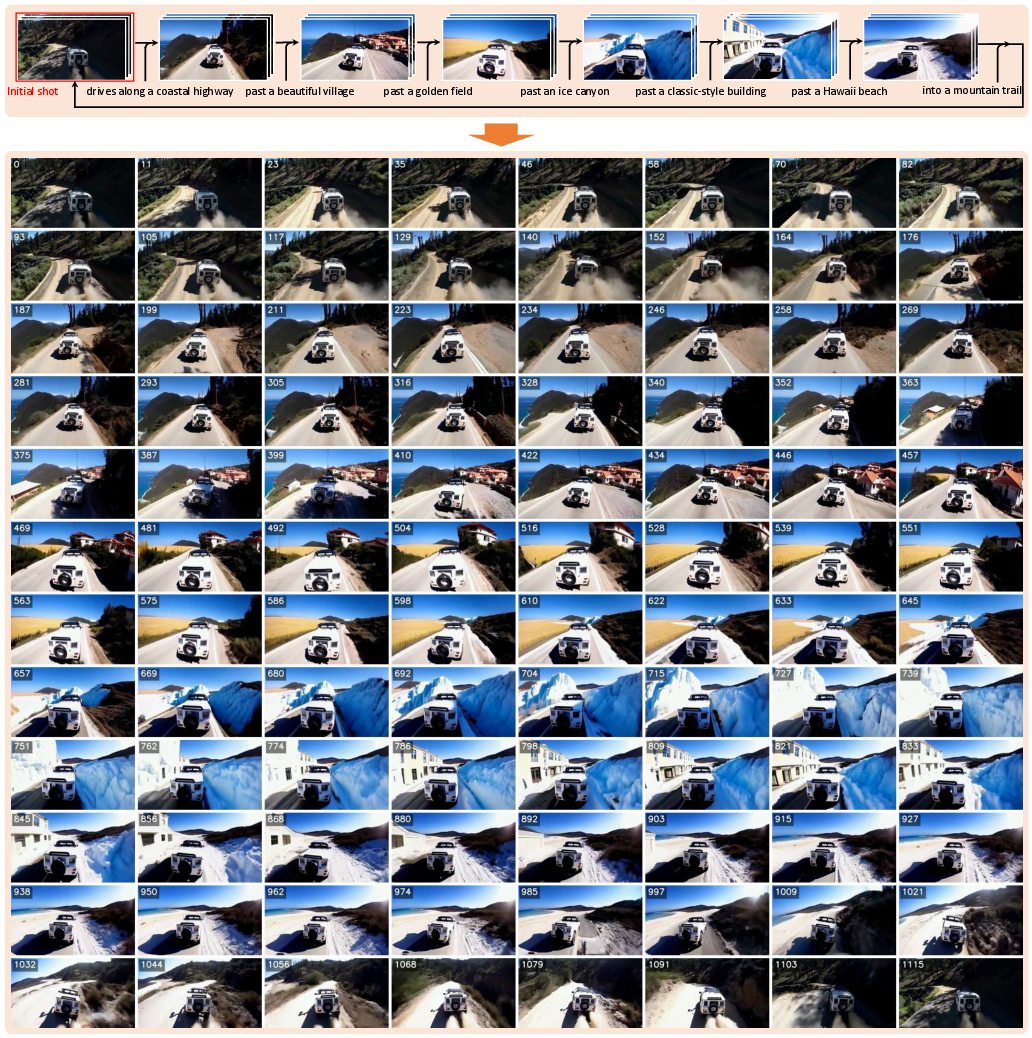
Figure 11: Video extension and seamless looping over 1,000 frames, maintaining quality and consistency.
Unified Video Painting and Camera Control
By providing masked videos as conditions, the model performs inpainting and outpainting (Figure 12). Progressive translation or scaling of conditional frames emulates camera effects such as zoom and pan (Figure 13), supporting creative post-production workflows.

Figure 12: Video inpainting and outpainting with precise control over generated regions.
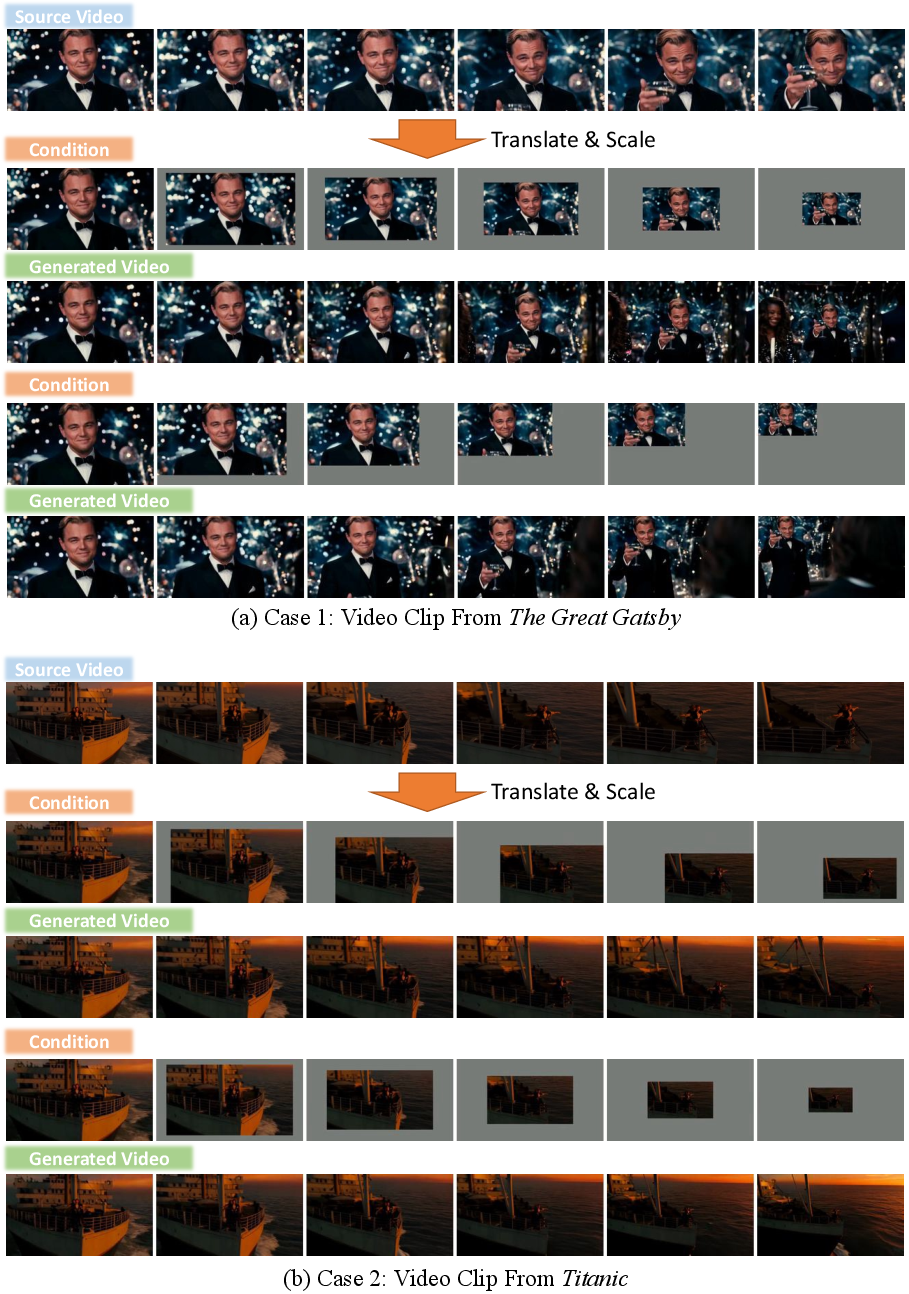
Figure 13: Emulated camera effects (zoom, pan) via spatio-temporal canvas manipulation.
Implementation Considerations
Computational Cost and Scalability
ICC introduces no additional parameters, whereas Channel Concatenation requires a large projection layer (~16.6M parameters). Training ICC is marginally slower due to longer sequences, and inference time increases with the number of conditional frames. However, the trade-off is justified by superior fidelity and alignment.
Limitations and Future Directions
The independent frame encoding strategy is efficient for sparse conditions but incurs overhead for dense inputs. Future work may explore hybrid mechanisms combining fine-grained alignment with token pruning for scalability. Data-centric approaches, such as pre-training VAEs on zero-padded temporal data, may further enhance compatibility and control.
Theoretical and Practical Implications
The decoupling of spatial and temporal conditioning in VideoCanvas establishes a robust foundation for unified, controllable video synthesis. The paradigm shift from rigid, task-specific models to a generalizable spatio-temporal canvas enables new applications in creative content generation, video editing, and reconstruction from partial data. The ICC framework, combined with RoPE Interpolation, demonstrates that fine-grained control is achievable without costly retraining or architectural modifications, suggesting a path forward for scalable, flexible video foundation models.
Conclusion
VideoCanvas formalizes and solves the task of arbitrary spatio-temporal video completion, unifying diverse controllable video generation scenarios under a single, efficient framework. The hybrid conditioning strategy—spatial zero-padding and Temporal RoPE Interpolation—enables fine-grained, pixel-frame-aware control on frozen VAEs, with ICC providing superior performance over existing paradigms. The approach is validated by strong quantitative, qualitative, and user study results, and unlocks versatile applications in video synthesis, editing, and creative production. Future research may extend these capabilities via data-centric pre-training and scalable token management, further advancing the field of controllable video generation.

