- The paper introduces control tasks that distinguish between a probe’s capability to encode true linguistic structure and its capacity for memorization.
- The analysis shows that linear probes on ELMo representations achieve higher selectivity compared to MLPs while maintaining competitive task accuracy.
- The study demonstrates that reducing hidden dimensions and applying strong L2 regularization can improve probe selectivity, contrary to the limited impact of dropout.
Designing and Interpreting Probes with Control Tasks
Introduction
The paper "Designing and Interpreting Probes with Control Tasks" by John Hewitt and Percy Liang tackles a critical question in linguistic probing of representation models: distinguishing between a model's encoding of linguistic structure and a probe's capability to learn a task. The authors propose control tasks to complement traditional linguistic tasks, emphasizing that a probe's selectivity—its ability to achieve high accuracy on linguistic tasks and low accuracy on control tasks—is essential for meaningful interpretation of results. This paper analyzes the selectivity of probes applied to ELMo representations and explores various regularization techniques to improve probe selectivity.
Probes and Control Tasks
Probes are supervised models employed to decipher linguistic properties from neural network representations, like ELMo, and have demonstrated high accuracy across numerous linguistic tasks. However, the interpretation of this accuracy is ambiguous—does it reflect the model's encoding capabilities, or merely the probe's ability to learn?
To address this ambiguity, the paper introduces control tasks, which associate word types with random outputs that can only be learned through memorization. Effective probes should exhibit selectivity by maintaining high accuracy on linguistic tasks but showing low accuracy on control tasks. For instance, while probing for part-of-speech (PoS) tagging, a selective probe should accurately identify PoS tags but perform poorly on a control task where word types are randomly assigned labels.
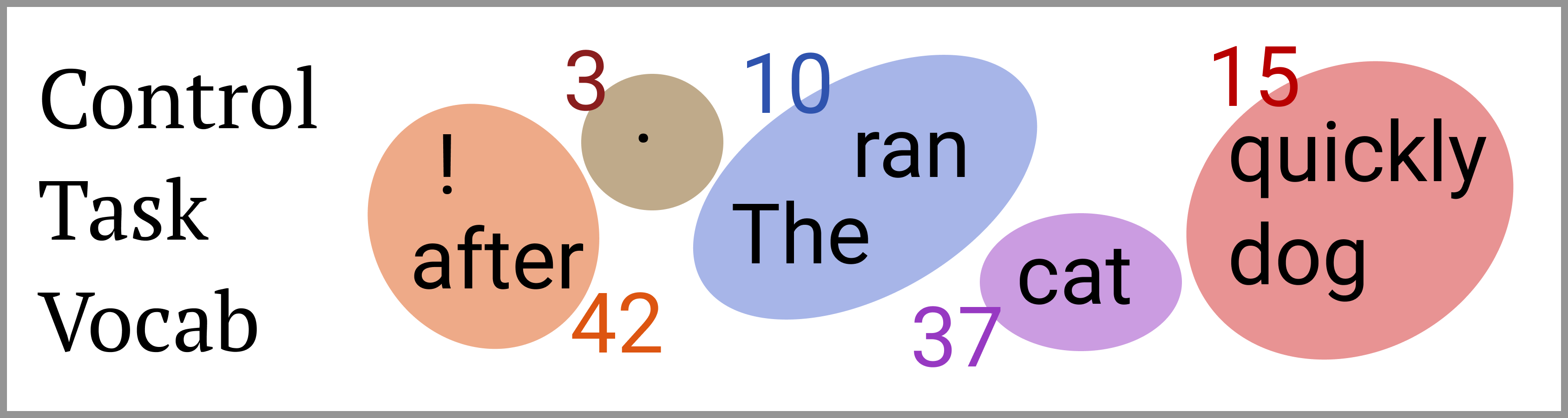
Figure 1: Illustration of control tasks with random behavior for different word types, indicating their association regardless of context.
Probe Evaluation and Selectivity
The paper evaluates the selectivity of various probes on ELMo representations, focusing on English PoS tagging and dependency edge prediction tasks. Using control tasks, the authors demonstrate that widely-used probes such as MLPs often lack selectivity due to their capacity to memorize mappings. Crucially, they observe that linear probes exhibit higher selectivity compared to MLPs, often achieving similar linguistic task accuracy with greater interpretability.
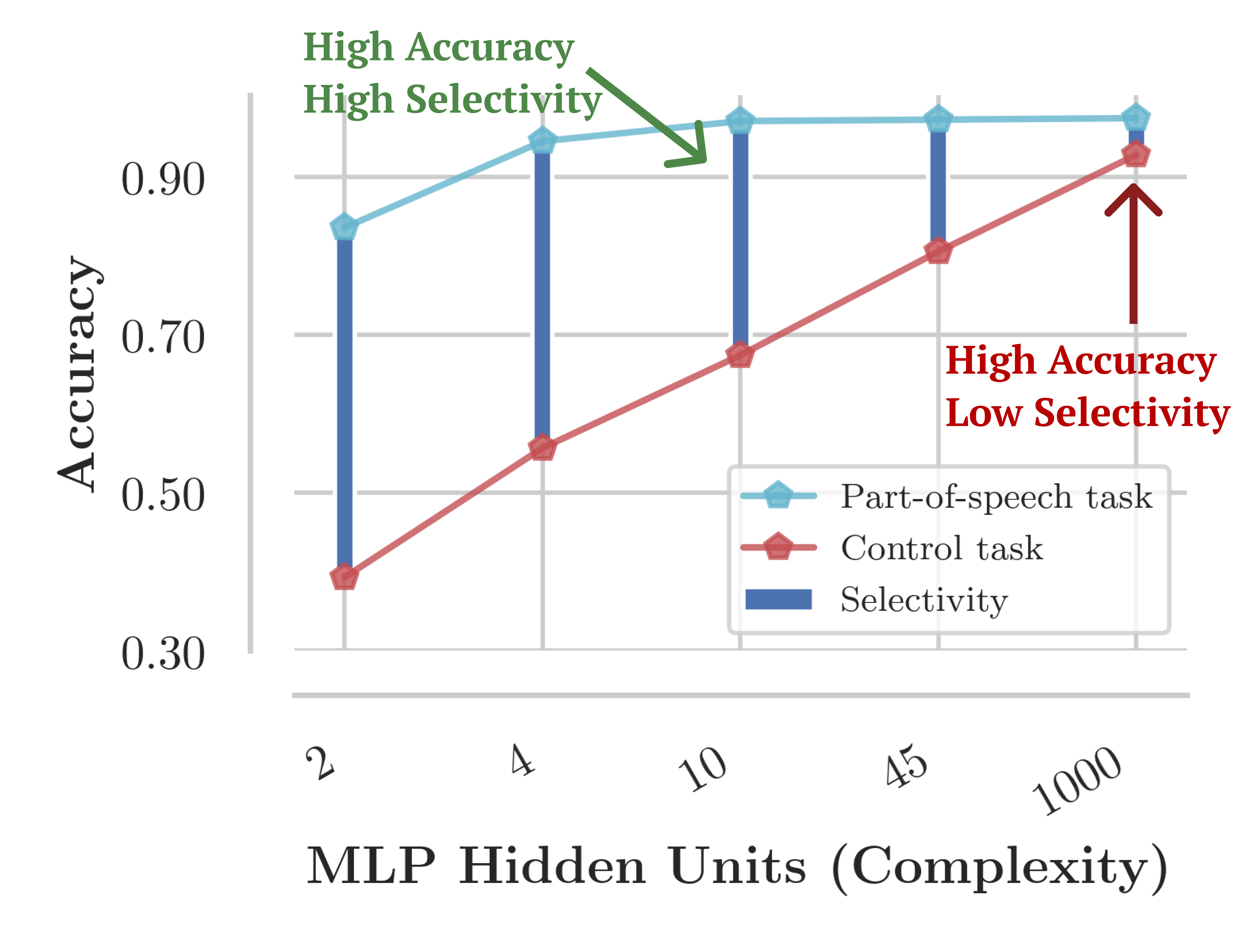
Figure 2: Selectivity variations across probes with different architectures and hyperparameters, showing that even high-accuracy probes may vary widely in selectivity.
Complexity Control Techniques
The paper investigates several complexity control techniques to enhance probe selectivity, including altering the rank of weight matrices, hidden dimensionality, dropout, training set size, and L2 regularization. The findings suggest that techniques like reducing hidden state sizes and substantial weight decay can effectively improve selectivity without heavily compromising linguistic task accuracy. Conversely, dropout, contrary to its widespread use, is deemed ineffective for enhancing probe selectivity.
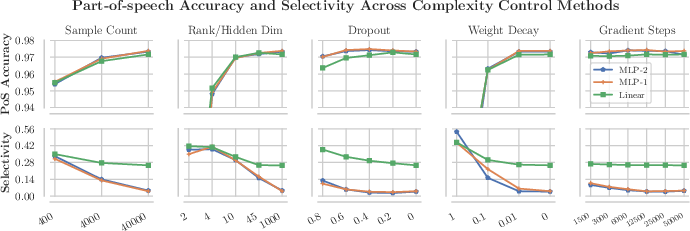
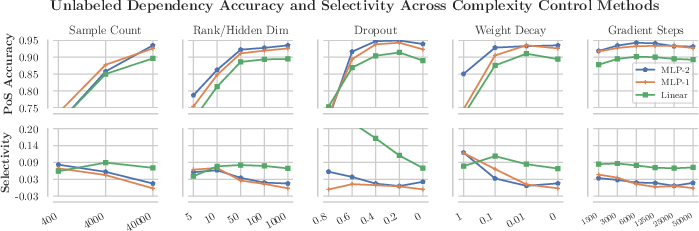
Figure 3: Impact of different complexity control methods on selectivity and linguistic task accuracy, highlighting the limited utility of dropout compared to other methods.
Layer-Wise Comparison and Interpretations
Selectivity sheds light on the comparative performance of ELMo layers often considered in isolation based solely on accuracy metrics. While previous studies noted ELMo's first layer as superior for PoS tasks, this paper's selectivity analysis suggests the second layer may better encapsulate linguistic structure, independently of word identity recognition. This raises questions about traditional metrics' adequacy in capturing the nuanced capacities of representation models.
Conclusion
The research proposes a novel framework for evaluating probes using control tasks, emphasizing the importance of probe selectivity in assessing the linguistic properties encoded in representations. The findings challenge the conventional reliance on accuracy alone, advocating for selectivity as a crucial metric in linguistic probing studies. Moreover, the paper demonstrates the need for careful design in probe architecture and complexity control to extract genuine linguistic insights from neural representations, potentially guiding future developments in understanding and evaluating advanced LLMs.
