- The paper presents a novel framework leveraging differentiable physics for efficient gradient-based training of NN controllers.
- It integrates periodic activation functions, tailored loss functions, and GPU-accelerated simulations to achieve robust outcomes in diverse locomotion tasks.
- Experimental comparisons reveal significant improvements over PPO in training efficiency and task convergence, highlighting potential for advanced robotics.
Complex Locomotion Skill Learning via Differentiable Physics
Introduction
The paper "Complex Locomotion Skill Learning via Differentiable Physics" (2206.02341) introduces a framework for training neural network (NN) controllers using differentiable physics. This approach allows for efficient gradient-based optimization, enabling controllers to perform complex and diverse locomotion tasks. The authors enhance existing methodologies by integrating periodic activation functions, Adam optimization, and a suite of tailored loss functions, demonstrating superiority over traditional reinforcement learning methods such as Proximal Policy Optimization (PPO).
Differentiable Simulation Environments
The framework leverages differentiable physically-based simulators, specifically focusing on mass-spring systems and the Moving Least Squares Material Point Method (MLS-MPM). These simulators serve as black boxes, taking in actuation signals and outputting the subsequent state, allowing the NN controller to adjust its actions based on gradient feedback.
The framework supports a range of agent designs, from simple to complex geometries, as illustrated in the figures of 3D and 2D agents (Figures 2 and 3). Actuation is modeled along muscle directions, with signals in the range of [-1, 1] to control contraction and relaxation.

Figure 1: 3D agents collection. These agents are designed with simple stacked cubes or complex handcrafted meshes.
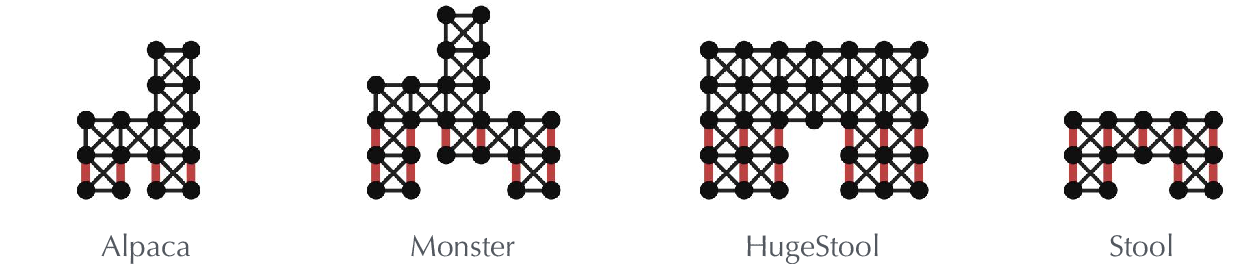
Figure 2: 2D agents collection.
Learning Framework
The learning process is structured around an end-to-end differentiable pipeline, with simulation instances executed in parallel on GPUs (Figure 3). The NN controllers, inspired by the SIREN architecture, are optimized using gradients derived from physical simulations. This approach ensures robustness and generalizability across a variety of tasks, such as running, jumping, and rotating.
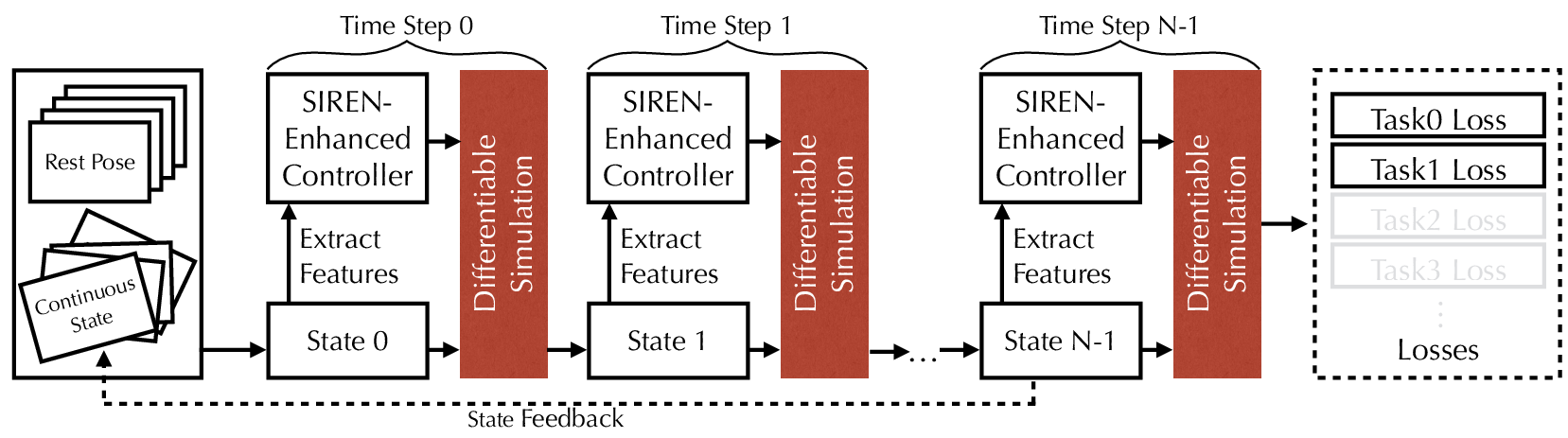
Figure 3: Framework overview. Simulation instances are batched and executed in parallel on GPUs.
Task Representation and Loss Functions
Tasks are encoded via target velocities and heights, with agents expected to switch goals seamlessly. The loss functions are designed to incorporate periodicity, delayed evaluation, and fluctuation tolerance, crucial for effective locomotion. The tailored task loss considers running, jumping, and crawling, while a regularization term penalizes excessive actuation effort.
Results and Analysis
Extensive experiments underscore the effectiveness of the proposed framework. An ablation study conducted on various agents evaluates the contributions of different components such as periodic signals and state vectors, highlighting the necessity of each for optimal performance (Figure 4). Additionally, the framework exhibits stable gradient distributions, crucial for training longevity and network stability (Figure 5).
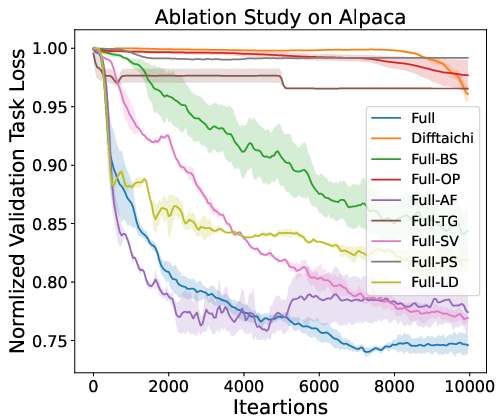
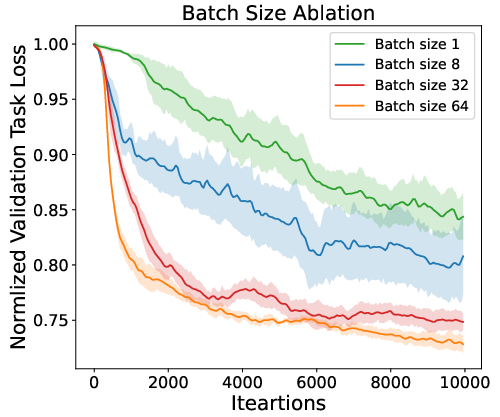
Figure 4: Summary of the ablation study. The Full method achieves the best performance.
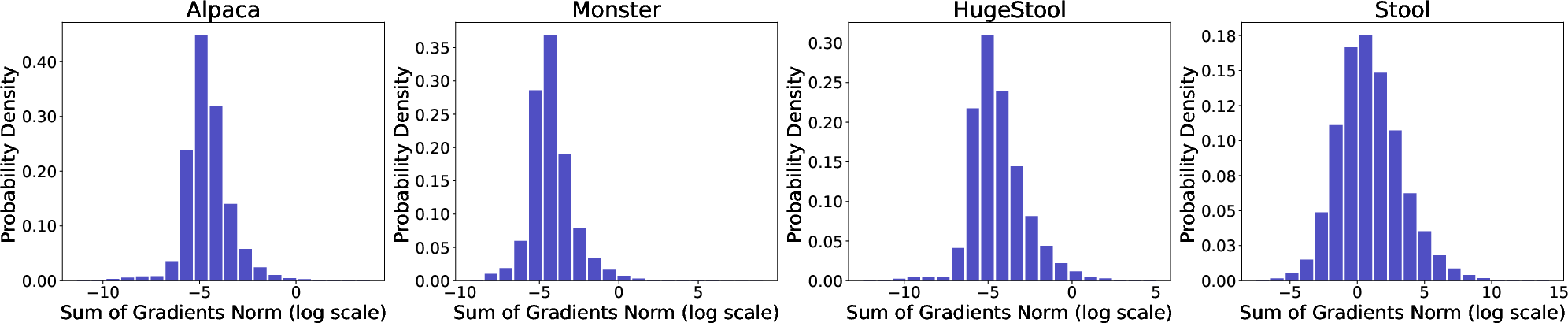
Figure 5: Gradient Analysis. The plots show the gradient distribution of different agents.
Comparison with Reinforcement Learning
The authors provide a comparative analysis against PPO, showcasing significant improvements in training efficiency and task convergence. This is particularly evident in the integrated ability of the proposed method to handle multiple goals concurrently. The framework's robustness and efficacy in complex environments contrast sharply with the limitations of RL-based approaches, which often struggle with local minima and goal balancing (Figure 6).
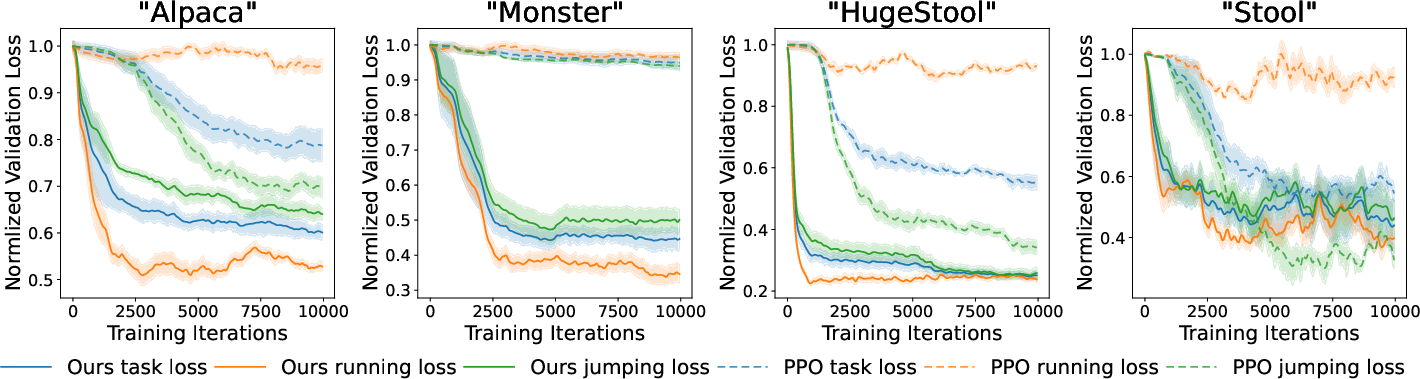
Figure 6: Comparison on different agents. Both our method and PPO run on GPUs.
Conclusion
The proposed differentiable physics framework for locomotion skill learning demonstrates a significant advancement in the training of NN controllers for complex tasks. The framework's ability to deliver robust, flexible, and efficient controllers paves the way for future applications in soft robotics and interactive environments. Future research could explore automated optimization of robot designs and physical parameters, further enhancing the practical implications of this study.