- The paper introduces a hybrid neural network architecture leveraging EfficientNet, LSTM/GRU, and optical flow to enhance spatio-temporal feature extraction for violence detection.
- It employs EfficientNet-B0 for spatial feature extraction and recurrent neural networks for modeling temporal dynamics, thus balancing efficiency and accuracy.
- Experimental results on hockey, Violent Flow, and real-life datasets demonstrate superior detection performance in structured settings and highlight challenges in complex scenes.
Violence Detection in Videos Using Deep Recurrent and Convolutional Neural Networks
The paper introduces a novel architecture for detecting violence in video sequences, focusing on integrating neural networks with optical flow techniques to enhance spatio-temporal feature extraction. The proposed approach leverages both recurrent neural networks (RNNs) and two-dimensional convolutional neural networks (2D CNNs) in a dual-block configuration to process RGB frames and computed optical flow data from video sequences. The addition of optical flow aids the architecture in encoding motion information, which is crucial for identifying violent scenes.
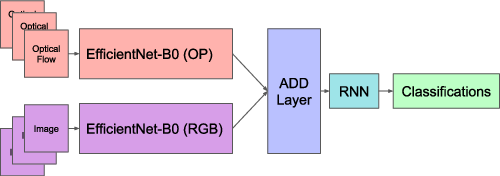
Figure 1: Proposed architecture pipeline.
Convolutional Neural Networks
EfficientNet serves as the core convolutional network in each block, utilizing the MBCONV structure to capture spatial features effectively. EfficientNet is selected for its compound scaling capabilities and inference efficiency. The network is augmented with squeeze-and-excitation blocks, enabling adaptive recalibration of channel-wise feature responses to improve representational efficiency.
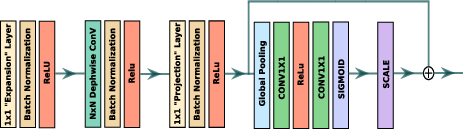
Figure 2: MBCONV block of EfficientNet.
The paper recommends deploying EfficientNet-B0, pre-trained on ImageNet, for its balance between computational efficiency and performance, facilitating robust feature extraction from RGB and optical flow inputs.
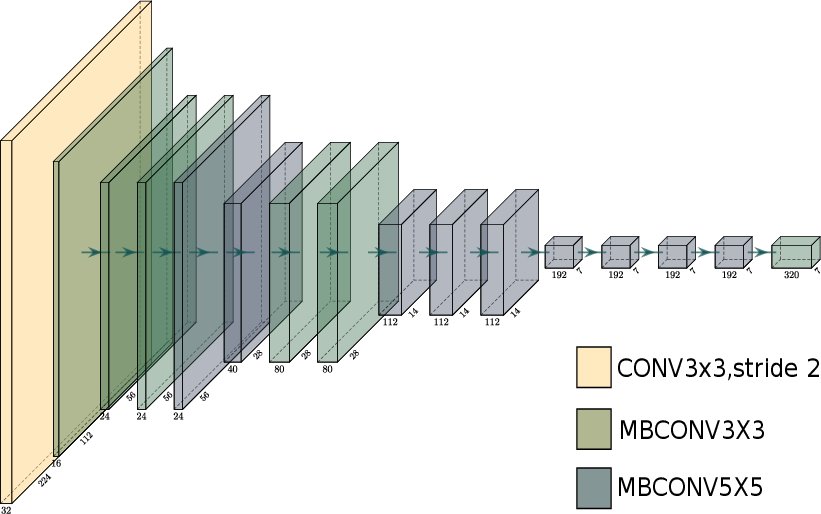
Figure 3: EfficientNetB0 used to capture spatial features.
Recurrent Neural Networks
Two variants of temporal feature extraction mechanisms are explored: Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs). LSTMs, with their intricate gating architecture—input, forget, and output gates—are employed for their ability to manage long-term dependencies effectively. On the other hand, GRUs offer computational advantages with reduced complexity and improved resilience to gradient-related issues, particularly the vanishing gradient problem often encountered in RNNs.
Optical Flow Integration
Optical flow, a technique to calculate motion vectors between consecutive frames, is addressed using the PWC-Net. This model presents a compact architecture, integrating domain knowledge to predict optical flow with high accuracy while minimizing model size. The optical flow features are crucial for encoding temporal dynamics that complement spatial features extracted from RGB data, enhancing violence detection performance.
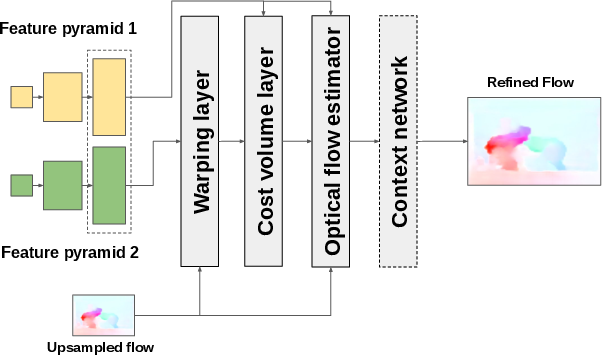
Figure 4: PWC-NET architecture.
Experiments and Results
Evaluations on various datasets—including Hockey, Violent Flow, and Real Life Violence Situations—demonstrate the architecture’s capability to match or exceed state-of-the-art methods in violence detection performance. On the Hockey dataset, the architecture achieved nearly perfect accuracy, rivaling advanced methods. However, on the Violent Flow dataset, the optical flow presented challenges when dealing with complex motion patterns in crowded scenes, indicating the necessity for advancements in optical flow estimation or alternative augmentation strategies.
Conclusion
The architecture underscores the potential of combining CNNs, RNNs, and motion-based features for improved video violence detection. Future directions might involve expanding dataset diversity and refining optical flow integration to handle challenging real-world scenarios better. Continuous benchmark testing across varied datasets will ensure the architecture’s robustness and generalizability. EfficientNet’s role as a spatial feature extractor, coupled with advanced RNNs, suggests a promising approach for comprehensive video analysis in security applications.
In summary, this paper provides a foundational framework for violence detection by synergizing multiple neural network paradigms with advanced motion processing techniques, offering insights into automated surveillance systems’ effectiveness and efficiency advancements.