- The paper's primary contribution is the introduction of an end-to-end RL framework that effectively trains humanoid robot locomotion policies.
- It employs an Asymmetric Actor-Critic architecture with PPO and domain randomization to improve sim-to-real policy transfer.
- Experimental results demonstrate robust locomotion, including omnidirectional walking and push recovery, in diverse real-world scenarios.
Booster Gym: An End-to-End Reinforcement Learning Framework for Humanoid Robot Locomotion
Introduction and Overview
The paper "Booster Gym: An End-to-End Reinforcement Learning Framework for Humanoid Robot Locomotion" introduces a comprehensive RL framework tailored for training and deploying locomotion policies on humanoid robots. The framework addresses the critical sim-to-real transfer challenge by encompassing the entire pipeline from simulation training to real-world deployment. In this work, domain randomization and robust policy generalization are emphasized to facilitate seamless policy transfer and adaptation across diverse environments.
The study employs a POMDP-based formulation to model the humanoid robot control problem, utilizing an Asymmetric Actor-Critic (AAC) architecture coupled with Proximal Policy Optimization (PPO) to optimize the control policies. This involves a detailed process of balancing exploration and exploitation via clipped surrogate objectives, as described in the extensive formulation of the RL algorithms. Specifically, the AAC framework uses an actor with proprioceptive observations and a critic, incorporating privileged simulator information to ameliorate the value estimation process.

Figure 1: Training, testing, and deployment on Booster T1 across multiple environments.
The observation and action spaces are adeptly defined to reflect the complexities of real-world applications involving proprioceptive feedback, enabling the actor network to execute finely-tuned joint position offsets via a PD controller. The overall architecture facilitates consistent interaction in simulation environments mimicking physical hardware.
Domain Randomization and Sim-To-Real Transfer
To bridge the sim-to-real gap, the paper introduces an extensive domain randomization strategy targeting variations in robot body dynamics, actuator characteristics, and environmental conditions. This approach yields a robust RL policy that proves effective across a multitude of real-world scenarios, maintaining adaptability and resilience against unexpected disturbances. The results also underscore the framework's efficacy in diverse terrains using a common policy, demonstrating competency in height-based foot positioning for gait analysis.
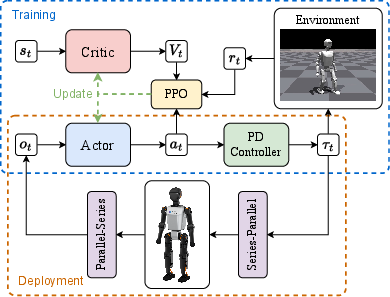
Figure 2: An overview of the control architecture for training and deployment.
The framework's success in real-world deployment is augmented by the deployment infrastructure, which includes a Python-based SDK for seamless policy execution on humanoid platforms. This integration facilitates ease-of-use while maintaining strong alignment with predefined performance metrics, showcasing efficient policy execution with minimal latency disturbances.
Experimental Evaluation
Comprehensive experiments validate the framework's capabilities in executing complex locomotion tasks, such as omnidirectional walking and robust push recovery operations. The adaptive capacities of the RL framework are vividly demonstrated, with real-world trials illustrating the efficacy of the deployed control policies in maintaining stability and maneuverability in challenging conditions.

Figure 3: Omnidirectional walking. (a) Forward. (b) Backward. (c) Rotation. (d) Sideways.

Figure 4: Walking on a 10-degree slope. Upper: Forward. Lower: Sideways.
The paper reports successful implementation of fundamental locomotive functions, highlighting how real-time adjustments in policy outputs enable the robot to maintain balance and respond effectively to both immediate and sustained external forces.
Conclusion
The Booster Gym framework stands out as a valuable contribution to the field of humanoid robotics, providing a streamlined, open-source solution capable of profound impact within the robotics community. By incorporating domain randomization and versatile RL components, the framework offers a robust methodology for developing and deploying real-world locomotion strategies. Future work should focus on extending the framework's capabilities, potentially broadening the set of applicable tasks and enhancing the automation of policy adaptation for further advances in humanoid robotics.

