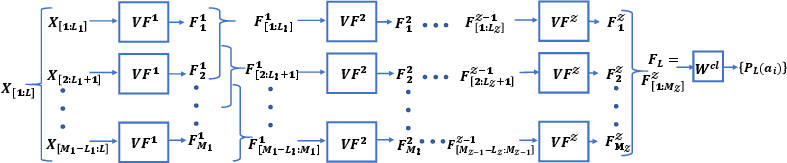
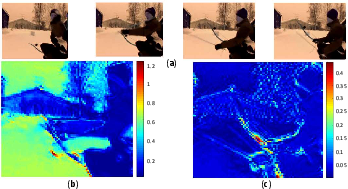
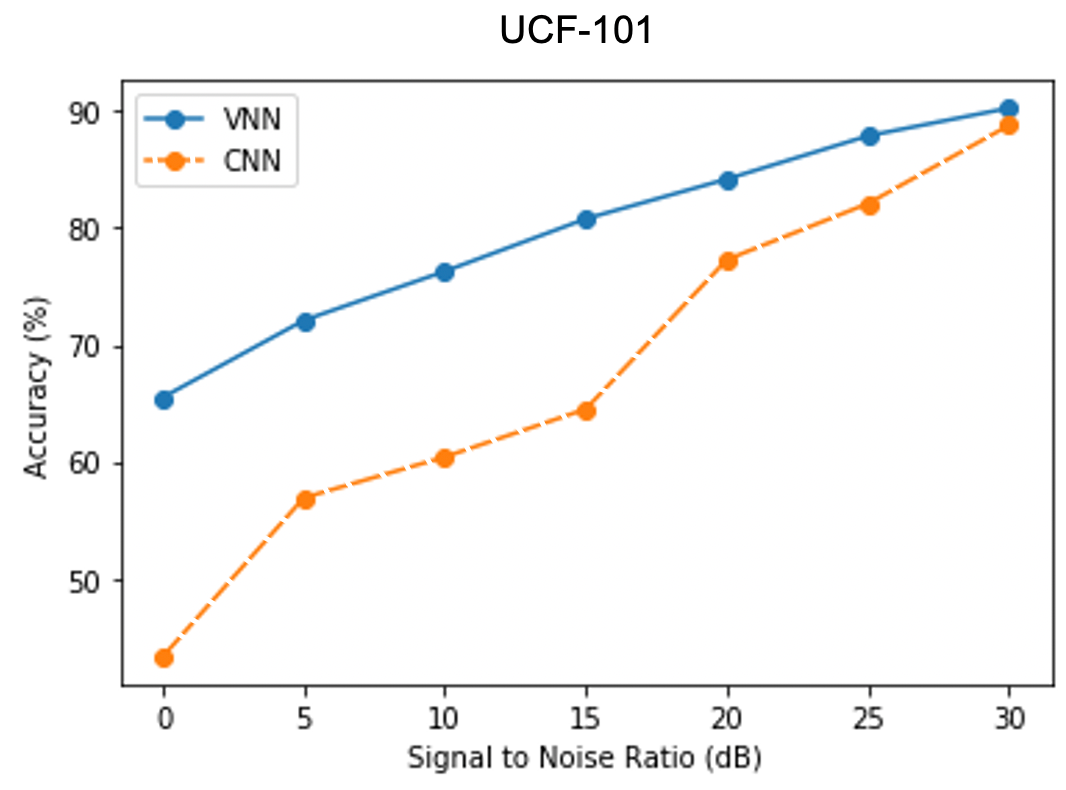
Volterra Neural Networks (VNNs)
Abstract: The importance of inference in Machine Learning (ML) has led to an explosive number of different proposals in ML, and particularly in Deep Learning. In an attempt to reduce the complexity of Convolutional Neural Networks, we propose a Volterra filter-inspired Network architecture. This architecture introduces controlled non-linearities in the form of interactions between the delayed input samples of data. We propose a cascaded implementation of Volterra Filtering so as to significantly reduce the number of parameters required to carry out the same classification task as that of a conventional Neural Network. We demonstrate an efficient parallel implementation of this Volterra Neural Network (VNN), along with its remarkable performance while retaining a relatively simpler and potentially more tractable structure. Furthermore, we show a rather sophisticated adaptation of this network to nonlinearly fuse the RGB (spatial) information and the Optical Flow (temporal) information of a video sequence for action recognition. The proposed approach is evaluated on UCF-101 and HMDB-51 datasets for action recognition, and is shown to outperform state of the art CNN approaches.
- Tensorflow: A system for large-scale machine learning. In 12th {normal-{\{{USENIX}normal-}\}} Symposium on Operating Systems Design and Implementation ({normal-{\{{OSDI}normal-}\}} 16), pages 265–283, 2016.
- Sequential deep learning for human action recognition. In International workshop on human behavior understanding, pages 29–39. Springer, 2011.
- Benign overfitting in linear regression. arXiv preprint arXiv:1906.11300, 2019.
- Quo vadis, action recognition? a new model and the kinetics dataset. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017.
- Histograms of oriented gradients for human detection. 2005.
- Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- Temporal 3d convnets: New architecture and transfer learning for video classification. arXiv preprint arXiv:1711.08200, 2017a.
- Deep temporal linear encoding networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2329–2338, 2017b.
- Learning hierarchical features for scene labeling. IEEE transactions on pattern analysis and machine intelligence, 35(8):1915–1929, 2012.
- Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1933–1941, 2016.
- Slowfast networks for video recognition. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6202–6211, 2019.
- William J Firey. Remainder formulae in taylor’s theorem. The American Mathematical Monthly, 67(9):903–905, 1960.
- Compact bilinear pooling. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 317–326, 2016.
- Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014.
- Improved training of wasserstein gans. In Advances in neural information processing systems, pages 5767–5777, 2017.
- Learning with side information through modality hallucination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 826–834, 2016.
- Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1125–1134, 2017.
- 3d convolutional neural networks for human action recognition. IEEE transactions on pattern analysis and machine intelligence, 35(1):221–231, 2012.
- Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 1725–1732, 2014.
- The kinetics human action video dataset. arXiv preprint arXiv:1705.06950, 2017.
- Yu Kong and Yun Fu. Human action recognition and prediction: A survey. arXiv preprint arXiv:1806.11230, 2018.
- On stabilizing generative adversarial networks (stgans).
- Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012.
- Hmdb: a large video database for human motion recognition. In 2011 International Conference on Computer Vision, pages 2556–2563. IEEE, 2011.
- Trainable convolution filters and their application to face recognition. IEEE transactions on pattern analysis and machine intelligence, 34(7):1423–1436, 2011.
- Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- Bilinear cnns for fine-grained visual recognition. arXiv preprint arXiv:1504.07889, 2015.
- Recognizing realistic actions from videos in the wild. Citeseer, 2009.
- Sparse generative adversarial network. In Proceedings of the IEEE International Conference on Computer Vision Workshops, pages 0–0, 2019.
- Modeling temporal structure of decomposable motion segments for activity classification. In European conference on computer vision, pages 392–405. Springer, 2010.
- Multilayer neural network structure as volterra filter. In Proceedings of IEEE International Symposium on Circuits and Systems-ISCAS’94, volume 6, pages 253–256. IEEE, 1994.
- Decision level fusion: An event driven approach. In 2018 26th European Signal Processing Conference (EUSIPCO), pages 2598–2602. IEEE, 2018a.
- Cross-modality distillation: A case for conditional generative adversarial networks. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2926–2930. IEEE, 2018b.
- Event driven fusion. arXiv preprint arXiv:1904.11520, 2019.
- Walter Rudin et al. Principles of mathematical analysis, volume 3. McGraw-hill New York, 1964.
- Martin Schetzen. The volterra and wiener theories of nonlinear systems. 1980.
- Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv preprint arXiv:1312.6229, 2013.
- Two-stream convolutional networks for action recognition in videos. In Advances in neural information processing systems, pages 568–576, 2014.
- Video google: A text retrieval approach to object matching in videos. In null, page 1470. IEEE, 2003.
- Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402, 2012.
- Marshall H Stone. The generalized weierstrass approximation theorem. Mathematics Magazine, 21(5):237–254, 1948.
- Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE international conference on computer vision, pages 4489–4497, 2015.
- A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 6450–6459, 2018.
- Vito Volterra. Theory of functionals and of integral and integro-differential equations. Courier Corporation, 2005.
- Evaluation of local spatio-temporal features for action recognition. 2009.
- Human activity modeling as brownian motion on shape manifold. In International Conference on Scale Space and Variational Methods in Computer Vision, pages 628–639. Springer, 2011.
- A duality based approach for realtime tv-l 1 optical flow. In Joint pattern recognition symposium, pages 214–223. Springer, 2007.
- Non-linear convolution filters for cnn-based learning. In Proceedings of the IEEE International Conference on Computer Vision, pages 4761–4769, 2017.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.