- The paper proposes that the attention mechanism in MAEs functions as a learnable integral kernel, boosting representation power via Barron space.
- It demonstrates that patchifying images preserves key details while reducing computational cost under low-rank image assumptions.
- The decoder is shown to be crucial for the global interpolation of masked patches, ensuring stable representation across network layers.
Understanding Masked Autoencoders: A Theoretical Exploration
Introduction
The paper "How to Understand Masked Autoencoders" (2202.03670) presents an innovative theoretical framework offering insights into the structure and function of Masked Autoencoders (MAE). The authors aim to bridge the existing gap in understanding the expressivity of MAEs, their impact on image pretraining, and their potential to integrate visual and linguistic pretraining paradigms. This essay explores the foundation laid by the authors, elucidating the mathematical principles underpinning MAE, particularly focusing on the patch-based attention mechanisms formulated as integral kernels.
Architecture and Theoretical Framework
At the core of this research is the interpretation of MAE's architecture through operator theory. The paper exploits a non-overlapping domain decomposition setting to analyze the expressivity of the patch-based attention mechanism employed by MAEs. This method is juxtaposed against the traditional Vision Transformers (ViT), revealing how embedding images as patch sequences operates as learned basis functions within Hilbert spaces.
Visual Overview:
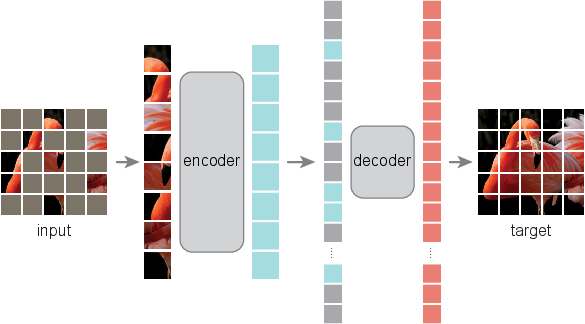
Figure 1: Architecture of the Masked Autoencoder (MAE) based on the Vision Transformer (ViT) backbone.
Key Contributions
- Representation Formation and Optimization: The paper proposes that the attention mechanism in MAE acts similarly to a learnable integral kernel transform. This mechanism dynamically enhances representation power through Barron space with positional embeddings functioning as high-dimensional feature space coordinates.
- Patchifying and Computational Efficiency: Patch selection aids MAEs by preserving essential image information while reducing computational costs, especially under low-rank image assumptions. This theoretical foundation strengthens the use of patch-based neural networks.
- Stable Representation Across Layers: MAEs demonstrate stable representation propagation across network layers. The learned attention kernel ensures that feature representations evolve continuously and reliably, as shown by rigorous stability proofs that the scaled dot-product attention provides.
- Role of the Decoder: Contrary to assumptions that place little emphasis on the decoder, this research argues its critical role in enhancing encoder representations. The decoder's broader patch dimension enables the encoder to enrich its representation space using Barron functions for superior basis learning.
- Global Interpolation of Masked Patches: The study posits that the reconstruction of masked patches in MAEs is a global interpolation task. Latent representations of the masked patches are globally interpolated using a topology learned by the attention mechanism, which is crucial for high-quality image reconstruction.
Theoretical Insights and Implications
The theoretical model proposed in this paper can enhance understanding across various self-attention based models beyond MAEs, such as ViTs. This understanding is crucial as it provides a mathematical basis for designing self-supervised learning architectures in both visual and linguistic domains. The intricate mathematical framework introduced can serve as a lens through which the characteristics of extensive patch and self-attention networks can be analyzed and optimized.

Figure 2: The i-th patch embedding from the scaled dot-product attention is represented as a convex combination.
Practical and Theoretical Prospects
The paper's insights into MAE and patch-based attention mechanisms present implications for future research and practical applications. As artificial intelligence continues to evolve, incorporating theoretical principles like these will enable more powerful and efficient models. This theoretical understanding can inform the development of future architectures, potentially leading to new innovations in AI-driven image analysis and understanding.
Conclusion
The research done in "How to Understand Masked Autoencoders" offers a foundational theoretical explanation for MAEs and their success in self-supervised learning. By extending operator theory and leveraging insights from mathematical theory, the paper provides a framework that not only explains existing advantages but also paves the way for future exploration and development of self-attention and patch-based networks. The implications of this research extend beyond immediate applications, suggesting pathways for future theoretical and practical advancements in AI technology.

