- The paper demonstrates how a Bayesian Network generates synthetic documents with detailed layout annotations without manual labeling.
- It outlines a process using stochastic templates and probabilistic models to simulate real-world document diversity and spatial details.
- Models trained on this synthetic data achieve performance comparable to those trained on real annotations, with less than 4% difference.
Synthetic Document Generator for Annotation-free Layout Recognition
Introduction
The analysis and effective understanding of document layouts are pivotal for several tasks like semantic search, knowledge base population, and document summarization. The paper "Synthetic Document Generator for Annotation-free Layout Recognition" describes a methodology for generating synthetic documents using a Bayesian Network. This generative model generates realistic documents, offering ground-truth annotations for spatial positions, extents, and categories of various layout elements without requiring annotated real-world examples.
To navigate the complexity of document layout recognition, the Bayesian Network provides a causal structure for the synthetic generation process, modeling each document element as a random variable. This framework offers a solution to the costly and time-consuming process of manual annotation and enables creating a diverse set of realistic documents for training deep learning models effectively.
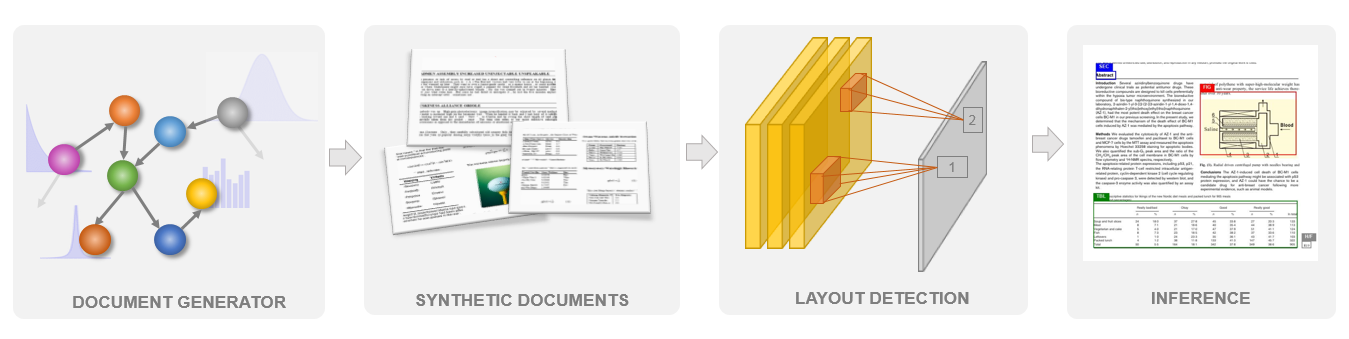
Figure 1: Overview of the approach using a Bayesian Network to construct synthetic documents, facilitating layout recognition on real documents.
Bayesian Network Dynamics
The foundation of the proposed synthetic document generator is a Bayesian Network, which treats each component of a document as a random variable with intrinsic dependencies modeled using conditional probability distributions. These variables encapsulate logical entities like headers, sections, tables, figures, etc., and model their dependencies through a Bayesian Network graph. This hierarchical structure with stochastic templates allows shared parameters across documents, thereby generating unique yet diverse layouts.
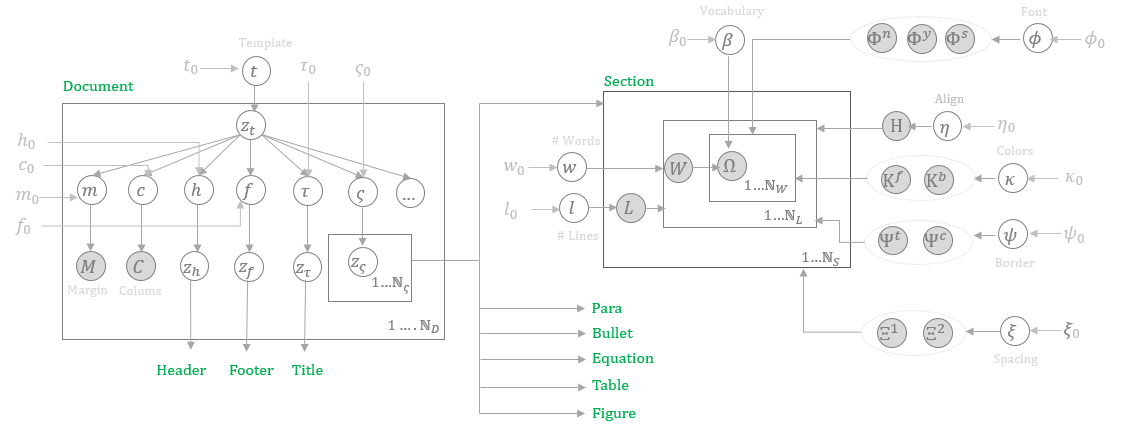
Figure 2: Cross section of the Bayesian network in plate notation, illustrating observed and prior variables.
The generation process encompasses a set of subnetworks, each dedicated to a layout element such as sections or tables, which produce the layout elements treated as graphical objects with their respective bounding boxes and categories annotated during the generative process. This results in generating coherent and annotated synthetic documents rather than relying on seeded real documents [(2111.06016)].
Document Generation
Document Subnetwork
To simulate a document, the generative process selects a template, samples document-level variables like margin, column numbers, and background color through Bayesian inference, and realizes shared variables such as font, size, and color that apply to multiple subnetworks.
The notion of stochastic templates is introduced, ensuring commonalities of layouts within domains and variations across domains. Each sampled document is rendered onto an image lattice, recording the spatial characteristics of each layout element.
Generative Process
Through Bayesian Network, each document component, from graphical units like character glyphs, geometric shapes, to font and style attributes, is treated as a random variable with specific prior distributions. Sampling is achieved through predefined distributions like Gaussian, Dirichlet, or Exponential, and rendered using an image construction library.
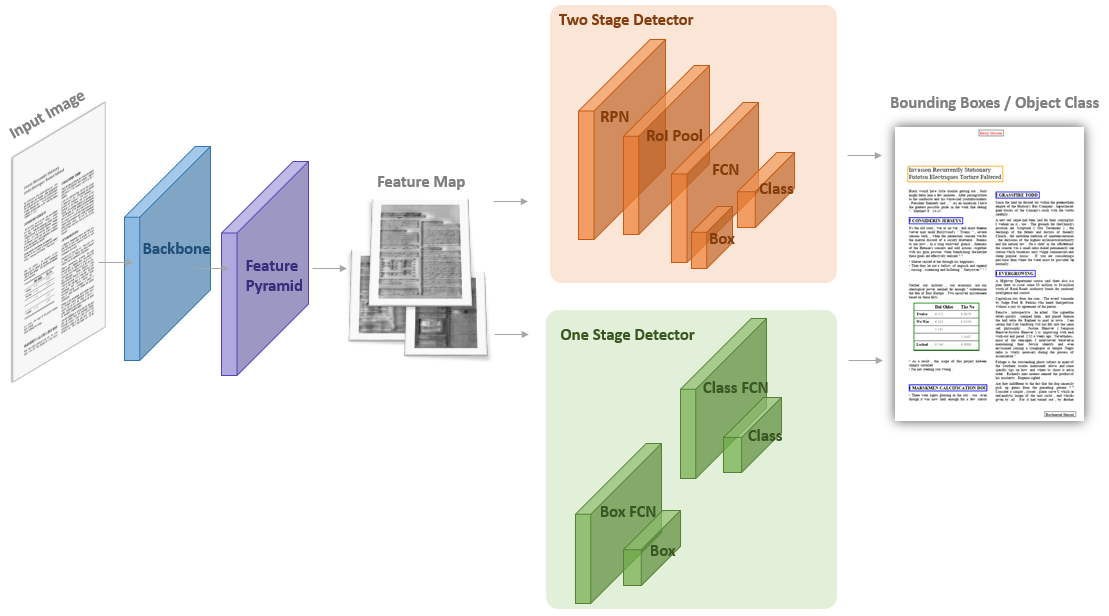
Figure 3: Layout Recognition Model Architecture with feature extraction and object detector networks.
Layout Recognition and Evaluation
The layout recognition is treated as an object detection task within rasterized documents, leveraging ConvNet-based architectures for semantic-rich feature extraction (Figure 3). The paper evaluates the recognition efficacy on three public datasets: PubLayNet, DocBank, and PubTabNet. Models trained on synthetic documents demonstrate performance comparable to those trained on real-world annotations with less than 4% performance difference.
(Table 1)
Table 1: Prediction results on DocBank dataset showing precision, recall, and F1 scores for both real and synthetic document training.
Practical Implications and Future Developments
The described approach of using synthetic document generation highlights the possibility of substantially reducing the dependency on annotated real-world documents for training deep learning models, significantly lowering associated costs and increasing accessibility to diverse data sources. It opens avenues for modeling documents across various languages and domains, emphasizing the generative model's independence from content language.
Further development could involve learning the network topology for automatic dependency capture, enhancing model robustness against document defects, and incorporating a more elaborate set of layout categories. The implications for the field of document analysis are significant, suggesting pathways for developing robust models in the absence of extensive labeled data.
In conclusion, this synthetic document generator exemplifies the practical and theoretical advancements made in layout recognition tasks without the overarching dependency on traditional datasets. Despite some marginal performance loss, the model's independence from annotated real-world documents for training represents a significant advancement in AI's document understanding capabilities.
Figure 2: Overview of our approach. A document generator encoded as a Bayesian Network is used to construct a large number of synthetic documents. An object detection model is trained purely on these synthetic documents and inference is performed on real documents to identify layout elements such as sections, tables, figures etc.
Through examining various synthetic document samples (Figure 1), the evidence suggests that a Bayesian Network can effectively generate documents with varied and realistic layouts, simulating both clean (Figure 1) and noise-afflicted documents (Figure 2). The synthetic dataset complements real documents for training, as indicated in Table 1. Furthermore, the approach demonstrates the capability for data augmentation in Table 5. This method proposes enhanced models, in architecture and generation approach compared to previous data augmentation methods.
Finally, by using heatmaps derived from gradient-based localization [selvaraju2017grad], the sensitivity of the model to various visual cues is identified, providing an interpretable framework that links layouts to detected semantic roles.
Figure 2: Example synthetic documents illustrating diversity in styles and structures.
Conclusion
By utilizing a Bayesian Network for generating synthetic documents, the proposed approach leverages hierarchical formulations and stochastic templates, proving equally effective as models trained on real annotated data. Such a strategy is promising both for annotation-free model training and potentially impactful in advancing multimodal document understanding. Future work can explore learning Bayesian Network structures, expansion to capture more granular features in document synthesis and layout categorization.
It is crucial to recognize the implications this holds for research in document layout recognition and analysis, as it enables scaling solutions across diverse languages and domains without limiting datasets or significant manual annotation efforts.