- The paper presents a unified generative process that integrates key inbetweening and colorization using sparse keyframe injection and region-wise control.
- It employs a Diffusion Transformer-based architecture enhanced by a novel Spatial Low-Rank Adapter (SLRA) to balance spatial adaptations with preserved temporal dynamics.
- Experimental evaluations, including user studies and benchmark comparisons, demonstrate superior aesthetic and motion quality over existing methods.
ToonComposer: A Unified Generative Model for Post-Keyframing in Cartoon Production
Introduction and Motivation
Traditional cartoon and anime production is characterized by a labor-intensive workflow, with artists responsible for keyframing, inbetweening, and colorization. While keyframing is a creative process, inbetweening and colorization are repetitive and time-consuming, often requiring hundreds of manually crafted frames for a few seconds of animation. Existing AI-assisted methods have made progress in automating these stages, but they typically treat inbetweening and colorization as separate processes, leading to error accumulation and suboptimal results, especially when handling large motions or sparse sketch inputs.
ToonComposer introduces a unified post-keyframing stage that merges inbetweening and colorization into a single generative process. This approach leverages sparse keyframe sketches and a colored reference frame to generate high-quality cartoon videos, significantly reducing manual workload and streamlining the production pipeline.
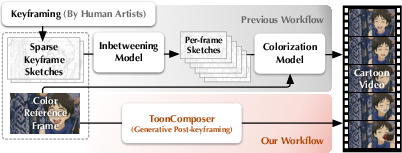
Figure 1: ToonComposer integrates inbetweening and colorization into a single automated process, contrasting with traditional and prior AI-assisted workflows.
Model Architecture and Key Innovations
ToonComposer is built upon a Diffusion Transformer (DiT)-based video foundation model, specifically Wan 2.1, and introduces several novel mechanisms to address the unique challenges of cartoon video generation:
- Sparse Sketch Injection: Enables precise temporal control by injecting sparse keyframe sketches at arbitrary positions in the latent token sequence. This mechanism supports both single and multiple sketches, allowing for flexible motion guidance and style consistency.
- Spatial Low-Rank Adapter (SLRA): Adapts the DiT model to the cartoon domain by introducing a low-rank adaptation module that modifies only the spatial behavior of the attention mechanism, preserving the temporal prior essential for smooth motion.
- Region-wise Control: Allows artists to specify regions in sketches where the model should generate content based on context or text prompts, further reducing the need for dense manual input.

Figure 2: ToonComposer’s architecture, highlighting sparse sketch injection and cartoon adaptation via SLRA.
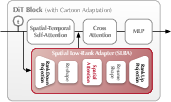
Figure 3: The SLRA module adapts spatial features for the cartoon domain while maintaining temporal coherence.
Training Data and Benchmarks
A large-scale dataset, PKData, was curated, comprising 37,000 high-quality cartoon video clips with diverse sketch styles generated by multiple open-source models and a custom FLUX-based IC-Sketcher. For evaluation, two benchmarks were established:
Experimental Results
Quantitative and Qualitative Evaluation
ToonComposer was compared against state-of-the-art methods (AniDoc, LVCD, ToonCrafter) on both synthetic and real benchmarks. It consistently outperformed baselines across all metrics, including LPIPS, DISTS, CLIP similarity, subject consistency, motion smoothness, background consistency, and aesthetic quality.
- Synthetic Benchmark: ToonComposer achieved a DISTS score of 0.0926, significantly lower than competitors, indicating superior perceptual quality.
- PKBench (Real Sketches): ToonComposer led in all reference-free metrics, demonstrating robustness to real-world sketch variability.

Figure 5: ToonComposer produces smoother motion and better style consistency compared to prior methods on the synthetic benchmark.

Figure 6: On PKBench, ToonComposer maintains visual consistency and high quality with human-drawn sketches, outperforming other models.
Human Evaluation
A user study with 47 participants confirmed the quantitative findings: ToonComposer was preferred for both aesthetic and motion quality in over 70% of cases, far surpassing other methods.
Ablation Studies
Ablation experiments on the SLRA module demonstrated its critical role. Variants that adapted temporal or spatial-temporal features, or used standard LoRA, underperformed compared to SLRA, which specifically targets spatial adaptation while preserving temporal priors.

Figure 7: SLRA yields higher visual quality and better coherence with input sketches than alternative adaptation strategies.
Region-wise and Multi-keyframe Control
Region-wise control enables plausible content generation in user-specified blank areas, enhancing flexibility and reducing manual effort.

Figure 8: Region-wise control allows context-driven generation in blank sketch regions, improving content plausibility.
The sparse sketch injection mechanism supports variable numbers of keyframe sketches, allowing artists to control motion granularity as needed.

Figure 9: Flexible controllability with varying keyframe sketches enables nuanced motion control in generated sequences.
Practical and Theoretical Implications
ToonComposer’s unified post-keyframing paradigm offers several practical advantages:
- Production Efficiency: By consolidating inbetweening and colorization, ToonComposer reduces manual labor and error accumulation, streamlining the cartoon production pipeline.
- Artist Empowerment: Sparse and region-wise controls provide artists with precise yet flexible tools, allowing them to focus on creative aspects while delegating repetitive tasks to the model.
- Robustness and Generalization: The model’s ability to handle diverse sketch styles and extend to 3D animation domains demonstrates strong generalization capabilities.
Theoretically, the introduction of SLRA for domain adaptation in DiT-based video models represents a significant advancement, enabling targeted spatial adaptation without compromising temporal dynamics—a key requirement for high-quality video synthesis in stylized domains.
Limitations and Future Directions
While ToonComposer achieves strong results, computational requirements remain substantial due to the DiT backbone and large-scale training. Future work may focus on model compression, efficient inference, and further improving controllability, such as integrating more nuanced semantic or physics-based constraints. Additionally, expanding the approach to other animation styles and interactive editing scenarios could broaden its applicability.
Conclusion
ToonComposer presents a unified, controllable, and efficient solution for AI-assisted cartoon production, integrating inbetweening and colorization into a single generative process. Its innovations in sparse sketch injection, spatial low-rank adaptation, and region-wise control set a new standard for flexibility and quality in cartoon video synthesis. The model’s strong empirical performance and practical utility suggest significant potential for adoption in professional animation pipelines and further research in generative video modeling.
