Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models
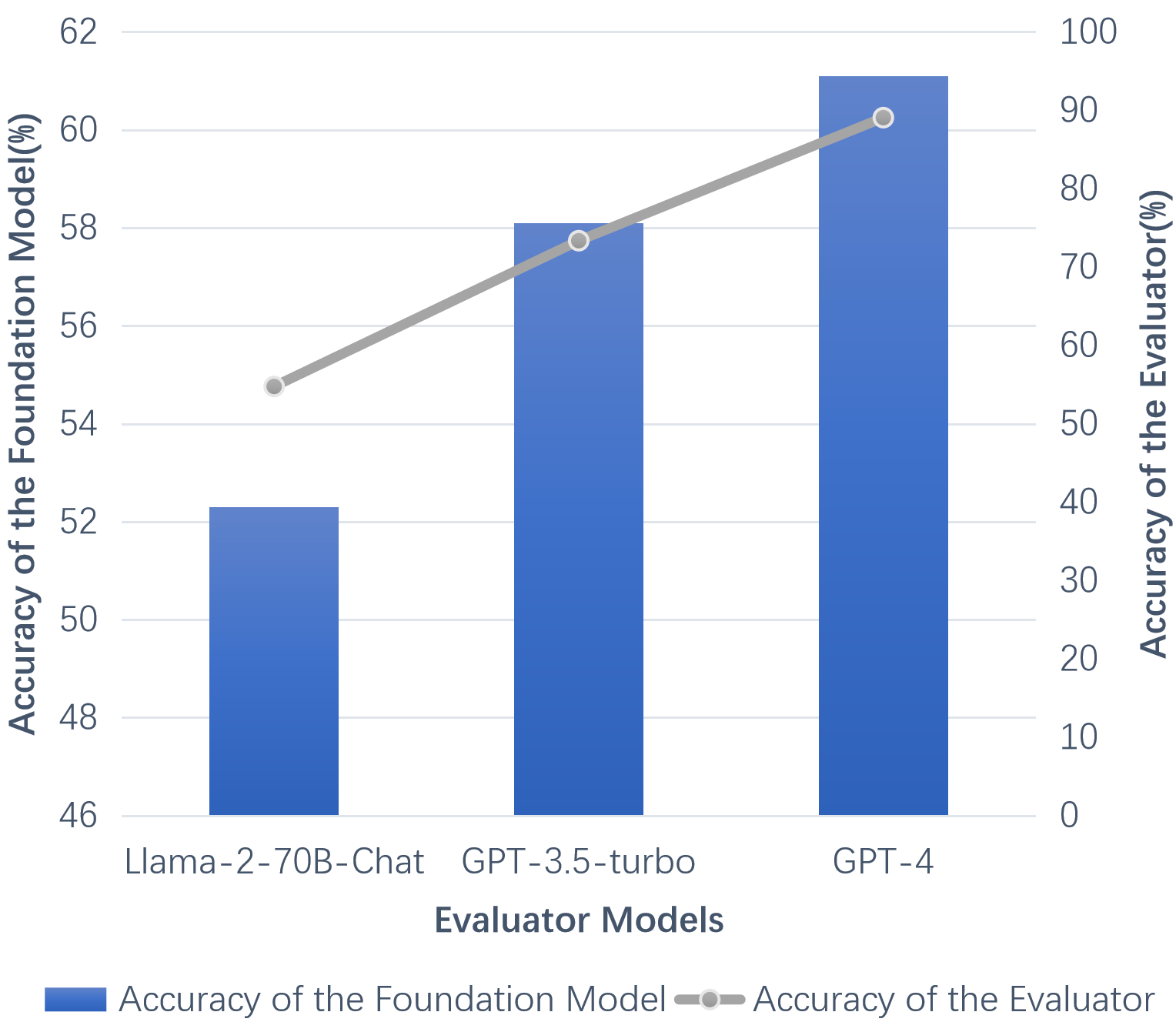
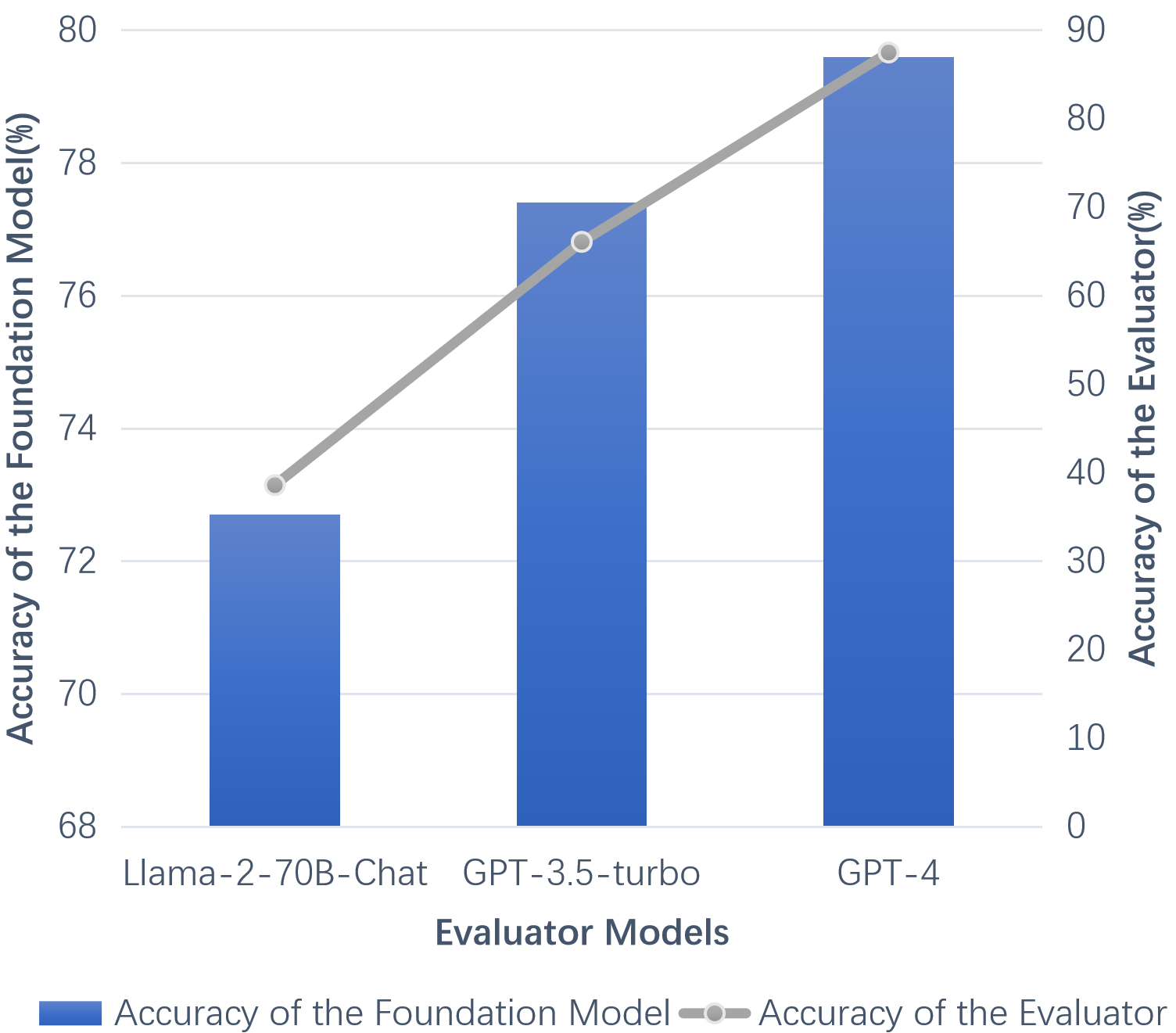
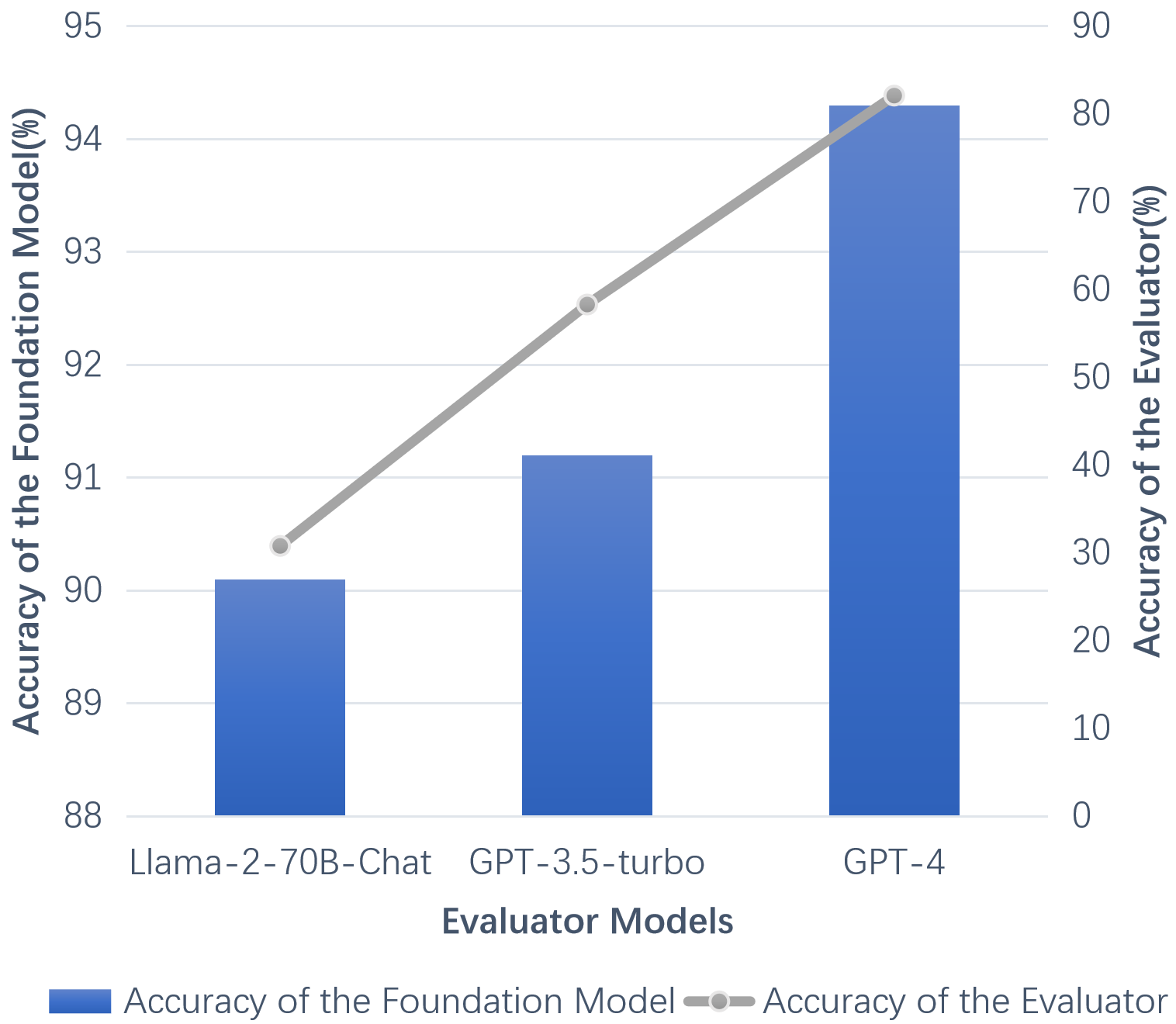
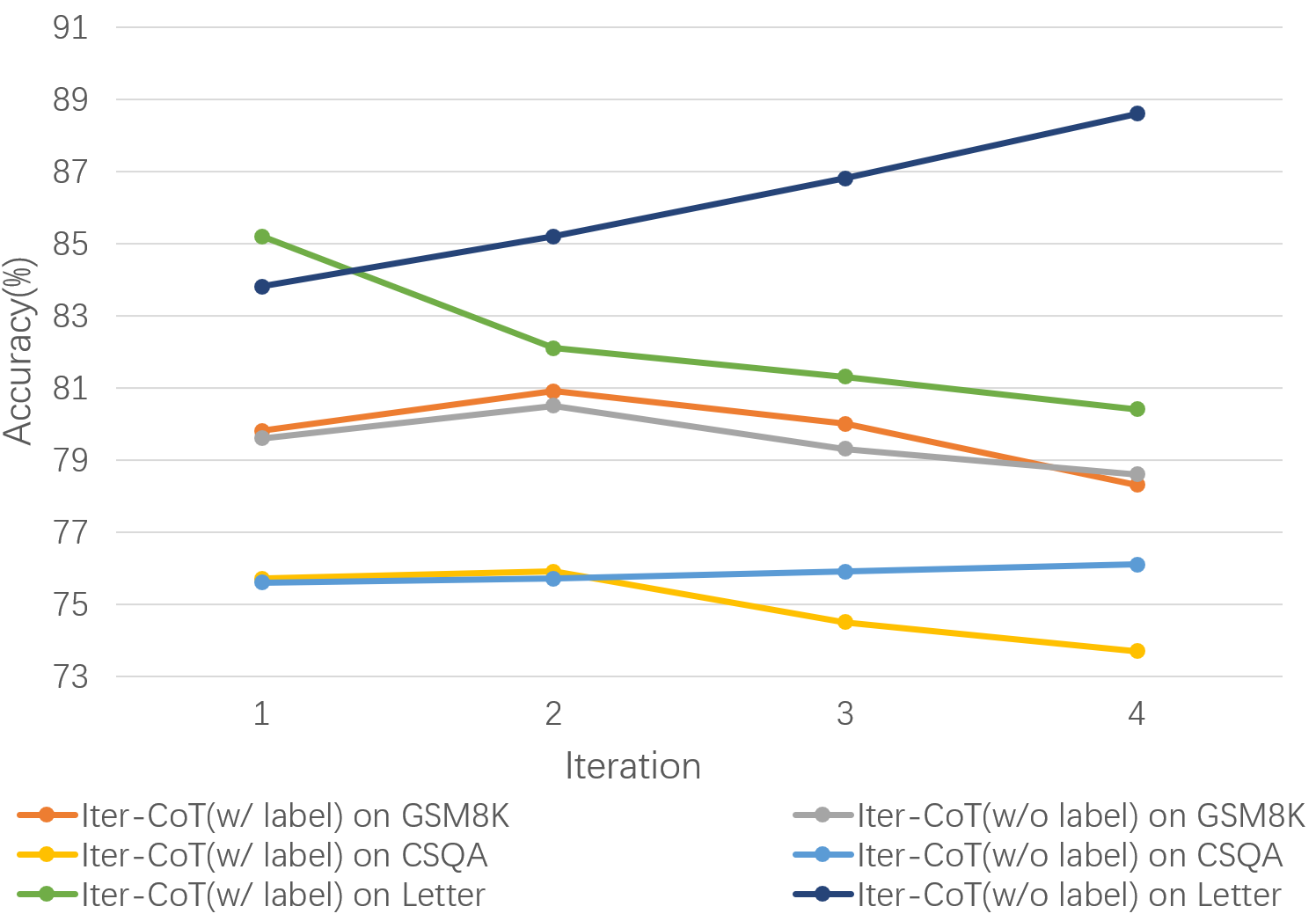
Abstract: LLMs can achieve highly effective performance on various reasoning tasks by incorporating step-by-step chain-of-thought (CoT) prompting as demonstrations. However, the reasoning chains of demonstrations generated by LLMs are prone to errors, which can subsequently lead to incorrect reasoning during inference. Furthermore, inappropriate exemplars (overly simplistic or complex), can affect overall performance among varying levels of difficulty. We introduce Iter-CoT (Iterative bootstrapping in Chain-of-Thoughts Prompting), an iterative bootstrapping approach for selecting exemplars and generating reasoning chains. By utilizing iterative bootstrapping, our approach enables LLMs to autonomously rectify errors, resulting in more precise and comprehensive reasoning chains. Simultaneously, our approach selects challenging yet answerable questions accompanied by reasoning chains as exemplars with a moderate level of difficulty, which enhances the LLMs' generalizability across varying levels of difficulty. Experimental results indicate that Iter-CoT exhibits superiority, achieving competitive performance across three distinct reasoning tasks on ten datasets.
- Language models are few-shot learners. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin (eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020. URL https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
- Palm: Scaling language modeling with pathways. arXiv Preprint, 2022. doi: 10.48550/arXiv.2204.02311. URL https://doi.org/10.48550/arXiv.2204.02311.
- Training verifiers to solve math word problems. arXiv Preprint, 2021. URL https://arxiv.org/abs/2110.14168.
- Active prompting with chain-of-thought for large language models. arXiv Preprint, 2023. doi: 10.48550/arXiv.2302.12246. URL https://doi.org/10.48550/arXiv.2302.12246.
- Complexity-based prompting for multi-step reasoning. arXiv Preprint, 2022. doi: 10.48550/arXiv.2210.00720. URL https://doi.org/10.48550/arXiv.2210.00720.
- Did aristotle use a laptop? A question answering benchmark with implicit reasoning strategies. Trans. Assoc. Comput. Linguistics, 9:346–361, 2021. doi: 10.1162/tacl_a_00370. URL https://doi.org/10.1162/tacl_a_00370.
- Learning to solve arithmetic word problems with verb categorization. In Alessandro Moschitti, Bo Pang, and Walter Daelemans (eds.), Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, October 25-29, 2014, Doha, Qatar, A meeting of SIGDAT, a Special Interest Group of the ACL, pp. 523–533. ACL, 2014. doi: 10.3115/v1/d14-1058. URL https://doi.org/10.3115/v1/d14-1058.
- Large language models are zero-shot reasoners. arXiv Preprint, 2022. doi: 10.48550/arXiv.2205.11916. URL https://doi.org/10.48550/arXiv.2205.11916.
- Parsing algebraic word problems into equations. Trans. Assoc. Comput. Linguistics, 3:585–597, 2015. doi: 10.1162/tacl_a_00160. URL https://doi.org/10.1162/tacl_a_00160.
- On the advance of making language models better reasoners. arXiv Preprint, 2022. doi: 10.48550/arXiv.2206.02336. URL https://doi.org/10.48550/arXiv.2206.02336.
- Program induction by rationale generation: Learning to solve and explain algebraic word problems. In Regina Barzilay and Min-Yen Kan (eds.), Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, Volume 1: Long Papers, pp. 158–167, 2017. doi: 10.18653/v1/P17-1015. URL https://doi.org/10.18653/v1/P17-1015.
- A diverse corpus for evaluating and developing english math word problem solvers. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel R. Tetreault (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pp. 975–984, 2020. doi: 10.18653/v1/2020.acl-main.92. URL https://doi.org/10.18653/v1/2020.acl-main.92.
- OpenAI. GPT-4 technical report. CoRR, abs/2303.08774, 2023. doi: 10.48550/arXiv.2303.08774. URL https://doi.org/10.48550/arXiv.2303.08774.
- Training language models to follow instructions with human feedback. arXiv Preprint, 2022. doi: 10.48550/arXiv.2203.02155. URL https://doi.org/10.48550/arXiv.2203.02155.
- Are NLP models really able to solve simple math word problems? In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tür, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou (eds.), Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, June 6-11, 2021, pp. 2080–2094, 2021. doi: 10.18653/v1/2021.naacl-main.168. URL https://doi.org/10.18653/v1/2021.naacl-main.168.
- Measuring and narrowing the compositionality gap in language models. arXiv Preprint, 2022. doi: 10.48550/arXiv.2210.03350. URL https://doi.org/10.48550/arXiv.2210.03350.
- Scaling language models: Methods, analysis & insights from training gopher. arXiv Preprint, 2021. URL https://arxiv.org/abs/2112.11446.
- BLOOM: A 176b-parameter open-access multilingual language model. arXiv Preprint, 2022. doi: 10.48550/arXiv.2211.05100. URL https://doi.org/10.48550/arXiv.2211.05100.
- Synthetic prompting: Generating chain-of-thought demonstrations for large language models. arXiv Preprint, abs/2302.00618, 2023. doi: 10.48550/arXiv.2302.00618. URL https://doi.org/10.48550/arXiv.2302.00618.
- Automatic prompt augmentation and selection with chain-of-thought from labeled data. arXiv Preprint, abs/2302.12822, 2023. doi: 10.48550/arXiv.2302.12822. URL https://doi.org/10.48550/arXiv.2302.12822.
- Using deepspeed and megatron to train megatron-turing NLG 530b, A large-scale generative language model. arXiv Preprint, 2022. URL https://arxiv.org/abs/2201.11990.
- Commonsenseqa: A question answering challenge targeting commonsense knowledge. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pp. 4149–4158, 2019. doi: 10.18653/v1/n19-1421. URL https://doi.org/10.18653/v1/n19-1421.
- Lamda: Language models for dialog applications. arXiv Preprint, 2022. URL https://arxiv.org/abs/2201.08239.
- Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288, 2023. doi: 10.48550/arXiv.2307.09288. URL https://doi.org/10.48550/arXiv.2307.09288.
- Self-consistency improves chain of thought reasoning in language models. arXiv Preprint, 2022. doi: 10.48550/arXiv.2203.11171. URL https://doi.org/10.48550/arXiv.2203.11171.
- Chain of thought prompting elicits reasoning in large language models. arXiv Preprint, 2022. URL https://arxiv.org/abs/2201.11903.
- Star: Bootstrapping reasoning with reasoning. arXiv Preprint, 2022. doi: 10.48550/arXiv.2203.14465. URL https://doi.org/10.48550/arXiv.2203.14465.
- Automatic chain of thought prompting in large language models. arXiv Preprint, 2022. doi: 10.48550/arXiv.2210.03493. URL https://doi.org/10.48550/arXiv.2210.03493.
- Calibrate before use: Improving few-shot performance of language models. In Marina Meila and Tong Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 of Proceedings of Machine Learning Research, pp. 12697–12706. PMLR, 2021. URL http://proceedings.mlr.press/v139/zhao21c.html.
- Least-to-most prompting enables complex reasoning in large language models. arXiv Preprint, 2022. doi: 10.48550/arXiv.2205.10625. URL https://doi.org/10.48550/arXiv.2205.10625.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.