- The paper introduces Self-QA, which leverages unsupervised knowledge to generate domain-specific instruction data efficiently.
- It combines knowledge-guided instruction generation with machine reading comprehension and filtering to ensure high-quality outputs.
- Empirical results on BLOOM-7B demonstrate improved performance and domain coverage over traditional instruction-tuning methods.
Self-QA: Unsupervised Knowledge Guided LLM Alignment
This essay provides a comprehensive analysis of the "Self-QA" framework, focusing on its methodology, performance, and implications in the context of LLM alignment and instruction-tuning.
Introduction
The deployment of LLMs like GPT-4 has transformed conversational AI, yet constructing high-quality instruction-tuning datasets remains cumbersome due to the extensive human annotation required. The paper "Self-QA: Unsupervised Knowledge Guided LLM Alignment" addresses this challenge by introducing Self-QA, an unsupervised method that leverages abundant unsupervised knowledge for generating instruction-tuning data.
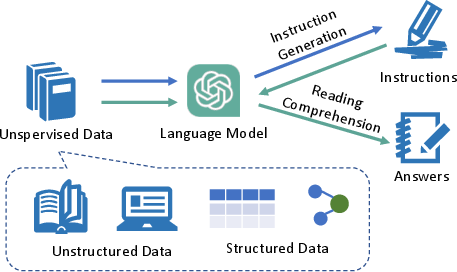
Figure 1: The pipeline of Self-QA.
Methodology
Self-QA integrates three primary stages: knowledge-guided instruction generation, machine reading comprehension, and filtering and pruning.
Knowledge-Guided Instruction Generation
In this phase, the model generates domain-specific instructions using unsupervised textual data as background information. This ensures instructions are relevant and encompass specific knowledge areas. For structured data sources, the paper proposes converting them to unstructured formats to align with input expectations (Figure 2).
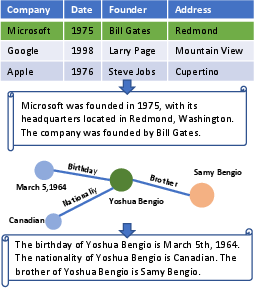
Figure 2: Examples of transformation of unsupervised structured data.
Machine Reading Comprehension
The generated instructions are paired with answers derived from the same unsupervised knowledge dataset. This process utilizes prompts to simulate machine reading comprehension by generating accurate and relevant responses without introducing external reference dependencies.
Filtering and Pruning
Given the potential for instruction generation errors, a post-processing phase is implemented to filter non-compliant instances. This ensures the adherence to specified guidelines, thus enhancing the quality of the generated data.
Empirical evaluations highlight Self-QA's efficacy in producing accurate and domain-specific instruction-tuning datasets, demonstrated through experiments on BLOOM-7B. Comparisons with existing methods (e.g., Self-Instruct) underscore the improved domain coverage and correctness facilitated by Self-QA, as evidenced by direct contrasts in model response accuracy.
Discussion
Integration of Stages
While merging instruction generation with machine reading comprehension into a single stage might reduce computational overhead, it potentially compromises focused task execution. This trade-off is crucial and requires consideration based on application-specific demands.
Knowledge Representation
Self-QA explores implicit parametric storage of knowledge in models as opposed to explicit symbolic representations, each with advantages and limitations. Parametric methods allow seamless model optimization but demand rigorous training to minimize embedded biases. Conversely, symbolic representations necessitate complex retrieval systems but offer explicit control over information utilization.
Conclusion
Self-QA presents a robust framework that advances the capability of LLMs to autonomously generate high-quality, diverse, and domain-specific instruction datasets. By circumventing traditional reliance on human annotations, Self-QA enhances the scalability of instruction tuning, paving the way for more efficient development of AI conversational systems. With demonstrated improvements in performance and practical applications, Self-QA represents a significant step towards optimizing model alignment with real-world knowledge requirements.
