- The paper presents DAS, a method for continual domain-adaptive pre-training that preserves general language knowledge while enabling knowledge transfer with soft-masking and contrastive loss.
- The method computes unit importance via gradient-based proxy scores and applies soft-masking to mitigate catastrophic forgetting in transformer architectures.
- Experimental results demonstrate that DAS outperforms existing approaches by achieving negative forgetting rates and superior performance across multiple domain tasks.
Continual Pre-training of LLMs
This paper introduces a novel approach, DAS (Continual DA-pre-training of LMs with Soft-masking), for continual domain-adaptive pre-training (DAP-training) of LMs. The method addresses catastrophic forgetting (CF) and encourages knowledge transfer (KT) across domains by employing a soft-masking mechanism and a contrastive learning approach.
DAS Methodology
The DAS technique comprises two primary components: preserving general language knowledge and learned domain knowledge via soft-masking, and promoting complementary representations of current and previous domains for knowledge integration.
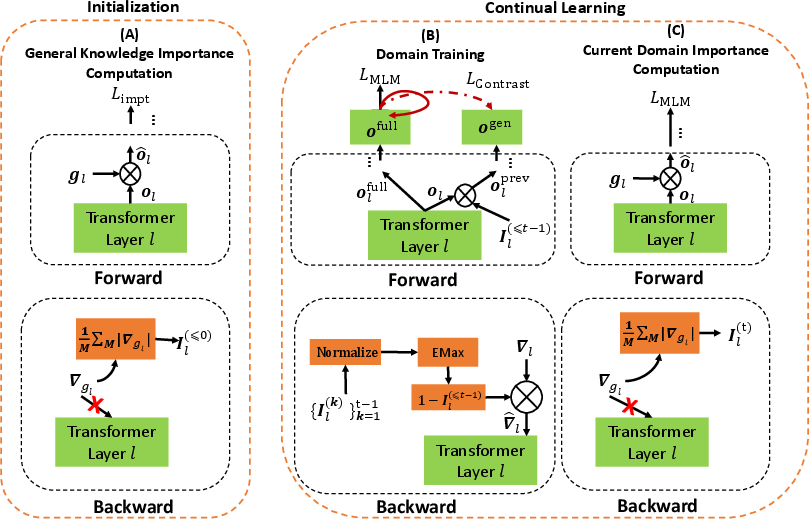
Figure 1: Illustration of DAS, highlighting the initialization, domain training, and importance computation steps.
The overall learning process is structured into initialization and continual learning phases. Initialization computes the importance of units for general language knowledge. The continual learning phase consists of domain training and importance computation, using accumulated importance scores and current domain data.
Initialization: Computing Importance of Units
This phase computes the importance of units (attention heads and neurons) within the Transformer for general knowledge present in the original LM. The importance of units in a layer is computed using a virtual parameter, gl, and a gradient-based proxy score:
$\bm{I}_{l} = \frac{1}{N}\sum_{n=1}^N|\frac{\partial\mathcal{L}_{\text{impt}(\bm{x}_n,{y}_n))}{\partial \bm{g}_{l}|$
To address the lack of pre-training data, a proxy KL-divergence loss ($\mathcal{L}_{\text{proxy}$), based on model robustness, is proposed:
$\mathcal{L}_{\text{impt} = \text{KL}(f^1_{\text{LM}(\bm{x}^{\text{sub}_n),f^2_{\text{LM}(\bm{x}^{\text{sub}_n)),$
Training: Soft-masking and Contrastive Loss
During DAP-training, DAS preserves learned knowledge using accumulated importance Il(≤t−1), achieved by soft-masking the learning based on accumulated importance:
Il(≤t−1)=EMax({Il(t−1),Il(≤t−2)}).
Soft-masking units involves constraining the gradient flow using the accumulated importance value:
∇^l=(1−Il(≤t−1))⊗∇l.
DAS integrates previously learned knowledge with current domain knowledge by contrasting learned and full knowledge. The contrastive loss is:
$\mathcal{L}_{\text{contrast} = -\frac{1}{N}\sum_{n=1}^{N}\text{log}\frac{e^{\text{sim}(\bm{o}_n^{\text{full},\bm{o}_n^{\text{full+})}/\tau}{\sum_{j=1}^{N}(e^{\text{sim}(\bm{o}_n^{\text{full},\bm{o}_j^{\text{full+})/\tau}+e^{\text{sim}(\bm{o}^{\text{full}_n,\bm{o}_j^{\text{prev})/\tau})}.$
The final loss function combines the MLM loss and the contrastive loss:
$\mathcal{L}_{\text{DAP-train} = \mathcal{L}_{\text{MLM} + \lambda\mathcal{L}_{\text{contrast}.$
Compute Importance of Units for the Current Domain
After training a new domain t, the importance of units is learned by applying Eq.~\ref{eq:importance} for the domain, using the MLM loss. The resulting Il(t) is used in the next task by accumulating with the previously accumulated importance and soft-masking the learning.
Experimental Results
The paper evaluates DAS using six unlabeled domain corpora and their corresponding end-task classification datasets. The baselines include non-continual learning (Non-CL) and continual learning (CL) methods. The results indicate that DAS outperforms all baselines and achieves the best knowledge transfer, demonstrated by a negative forgetting rate. DAS is slightly better than Pool on average, and achieves both forgetting prevention and knowledge transfer. Directly learning the domains within the LM helps DAS achieve better results than adapter and prompt based methods, and using the full LM to learn all tasks makes DAS more effective than using sub-networks. The effectiveness of the proxy KL-divergence loss is demonstrated by comparing it with a sample set of D0 and by comparing general knowledge computed from different domain corpora. Ablation studies validate the contribution of initialization, soft-masking, and contrastive learning.
Conclusion
The paper introduces DAS, a method for continual DAP-training of LMs that incorporates soft-masking and contrastive learning. The key ideas involve preserving previous knowledge, using a novel proxy to compute unit importance, and learning complementary representations. The method achieves gains in both forgetting prevention and knowledge transfer.

