- The paper introduces an integrated end-to-end network that combines text detection and recognition to handle arbitrary text shapes.
- It leverages a modified Mask R-CNN with a Feature Pyramid Network and spatial attentional modules for effective segmentation and recognition.
- The model achieves state-of-the-art performance on benchmarks like ICDAR and COCO-Text, excelling especially in curved text detection.
Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes
Introduction
The paper introduces Mask TextSpotter, an innovative framework designed to tackle the challenges of scene text spotting—a task that requires simultaneous text detection and recognition. Unlike traditional approaches that separate detection and recognition, Mask TextSpotter combines these tasks into a single end-to-end network, leveraging semantic segmentation to handle text with arbitrary shapes. This integration aims to overcome the sub-optimal performance often encountered when these tasks are addressed independently.
Model Architecture
Mask TextSpotter relies on a modified Mask R-CNN architecture (Figure 1) that incorporates a Feature Pyramid Network (FPN) backbone, a Region Proposal Network (RPN) for generating text proposals, and a mask branch for text instance and character segmentation. The architecture is unique in its ability to detect and recognize text instances directly from two-dimensional space, employing a spatial attention module to enhance performance. This approach distinguishes itself by handling irregular text shapes, such as curved text, more effectively than sequence-to-sequence models designed for one-dimensional sequences.
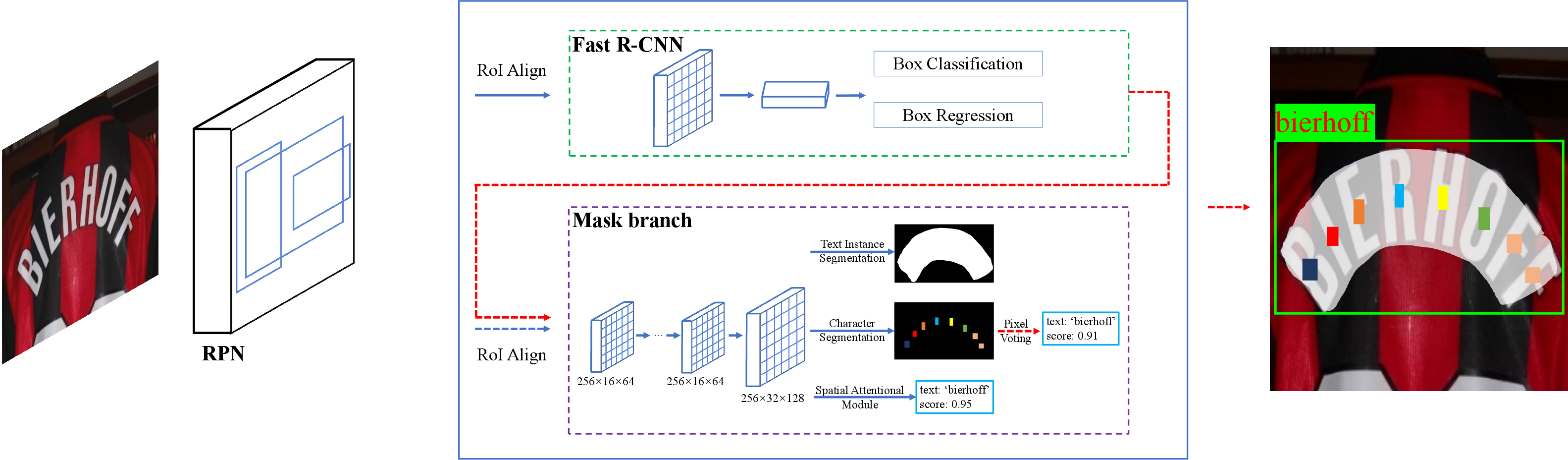
Figure 1: Architecture of Mask TextSpotter. The solid arrows mean the data flow both in training and inference period. The dashed arrows in blue and in red indicate the data flow in training stage and inference stage, respectively.
Text Instance and Character Segmentation
The mask branch of Mask TextSpotter includes two critical tasks: text instance segmentation and character segmentation. The network outputs character maps where each pixel is classified into a character class, allowing the model to predict text directly from the segmentation maps. These outputs facilitate the detection of text regions and the subsequent grouping of characters into words.
Spatial Attentional Module (SAM)
The SAM further refines the recognition process. By leveraging spatial attention mechanisms, Mask TextSpotter can globally predict the label sequence of each word irrespective of its shape. This module, illustrated in Figure 2, operates on the two-dimensional feature map directly, ensuring that both local and global text information is utilized effectively.
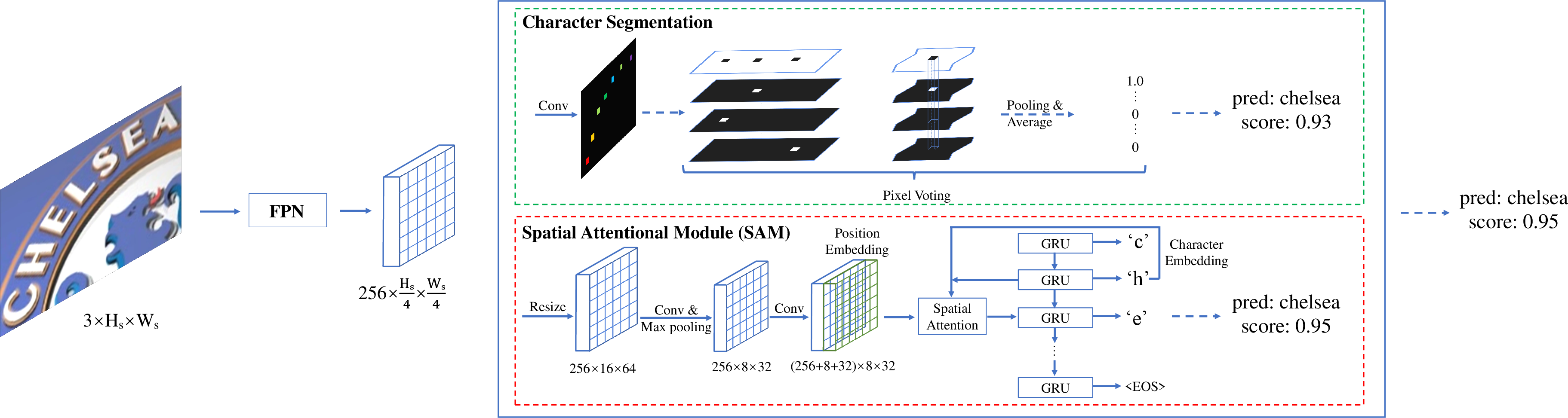
Figure 2: Architecture of the standalone recognition model. We use a feature-pyramid structure with ResNet-50. Note that both the two modules can provide the recognition results along with their confidence score, we select the final recognition result with a higher confidence score dynamically.
Training and Optimization
The network undergoes two-stage training: pre-training on SynthText datasets and fine-tuning on real-world datasets like ICDAR 2013, ICDAR 2015, and COCO-Text. Data augmentation techniques and multi-scale training are employed to handle variations in the text presentation. The multi-task loss function is carefully designed to balance between RPN, Fast R-CNN, and mask branch losses efficiently.
Mask TextSpotter achieves state-of-the-art performance across a range of datasets, particularly excelling in detecting and recognizing text with arbitrary shapes (Table 1). It surpasses existing methods, especially when dealing with curved text, highlighting its robustness and applicability to real-world scenarios.
Conclusion
Mask TextSpotter represents a significant advancement in the field of scene text spotting. Its ability to seamlessly integrate detection and recognition into a unified framework while handling diverse text shapes offers enhanced accuracy and utility. Future improvements may focus on optimizing inference speed and exploring alternative detection strategies to reduce computational overhead.
- Figure 3: Illustrations of different text spotting methods, highlighting the capability of Mask TextSpotter to handle varied text orientations.
- Figure 1: Detailed architecture of Mask TextSpotter, showing the integration of detection and recognition processes.
- Figure 2: The standalone recognition model architecture, emphasizing the feature-pyramid structure and dynamic result selection.
These figures collectively underscore the technical sophistication of Mask TextSpotter and its practical efficacy in complex text spotting environments.

