- The paper presents a novel approach that integrates Residual Policy Learning with differentiable simulation to refine quadruped control policies.
- It leverages first-order policy gradients via Backpropagation Through Time and Analytical Policy Gradients to boost sample efficiency and stability.
- Experimental results show up to 60% improvement over traditional methods, highlighting significant gains in asymptotic rewards and robustness.
Residual Policy Learning for Perceptive Quadruped Control Using Differentiable Simulation
This paper presents a novel approach to quadrupedal control through the use of Residual Policy Learning (RPL) integrated with differentiable simulation techniques. The focus is on enhancing the sample efficiency and performance of robotic locomotion, especially in contact-rich environments. The paper emphasizes the benefits of First-Order Policy Gradient methods, such as Backpropagation through Time (BPTT) and Analytical Policy Gradients (APG), for improving policy learning. The authors investigate the use of a residual policy-learning paradigm to anchor and refine policy search processes, thereby enhancing rewards and stability in complex robotic tasks.
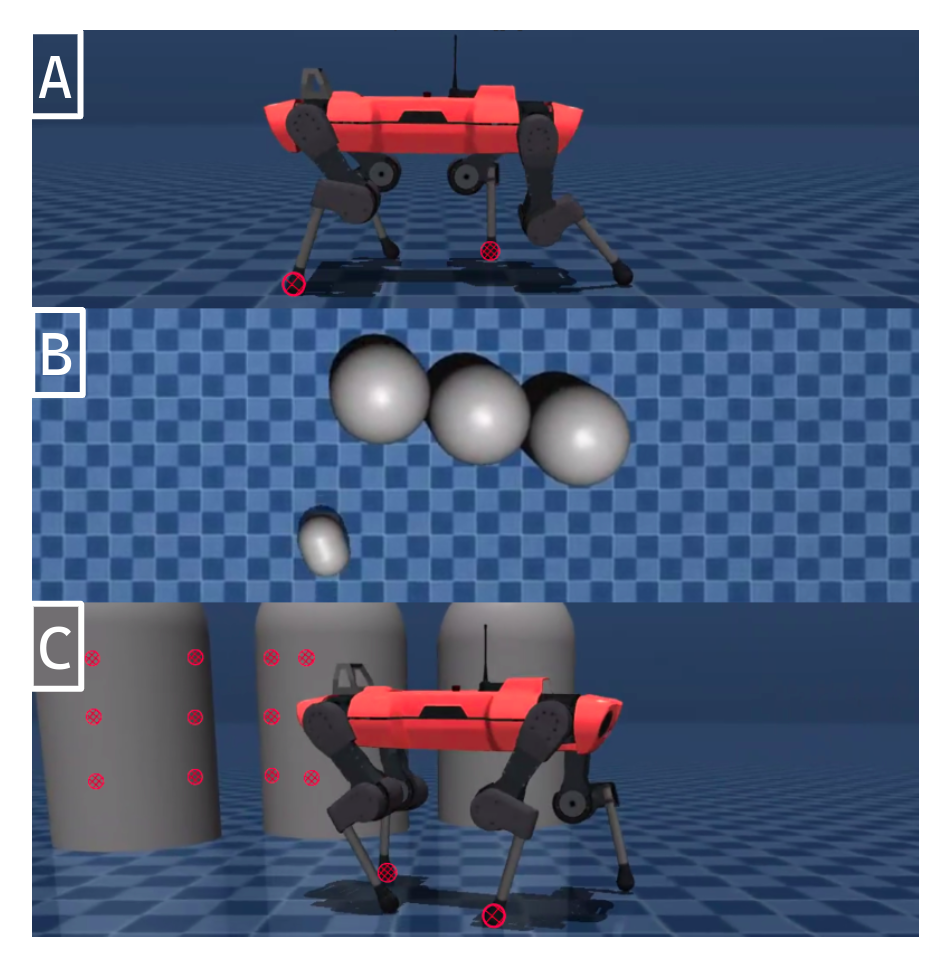
Figure 1: We apply differentiable simulation to learn A: walking, B: vision-based local navigation, C: walking around obstacles.
Methodology
Differentiable Simulation
Differentiable simulation tools have seen increasing application in policy learning due to their ability to compute analytical gradients. This paper utilizes the Mujoco MJX as a differentiable simulator to compute first-order gradients, specifically leveraging BPTT and APG. Differentiable simulators are particularly suited for tasks with smooth dynamics; however, they struggle in contact-rich scenarios, which often result in a non-smooth loss landscape. The authors address these challenges through an RPL approach that fine-tunes actions by learning a residual over a simple baseline policy.
Backpropagation Through Time
In contact-rich tasks where standard reinforcement learning may fall short due to high gradient variance, BPTT remains an efficient tool for gradient calculations through structured environments. The method directly differentiates through simulation computations, though it encounters difficulties with gradient stability over lengthy sequences. The integration of Short-Horizon Actor-Critic (SHAC) enhances BPTT by allowing for truncated yet informed roll-outs, effectively bypassing some of these limitations.
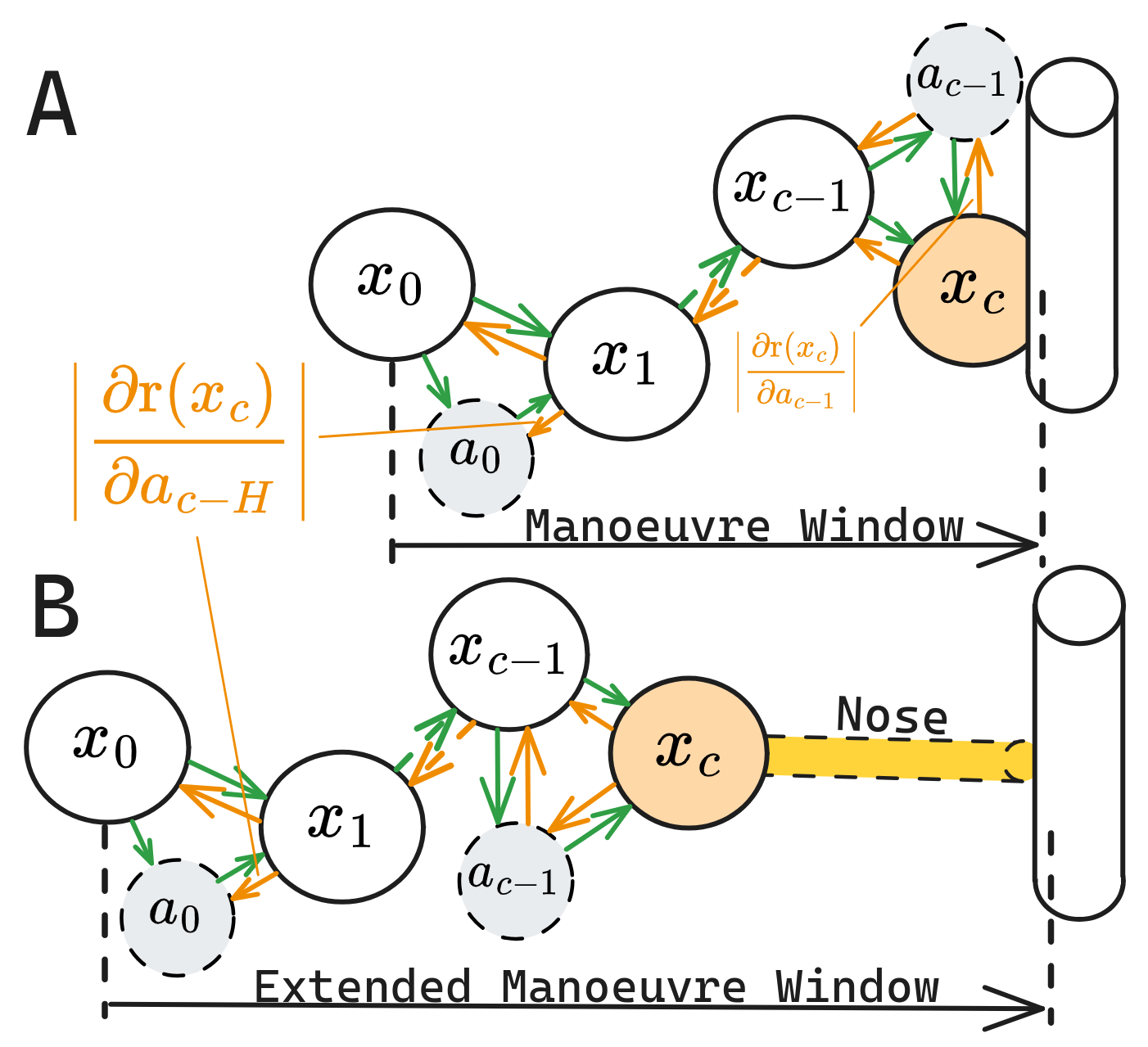
Figure 2: The Pinocchio Trick. Green denotes forward simulation, while yellow indicates gradient flow from the collision event.
Residual Policy Learning
RPL entails adjusting a learned policy around a predefined anchor policy. In this framework, the training objective extends over a baseline policy, creating a step-by-step improvement process incorporating minimal variance actions, highlighted by minimized initial layer weight magnitudes. The learned residual primarily aims at refining the policy's robustness and asymptotic performance rather than merely optimizing sample efficiency.
Results
The study demonstrates enhanced policy performance through RPL with FoPGs, indicating significant gains in asymptotic rewards compared to models solely using ZoPGs. The experiments reveal that SHAC RPL offers substantial improvements: up to 60% over traditional frameworks like SHAC and 25% over PPO. The integration of RPL with FoPG enhances both the effectiveness and stability of SSA for quadrupedal locomotion tasks.
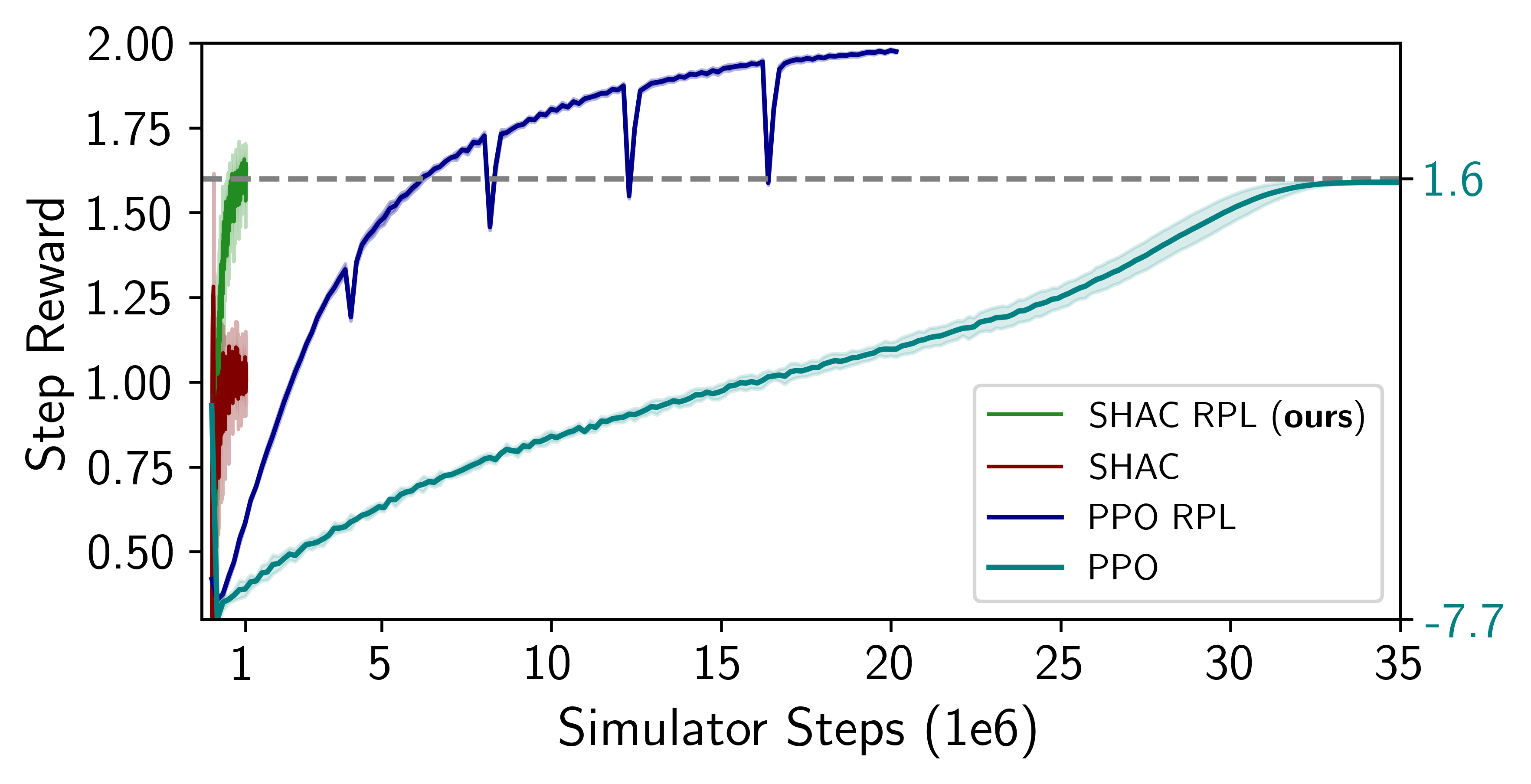
Figure 3: Learning blind locomotion. Residual Policy Learning increases asymptotic rewards for SHAC and PPO by 60\% and 25\%, respectively.
Discussion
Benefits and Trade-offs
The integration of RPL with FoPG in quadrupedal robots offers a unique balance between sample efficiency and robustness, effectively guiding policy searches through complex terrains. The method capitalizes on differentiable simulation's capability to handle detailed policy gradient computation while mitigating its limitations through the application of a stable anchor policy.
Challenges
While FoPG combined with RPL facilitates targeted policy improvements, challenges remain in scaling these frameworks to various locomotion styles and more dynamic environments. Furthermore, the current implementation's effectiveness primarily references the controlled simulation settings and simple trotting scenarios.
Conclusion
The research highlights the advantages of RPL within a differentiable simulation environment to foster more robust and efficient quadruped controllers. The deep integration of FoPG methods within SHAC frameworks helps mitigate traditional RL challenges, particularly in contact-heavy tasks. This work paves the way for further exploration in combining differentiable physics with policy learning paradigms, promising potential enhancements in real-world robotic control and deployment.
The paper's contribution lies in offering a structured approach to RPL with FoPGs, maintaining stability, and addressing inherently complex simulation issues, establishing groundwork for future AI developments in robotic autonomy.