- The paper introduces a novel scheduling method using GFlowNets to generate diverse candidate schedules that withstand proxy estimation errors.
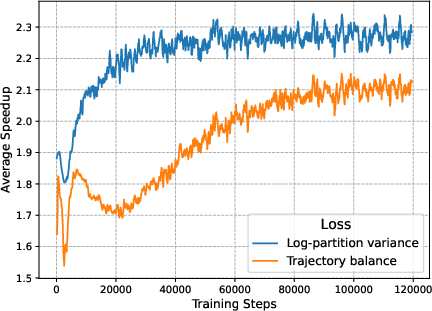
- The paper employs a log-partition variance loss to ensure flow consistency and expedite speedup improvements across varied hardware conditions.
- The paper demonstrates strong generalization and robustness through empirical validation on complex computation graphs and real-world hardware scenarios.
Robust Scheduling with GFlowNets
The paper "Robust Scheduling with GFlowNets" explores a novel approach to scheduling operations in computation graphs using Generative Flow Networks (GFlowNets). The authors aim to improve the robustness against modeling inaccuracies in scheduling proxies and demonstrate enhanced performance through diversity in generated schedules. This essay provides a comprehensive review of the methods, empirical results, and implications of the research.
Introduction to Scheduling in Computation Graphs
Scheduling is a critical problem in compiler optimization, particularly when mapping operations of a computation graph to available computing resources like processors or nodes. Traditional methods often rely on proxy metrics for efficiency but fail to account for the discrepancies between these proxies and actual hardware performance. The proposed approach leverages GFlowNets to sample diverse candidate schedules conditioned on the computation graph's structure, thereby improving generalization to unseen problems and achieving better results on the target hardware.
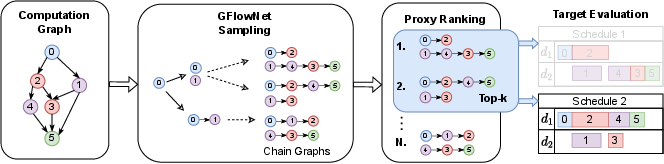
Figure 1: Full pipeline of our generative scheduling approach. Conditioned on the computation graph we generate multiple candidate schedules using GFlowNet, filter for the best k with the proxy and pick the best performing one out of the k that we check on the target. Here we illustrate the pipeline for k=2 and two devices, d1,d2.
Generative Flow Networks for Scheduling
The core idea in using GFlowNets is to model scheduling as a generative problem where each schedule corresponds to a sequence of actions that construct a valid execution order. GFlowNets sample schedules in proportion to a reward function based on proxy-estimated makespan, balancing diversity and quality:
The robust scheduling framework evaluates multiple generated schedules on the actual target hardware, compensating for any proxy inaccuracies:
Empirical Validation and Generalization
The proposed method was validated in several scenarios, demonstrating:
- Robustness: GFlowNets showed superior performance in varied target environments, such as those with bandwidth or latency constraints that deviate from proxy assumptions.
- Generalization: Experimental results indicated effective generalization to unseen computation graph structures, a notable achievement highlighted through experiments on real-world datasets of AI models.
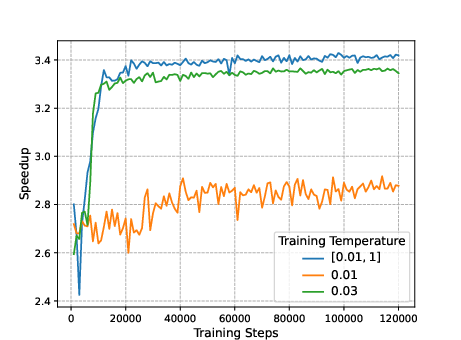
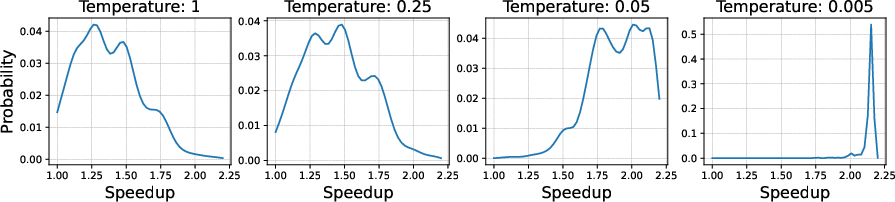
Figure 4: The impact of different temperature regimes on top-1 generalization performance. Training on single temperatures prevents learning when set too low (orange). On the other hand, training on a range of different temperatures (blue) results in better performance when performing inference with the minimum training temperature.
Conclusion
The integration of GFlowNets in scheduling offers a significant step forward in addressing the complexity and unpredictability inherent in real-world computational tasks. The research underscores the importance of diversity and conditional generation in achieving robust performance across various hardware configurations. As computational graphs grow in complexity, the scalability and adaptability of such generative methods will be crucial. Future work may focus on scaling the approach to larger graphs and enhancing the training process with hybrid strategies combining heuristic insights with learned models.