Less is More: Recursive Reasoning with Tiny Networks
An overview of how the Tiny Recursive Model (TRM) achieves state-of-the-art performance on hard reasoning tasks like Sudoku and ARC-AGI by using a simplified, single-network architecture that outperforms larger, complex predecessors.Script
Can a tiny model with just 7 million parameters accurately solve reasoning puzzles that baffle much larger systems? This paper challenges the assumption that bigger is always better, demonstrating that a simplified recursive approach can achieve state-of-the-art results on hard discrete tasks.
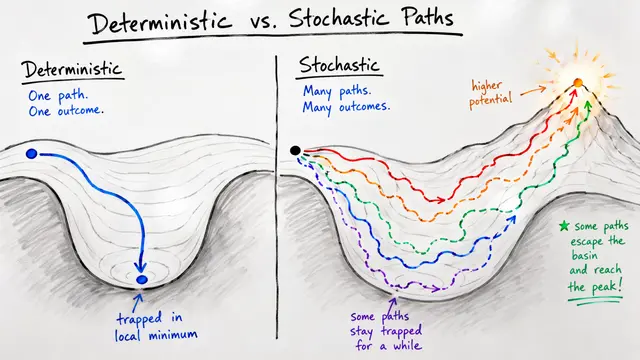
To understand why this work matters, we first need to look at the problem of discrete reasoning. Even powerful language models struggle with puzzles like Sudoku or ARC-AGI, where a single mistake invalidates the entire solution. While earlier attempts like the Hierarchical Reasoning Model showed promise, they relied on complex, multi-network architectures that were difficult to interpret and train.
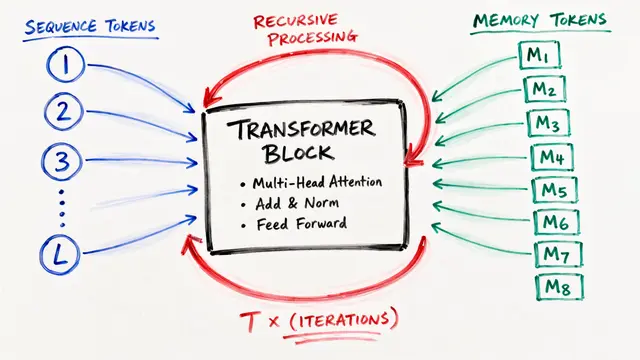
The researchers propose a radical simplification of the previous state-of-the-art. While the prior Hierarchical Reasoning Model used two separate networks and complex gradient approximations to save memory, the new Tiny Recursive Model consolidates everything into one. It uses a single network to handle both reasoning and answer generation, utilizing full backpropagation to learn more effectively.
Inside this efficient architecture, the model maintains two simultaneous states: the current answer and a latent reasoning state. Over multiple recursive cycles, a tiny 2-layer network iteratively updates these states, refining the solution step-by-step. This deep recursion allows the model to perform complex reasoning without massive parameter counts, using techniques like Exponential Moving Average to maintain stability.
The results of this simplification are striking. On the Sudoku-Extreme benchmark, the new model jumps from the baseline's 55 percent accuracy to over 87 percent. It achieves similar gains on navigation tasks like Maze-Hard, all while using roughly one-quarter of the parameters required by the previous best approach.
This work clearly demonstrates that regarding reasoning models, simpler architectures with better training dynamics can vastly outperform complex ones. For more insights on efficient AI architectures, visit EmergentMind.com.