- The paper introduces a novel on-device STR system using selective rotation and CBAM to achieve 88.4% word accuracy at 2.44 ms per word.
- It employs a CNN-LSTM architecture with an orientation classifier to efficiently handle multi-oriented text across diverse languages.
- Experimental results demonstrate competitive performance and efficiency on standard datasets, making it ideal for deployment on constrained devices.
STRIDE: Scene Text Recognition In-Device
The paper "STRIDE: Scene Text Recognition In-Device" presents a novel, efficient, and compact scene text recognition (STR) system designed for on-device deployment. It tackles the challenges of real-time text recognition using constrained computational resources while maintaining competitive accuracy levels compared to existing heavy models.
Network Architecture
The STRIDE model employs a CNN-LSTM architecture optimized for recognizing both horizontal and vertical text. The model includes several key components:
- Selective Rotation: This module manages text transformations by applying selective rotation and perspective correction only to heavily skewed word images, thus minimizing processing overhead for slightly rotated text.
- Feature Extraction: The network features a compact CNN structure with Convolutional Block Attention Modules (CBAM) integrated to enhance feature extraction without compromising on latency and size. CBAM provides both spatial and channel attention which improves character separation in feature maps.

Figure 1: STRIDE Network Pipeline: The word boxes detected from the text localization network are passed to the feature extractor, after applying selective rotation. The orientation of each word is classified separately and passed to the sequence model with the temporal word features extracted.
- Orientation Classifier: This component predicts the orientation of text (horizontal or vertical) at the word level, using global average pooling followed by a fully connected layer. The orientation information is fused with character sequence features to facilitate simultaneous recognition of multi-oriented text.
- Sequence Modeling and Prediction: A bi-directional LSTM network, optimized with a recurrent projection layer, is employed to capture character context. The predictions are decoded using Connectionist Temporal Classification (CTC) loss for efficient sequence-to-label mapping.
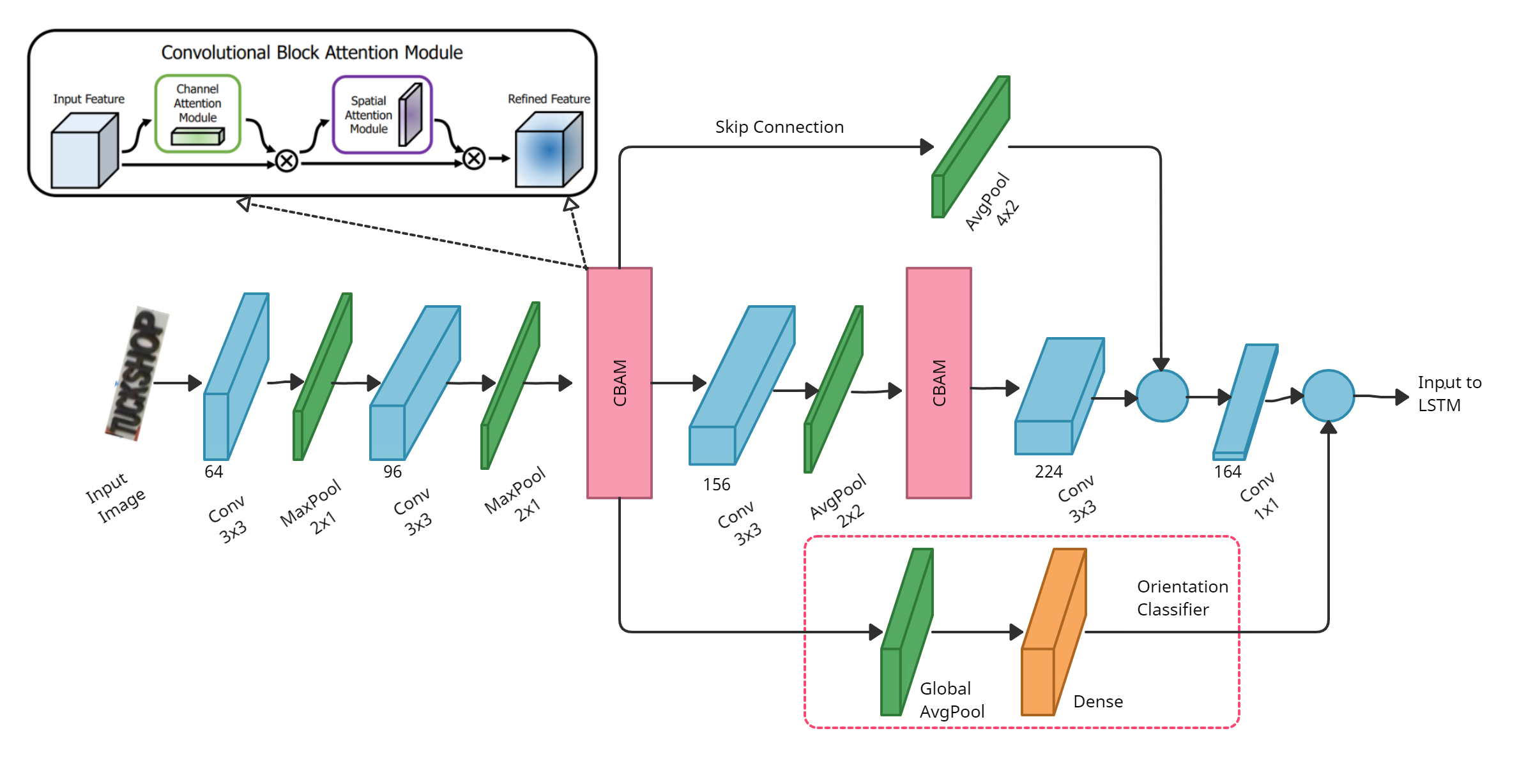
Figure 2: Feature Extractor and Orientation Classifier Module. CBAM is used to get channel and character region attention information. The detected orientation is concatenated to the extracted features and fed to the LSTM.
Experimental Results
The STRIDE system demonstrates a parameter size of just 0.88M, enabling deployment on devices with stringent computational constraints. Its accuracy and speed surpass multiple open-source OCR engines and commercial solutions:
- Achieves 88.4% word accuracy on the ICDAR-13 dataset with an inference speed of 2.44 ms per word on an Exynos 990 chipset device.
- The model supports diverse languages and scripts, including Latin, Korean, Japanese, and Chinese, by using tailored neural network models for each script.
Empirical evaluations on datasets like IIIT5k, SVT, IC13, and IC15 validate its competitive edge, especially in handling multi-oriented text due to its orientation classifier.
Comparative Analysis
A detailed ablation study of attention mechanisms revealed that the use of CBAM significantly enhances feature extraction capabilities with minimal impact on latency, compared to Global Squeeze-Excite (GSE) Blocks:
Future Work
Future enhancements could include adaptations for scripts such as Arabic, which presents additional challenges due to its right-to-left orientation and calligraphy-style fonts. Improvements in handling irregular text through efficient pre-processing modules or computationally feasible 2-D attention mechanisms are potential areas for exploration.
Conclusion
STRIDE offers a robust solution to scene text recognition under the constraints of on-device processing. By integrating convolution attention modules and an orientation classifier, it achieves competitive accuracy and efficiency. Its architecture can foster further applications in NLP and computer vision, enabling secure and private text recognition capabilities on personal devices.
