- The paper introduces a novel single-point annotation technique that simplifies text spotting and minimizes manual labeling requirements.
- It utilizes an Instance Assignment Decoder (IAD) and a Parallel Recognition Decoder (PRD) to perform localization and recognition concurrently.
- The framework achieves 19x faster inference with fewer parameters while surpassing benchmarks like ICDAR and Total-Text.
Overview of SPTS v2: Single-Point Scene Text Spotting
The paper "SPTS v2: Single-Point Scene Text Spotting" presents a novel approach for text spotting in images using only a single-point annotation methodology. The SPTS v2 framework is developed to reduce the manual annotation effort and to perform end-to-end scene text spotting more efficiently than previous methods. The paper details a number of innovative strategies, including an Instance Assignment Decoder (IAD) and a Parallel Recognition Decoder (PRD) that allow the system to operate with fewer parameters and at significantly higher speeds.
Key Contributions
Simplified Annotation and Efficiency Gains
Traditionally, scene text spotting methods rely on bounding box annotations, which are manually intensive and complex. The authors propose using single-point annotations, drastically reducing the annotation workload while maintaining competitive performance.

Figure 1: Existing OCR methods typically use bounding boxes to represent the text area. However, inspired by how humans can intuitively read texts without such a defined region, this paper demonstrates that a single point is sufficient for guiding the model to learn a strong scene text spotter.
SPTS v2 achieves substantial efficiency gains by significantly reducing both the number of parameters and the inference time, achieving 19x faster performance compared to the previous state-of-the-art single-point text spotting techniques.
Architecture: Instance Assignment and Parallel Recognition Decoders
The proposed architecture relies on an innovative dual-decoder strategy, which uses a shared set of decoder parameters for both text localization and recognition tasks:
- Instance Assignment Decoder (IAD): Predicts the coordinates of the center points for all text instances. This step leverages an auto-regressive mechanism to identify text locations within a sequence of points.
- Parallel Recognition Decoder (PRD): Conducts simultaneous recognition of text using these center points as guides. This decoder parallelizes the recognition task across multiple identified instances, significantly decreasing processing time.
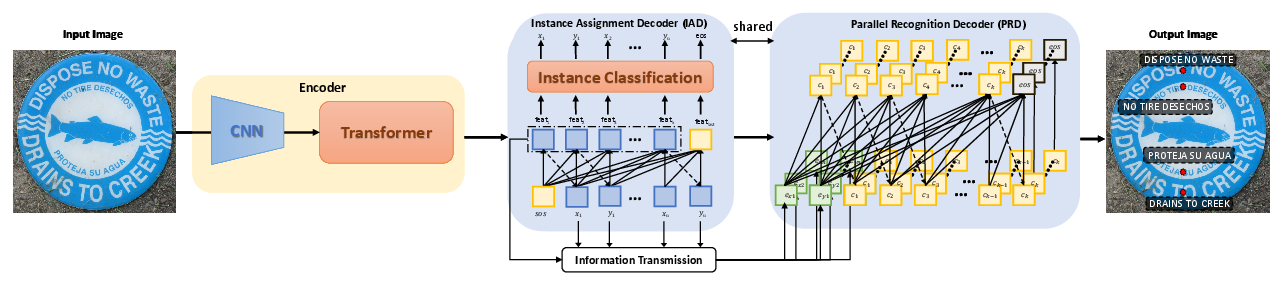
Figure 2: Overall framework of the proposed SPTS v2. The visual and contextual features are first extracted by a series of CNN and Transformer encoders. Then, the features are auto-regressively decoded into a sequence that contains localization and recognition information through IAD and PRD, respectively. For IAD, it predicts coordinates of all center points of text instances inside the same sequence, while for the PRD, the recognition results are predicted in parallel. Note that IAD shares identical parameters with PRD, and thus no additional parameters are introduced for the PRD stage.
Experimental Results
The experiments conducted reveal that SPTS v2 outperforms previous state-of-the-art models across several text spotting benchmarks. These include datasets such as Total-Text, SCUT-CTW1500, ICDAR 2013, and ICDAR 2015. Notably, SPTS v2 shows strength in handling arbitrarily-shaped text detection and efficiently utilizing single-point annotations.









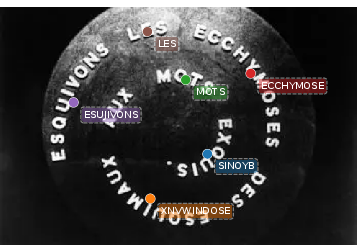
Figure 3: Qualitative results on the scene text benchmarks. Images are selected from Total-Text (first row), SCUT-CTW1500 (second row), ICDAR 2013 (third row), ICDAR 2015 (fourth row), and Inverse-Text (fifth row). Best viewed on screen.
Implications and Future Work
The shift towards a single-point annotation approach has significant implications for the practical adoption of scene text spotting technologies. By minimizing manual annotation efforts and improving speed, more resources can be dedicated to enhancing model performance and exploring new application domains. In the future, extending SPTS v2 to support additional languages and more complex text configurations can further its applicability.
Conclusion
SPTS v2 shows that it is possible to perform efficient and powerful text spotting using a minimalist annotation approach. This method not only suggests potential cost savings and efficiency improvements in creating datasets but also opens new doors for scalable real-world applications in document processing, autonomous driving, and augmented reality. The integration of deep learning with intuitive human-like recognition tasks marks an important step forward in AI-driven text processing technologies.

