- The paper introduces GFlowNet, a novel generative model that uses flow networks to sample objects with probabilities proportional to their rewards.
- It leverages temporal difference learning and flow constraints to generate diverse high-reward candidates in tasks like molecule synthesis.
- Empirical results demonstrate improved mode recovery and sampling efficiency over traditional RL and MCMC methods in complex reward landscapes.
Flow Network Based Generative Models for Diverse Candidate Generation
The paper introduces GFlowNet, a novel generative method designed to sample diverse sets of high-reward solutions from an unnormalized probability distribution. This approach addresses the limitations of traditional reinforcement learning (RL) methods that tend to converge to a single, return-maximizing sequence, which is suboptimal in scenarios requiring exploration and diversity, such as black-box function optimization and molecule design. GFlowNet leverages concepts from temporal difference learning and flow networks to convert an energy function into a generative distribution, enabling the generation of diverse candidates with probabilities proportional to their rewards.
GFlowNet Framework
The GFlowNet framework addresses the challenge of generating objects (e.g., molecular graphs) through sequential actions, where the probability of generating an object is proportional to its reward. Unlike standard RL, which focuses on maximizing expected return, GFlowNet aims to sample a distribution of trajectories with probabilities proportional to a given positive reward function. This is particularly useful in scenarios where exploration is crucial, such as drug discovery, where diverse batches of candidates are needed for expensive oracle evaluations.
Limitations of Existing Methods
Existing methods, such as those based on tree-structured MDPs, fail when there are multiple action sequences leading to the same state. This non-injective correspondence between action sequences and states can introduce bias in generative probabilities, making larger molecules exponentially more likely to be sampled due to the greater number of paths leading to them.
GFlowNet addresses these limitations by framing the generative process as a flow network. In this network, states are nodes, and actions are edges. The flow is defined such that the incoming flow to a state equals the outgoing flow. By training a generative policy to match these flow conditions, GFlowNet ensures that the probability of sampling a terminal state is proportional to its reward. (Figure 1)
(Figure 1)
Figure 1: A flow network MDP, illustrating episodes starting at source s0 with flow Z, terminal states as sinks with out-flow R(s), and the flow equations that must be satisfied for all states.
The policy π(a∣s) is defined as the ratio of the flow through edge (s,a) to the total flow through state s, ensuring that the probability of visiting a state is proportional to its flow. The total flow into the network is the sum of the rewards in the terminal states, effectively converting the reward function into a generative distribution.
Objective Functions and Training
The paper introduces a flow-matching objective function to train the GFlowNet. To avoid numerical issues due to the wide range of flow magnitudes, the objective is defined on a log scale:
$\mathcal{L}_{\theta,\epsilon}(\tau) = \sum_{\mathclap{s'\in\tau\neq s_0}\,\left(\log\! \left[\epsilon+\smashoperator[r]{\sum_{\mathclap{s,a:T(s,a)=s'} \exp F^{\log}_\theta(s,a)\right] - \log\! \left[ \epsilon + R(s') + \sum_{\mathclap{a'\in {\cal A}(s')} \exp F^{\log}_\theta(s',a')\right]\right)^2$
This objective encourages the model to match the logarithms of incoming and outgoing flows, providing equal gradient weighing to large and small magnitude predictions. The training process is off-policy, allowing trajectories to be sampled from any exploratory policy with sufficient support on the state space.
Theoretical Properties
The paper provides theoretical proofs for the following key properties of GFlowNet:
- Flow Matching and Reward Proportionality: Any global minimum of the proposed objectives yields a policy that samples from the desired distribution, where the probability of sampling a terminal state is proportional to its reward.
- Off-Policy Convergence: GFlowNet converges to the correct flows and generative model even when training trajectories come from a different policy, as long as it has sufficient support on the state space.
Empirical Evaluation
The authors validate GFlowNet on both synthetic and real-world tasks, demonstrating its ability to generate diverse and high-reward candidates.
Hypergrid Domain
On a hypergrid domain with multiple modes in the reward function, GFlowNet outperforms MCMC methods in terms of sampling efficiency and mode recovery. GFlowNet is robust to variations in task difficulty, while MCMC struggles to fit the distribution as the reward landscape becomes more complex. (Figure 2)
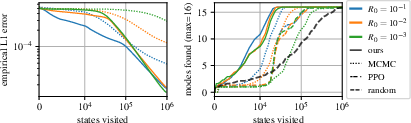
Figure 2: Performance comparison of GFlowNet, MCMC, and PPO on a hypergrid domain with varying task difficulty (R0), showing GFlowNet's robustness and efficiency.
Molecule Synthesis
GFlowNet is applied to a molecule synthesis task, where the goal is to generate diverse sets of small molecules with high binding affinity to a target protein. GFlowNet demonstrates superior performance compared to PPO and MCMC methods, finding more unique and high-reward molecules faster. (Figure 3)
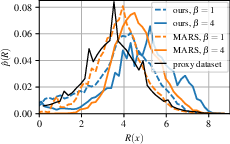
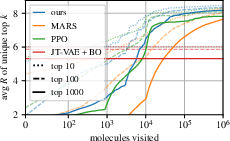
Figure 3: Empirical density of rewards and average reward of top-k unique molecules as a function of learning, demonstrating GFlowNet's consistency and ability to find high-reward molecules faster.
Furthermore, GFlowNet discovers a greater number of modes (diverse Bemis-Murcko scaffolds) compared to baseline methods. (Figure 4)
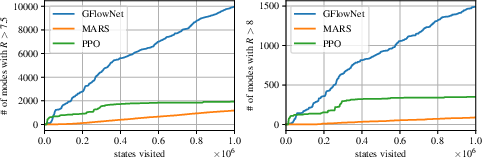
Figure 4: Number of diverse Bemis-Murcko scaffolds found above reward threshold T as a function of the number of molecules seen, highlighting GFlowNet's ability to discover more modes.
Active Learning Experiments
In active learning settings, GFlowNet demonstrates its ability to generate diverse candidates, leading to improved performance on both hyper-grid and molecule discovery tasks. GFlowNet consistently outperforms baselines in terms of return over the initial set and generates molecules with significantly higher energies. (Figure 5)
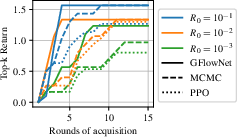
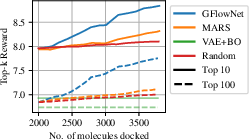
Figure 5: Top-k return in active learning for the 4-D Hyper-grid task and top-k docking reward in the molecule task, showing GFlowNet's superior performance in active learning settings.
Discussion and Conclusion
The paper presents GFlowNet as a novel approach for training generative models that sample states with probabilities proportional to their rewards. This method offers an alternative to iterative MCMC methods and addresses the limitations of standard RL in scenarios requiring diverse candidate generation. Empirical results demonstrate the effectiveness of GFlowNet in synthetic and real-world tasks, highlighting its ability to find high-reward and diverse solutions.
Limitations and Future Work
The authors acknowledge that GFlowNet, like other TD-based methods, may face optimization challenges due to bootstrapping. Future work should explore combining GFlowNet with local optimization techniques to refine generated samples and approach local maxima of reward while maintaining batch diversity.