- The paper introduces the SearchInstruct framework, which dynamically combines document retrieval and LLM-driven query expansion to generate domain-specific instruction datasets.
- It implements an iterative pipeline for model fine-tuning and editing, yielding improved performance in specialized domains like Iranian cuisine and domestic tourism.
- The framework demonstrates that retrieval-augmented data generation can empower smaller models to outperform larger ones on domain-adaptation tasks.
SearchInstruct: Retrieval-Augmented Instruction Dataset Creation for Domain Adaptation
Overview and Motivation
The SearchInstruct framework introduces a retrieval-based pipeline for constructing high-quality instruction datasets tailored for supervised fine-tuning (SFT) of LLMs in specialized domains. The method addresses persistent challenges in domain adaptation, including data scarcity, lack of diversity, and the inability of static or hallucinated datasets to reflect real-world user needs. By integrating dynamic document retrieval and LLM-driven query expansion, SearchInstruct enables the generation of instruction–response pairs grounded in up-to-date, domain-specific evidence, facilitating both initial model adaptation and efficient model editing.
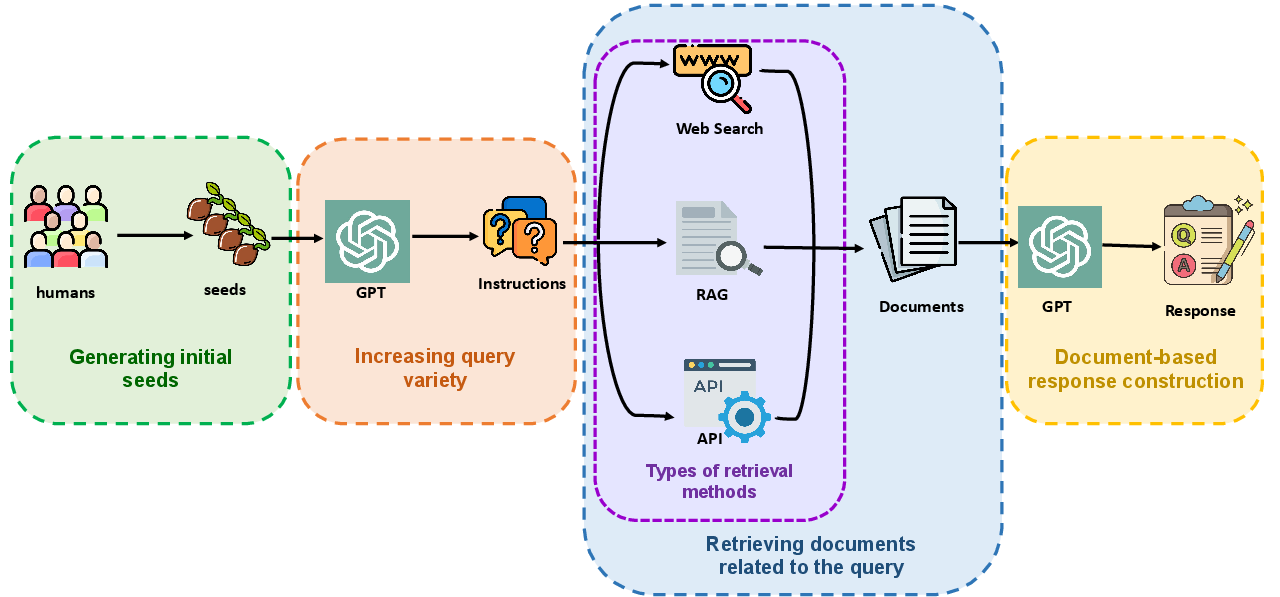
Figure 1: The four-stage SearchInstruct pipeline: seed generation, query expansion, document retrieval, and response construction.
Pipeline Architecture and Implementation
The SearchInstruct pipeline consists of four sequential stages:
- Seed Generation: Domain experts or annotators create a diverse set of seed queries, either manually or via human–LLM collaboration. This ensures coverage of realistic, context-rich user instructions, including those not typically found in document corpora.
- Query Expansion: An LLM is prompted to generate paraphrases and novel instructions from the seed set, increasing dataset diversity and simulating a broader distribution of user queries.
- Document Retrieval: For each expanded instruction, relevant documents are retrieved using RAG-style dense retrieval, web search, or domain-specific APIs. Search-oriented query rewriting via LLMs optimizes retrieval effectiveness.
- Response Construction: Retrieved documents are filtered (using LLM-based chunk selection or rule-based heuristics) and concatenated with the instruction. A powerful LLM then generates a context-grounded answer, forming the final instruction–response pair.
This pipeline is designed to be iterative: after initial fine-tuning, model weaknesses are identified through targeted evaluation, and new instruction–response data is generated to address these gaps, enabling focused and incremental improvements.
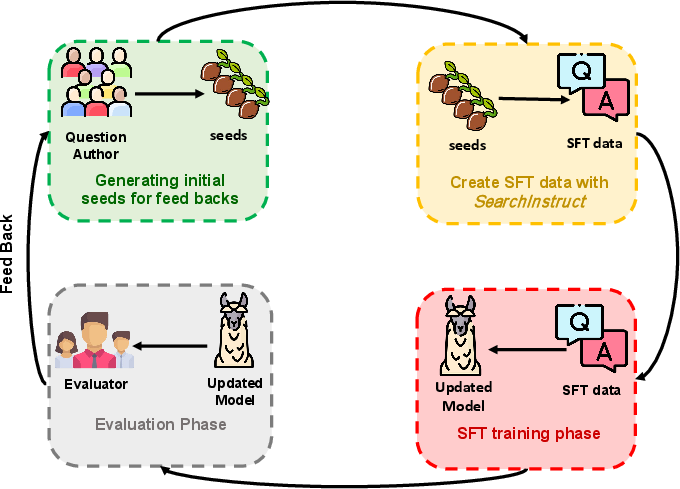
Figure 2: Iterative refinement loop enabled by the SearchInstruct framework. After initial fine-tuning, specific model weaknesses are identified through targeted evaluation. New instruction–response data is then generated to directly address these shortcomings, creating a feedback loop that leads to focused and incremental improvements in model performance.
Domain-Specific SFT: Iranian Cuisine and Tourism
SearchInstruct was applied to the domains of Iranian cuisine and domestic tourism, where existing LLMs lack coverage and fail to answer colloquial, context-rich queries. The pipeline generated thousands of instruction–response pairs across multiple refinement cycles, each targeting previously underrepresented question types (e.g., scenario-based recommendations, multi-constraint planning).
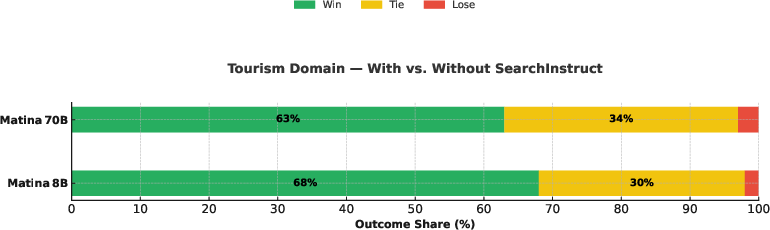
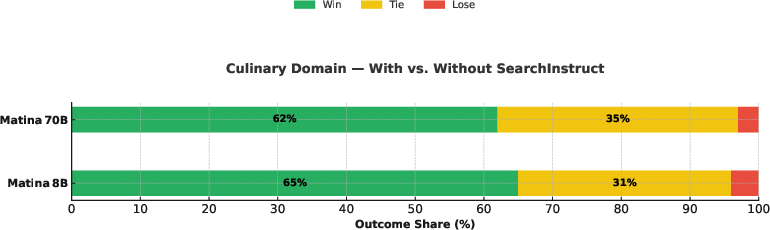
Figure 3: Tourism domain.
Blind human evaluation on a benchmark of 100 diverse questions demonstrated that models fine-tuned with SearchInstruct data outperformed those trained on standard synthetic datasets, particularly in areas previously identified as weak. The iterative feedback loop allowed for rapid, targeted improvement in model performance.
Model Editing and Knowledge Updates
Beyond initial SFT, SearchInstruct facilitates efficient model editing by generating update-specific instruction–response pairs. For time-sensitive domains (e.g., political changes, recent events), the framework retrieves up-to-date documents and minimally revises model outputs using a secondary editing model. This enables localized factual corrections without degrading general knowledge or requiring full retraining.

Figure 4: Pipeline for constructing update-specific instruction data used in model editing. Starting from user-provided queries, relevant documents are retrieved and used to construct grounded instruction–answer pairs.
Evaluation on the Gemma 27B model using ORPO fine-tuning showed that edited models correctly answered updated factual queries while maintaining performance on general benchmarks (MMLU). However, analysis revealed that such editing is shallow: models memorize specific updates but do not deeply integrate new knowledge, limiting reasoning about related facts not present in the update dataset.
Figure 5: Representative examples of minimally revised responses with factual updates. Each row includes a user instruction, a rejected response containing outdated or incorrect information, and a chosen response with concise, targeted edits. The examples cover domains such as politics, international affairs, and sports, demonstrating factual correction with minimal changes to phrasing and tone.
SearchInstruct demonstrates that retrieval-augmented data generation can enable smaller or open-source models to outperform larger models on domain-specific instructions, provided that relevant contextual information is incorporated.
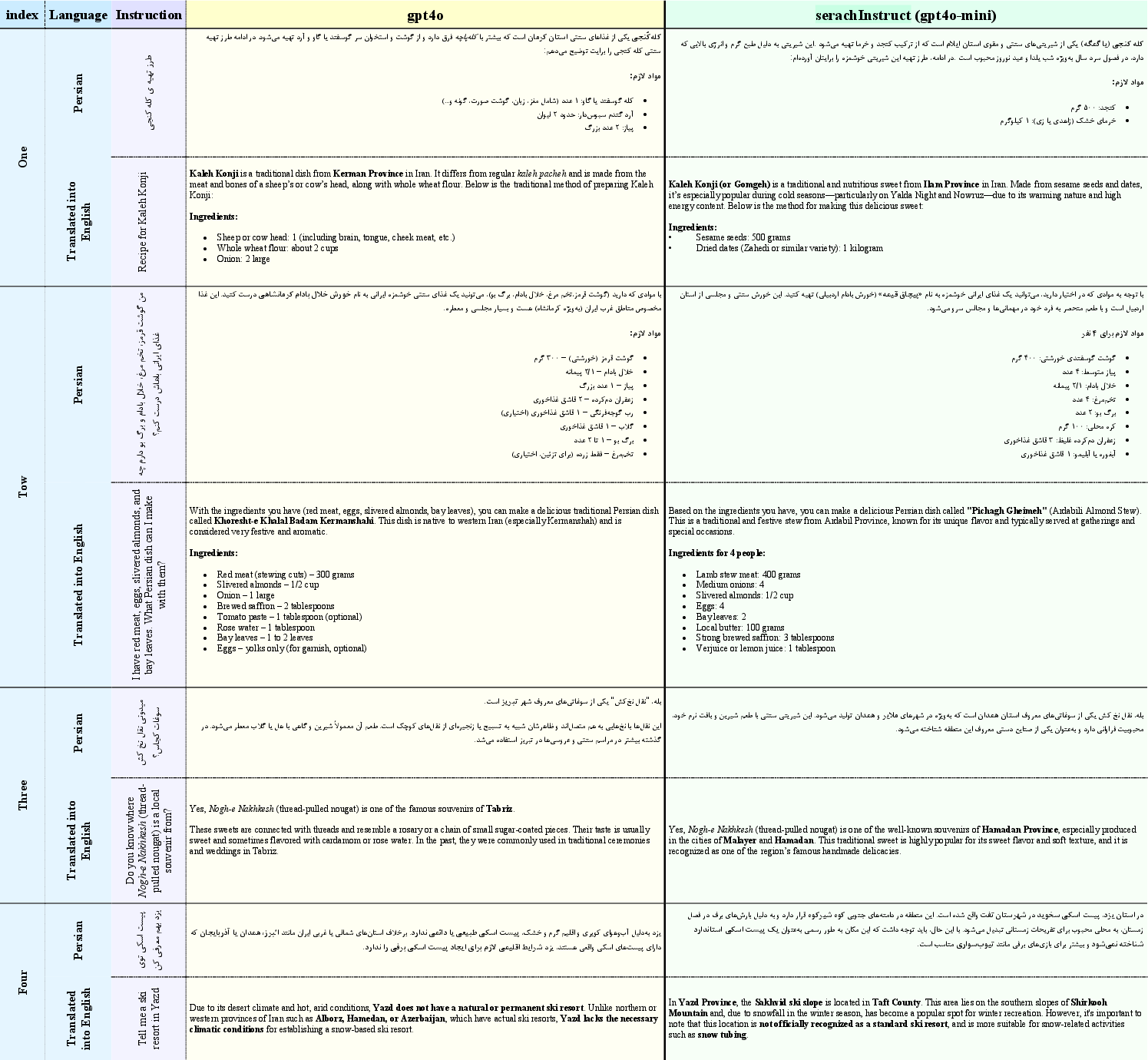
Figure 6: Examples of partial outputs from GPT-4o and SearchInstruct (GPT4o mini): This demonstrates that in certain instructions, the SearchInstruct method is capable of producing better responses than larger models, as it benefits from access to highly relevant contextual information, even when using a smaller model.
The framework’s modular prompt design for query expansion, search-oriented rewriting, and evidence-grounded response construction supports flexible adaptation to new domains and evolving requirements.

Figure 7: System prompt design for query expansion.

Figure 8: System prompt design for search-oriented query rewriting.

Figure 9: System prompt design for evidence-grounded response construction.

Figure 10: System prompt design for answer refinement and updates.
Limitations
SearchInstruct’s effectiveness is contingent on the quality and availability of retrieved documents. In domains with sparse or noisy resources, answer quality may degrade. The model editing process is inherently shallow, enabling surface-level factual updates but not deep conceptual integration. Scalability remains a challenge for large or rapidly evolving domains due to resource requirements for retrieval and validation. The pipeline also relies on strong LLMs for several stages, and web-based retrieval may propagate source biases.
Implications and Future Directions
SearchInstruct provides a scalable, modular solution for domain adaptation and model editing in LLMs, bridging the gap between static SFT and real-world evolving needs. The framework’s iterative refinement loop and retrieval-augmented data generation offer a practical path for continual model improvement and knowledge refresh.
Future work should explore deeper integration of structured knowledge sources, agent-based multi-step RL environments, automated feedback optimization, and quality assessment tools. Addressing the limitations of shallow model editing and document dependency will be critical for broader adoption in high-stakes domains.
Conclusion
SearchInstruct advances the state of retrieval-augmented instruction dataset creation for LLM domain adaptation. By combining LLM-driven query expansion with targeted document retrieval and evidence-grounded response synthesis, the framework enables the construction of diverse, realistic, and up-to-date SFT datasets. Empirical results validate its utility for both initial domain adaptation and efficient model editing, with strong performance gains in specialized domains and minimal degradation of general knowledge. The modular, iterative design positions SearchInstruct as a promising foundation for future research in adaptive, domain-aware language modeling.

