- The paper presents a semi-supervised hard attention model (SSHA) that leverages reinforcement learning to detect and localize violent scenes in surveillance videos.
- It employs a dual-stream architecture integrating RGB and optical flow inputs with pretrained I3D backbones, achieving a 90.4% accuracy on the RWF dataset.
- The study demonstrates that hard attention mechanisms effectively focus computational resources, reducing the need for precise region annotations in video violence detection.
Video Violence Recognition and Localization Using a Semi-Supervised Hard Attention Model
This paper presents a semi-supervised approach to video violence recognition and localization through a model named Semi-Supervised Hard Attention (SSHA). SSHA leverages reinforcement learning concepts to enhance the detection of violent acts captured by surveillance video footage.
Introduction to SSHA
The rapid proliferation of surveillance cameras globally demands scalable AI systems capable of processing vast quantities of video data. Video violence detection has emerged as a critical challenge, traditionally addressed with supervised learning techniques. The SSHA model introduces a novel semi-supervised approach, utilizing hard attention to focus computational resources on the most informative regions of a video frame, thereby improving classification accuracy without location-specific labels.
Reinforcement Learning and Attention Mechanisms
The SSHA model relies on reinforcement learning methods to implement hard attention. It addresses the absence of regional annotations in datasets, leveraging reinforcement learning to dynamically learn the regions of interest based on video-level annotations. This is accomplished through a defined set of prior boxes that the model uses to focus on different parts of the input frame (Figure 1).

Figure 1: Prior boxes defined on the input frame.
The SSHA's hard attention mechanism is grounded in selecting regions of interest from a predefined set of prior boxes, which streamlines the search process and allows the model to concentrate computational resources more effectively (Figure 2).
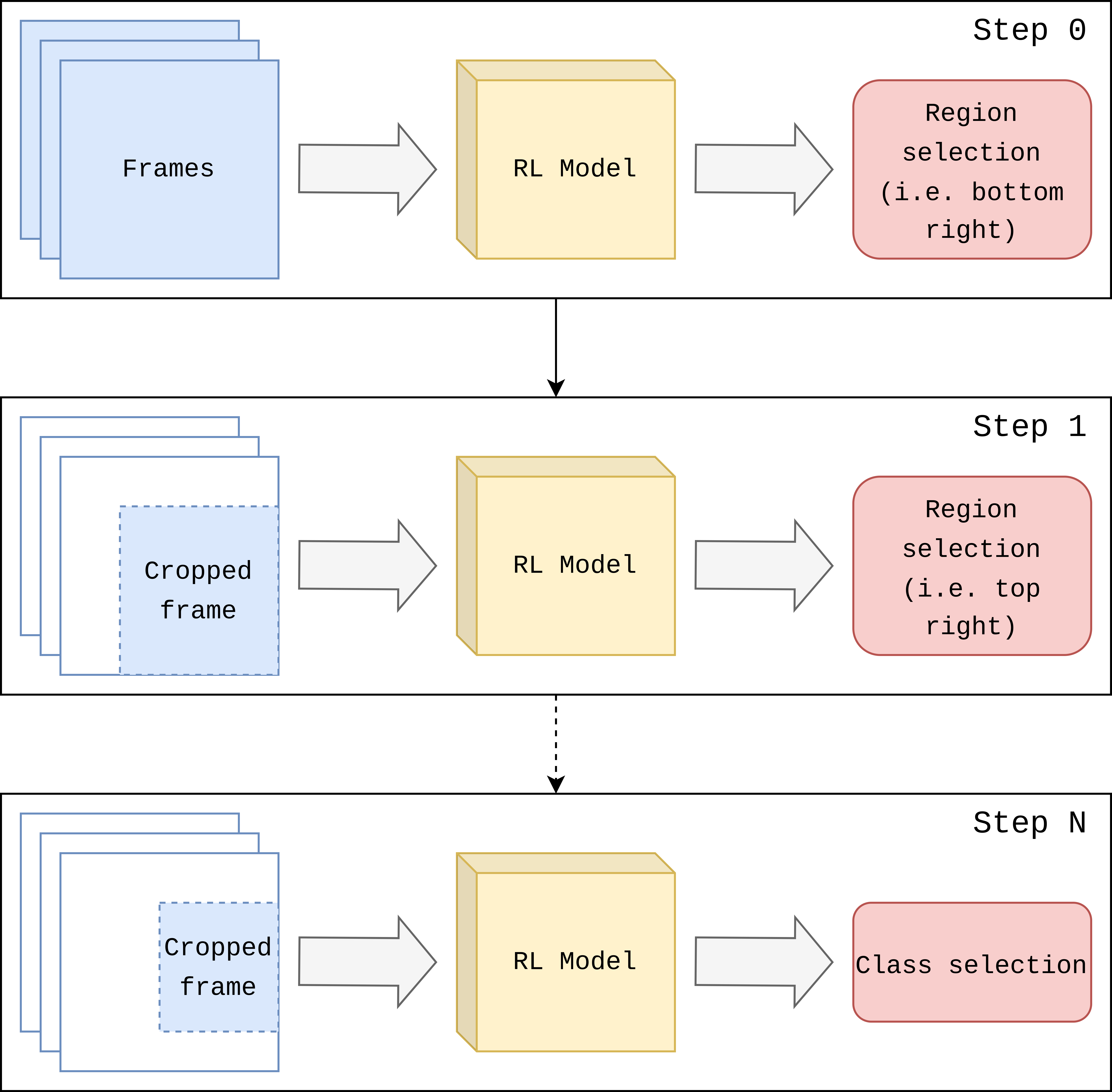
Figure 2: Model interaction with an input video.
Model Architecture
The SSHA model is embedded with a dual-stream architecture to handle RGB and optical flow inputs, separately optimizing each stream with pretrained I3D backbones (Figure 3). Optical flow frames are computed using the TV-L1 algorithm, which is integral to generating precise motion vectors necessary for violence detection.

Figure 3: SSHA model architecture (RBG only).
This architecture can be expanded using a two-stream structure where RGB features are systematically fused with optical flow features through multiplication, enhancing the model's ability to recognize temporal interdependencies (Figure 4).

Figure 5: SSHA model architecture (Optical-flow only).
Figure 4: SSHA model architecture (Two-stream fusion).
Training Strategy
SSHA's training process employs Q-learning, reinforcing the model through iterative value evaluation, where a reward system guides the learning algorithm towards achieving optimal region selection and classification. The training involves a progressive exploration mechanism to stabilize the model's learning process and prevent overfitting.
Experimental Results
Evaluation demonstrates SSHA achieves state-of-the-art results on prominent datasets, notably the RWF dataset, with an accuracy of 90.4%. The model outperforms existing methods leveraging RGB-only inputs by integrating focused regions through hard attention. The SSHA demonstrated statistically significant improvements in violent scene detection across varied datasets, effectively utilizing its streamlined architecture to balance computational efficiency and accuracy.
Conclusion
The SSHA model exemplifies the potential of reinforcement learning paired with hard attention mechanisms to enhance video violence detection. It effectively bypasses the need for precise region annotations, presenting a scalable solution suitable for application in modern surveillance networks. Future work may explore extending SSHA's framework to general action recognition tasks and integrating collaborative multi-agent systems to further enhance monitoring capabilities across diverse environments.
The findings of this study advocate for further exploration into scalable, cost-effective auxiliary methods to improve task-specific neural networks, potentially broadening the application of SSHA beyond violence detection to various video analysis domains.