Program-as-Weights: A Programming Paradigm for Fuzzy Functions
Abstract: Many everyday programming tasks resist clean rule-based implementation, such as alerting on important log lines, repairing malformed JSON, or ranking search results by intent, and are increasingly outsourced to LLM APIs at the cost of locality, reproducibility, and price. We propose fuzzy-function programming: compiling such a function from a natural-language specification into a compact, locally-executable neural artifact. We instantiate this paradigm with Program-as-Weights (PAW), in which a 4B compiler trained on FuzzyBench, a 10M-example dataset we release, emits parameter-efficient adapters for a frozen, lightweight interpreter. A 0.6B Qwen3 interpreter executing PAW programs matches the performance of direct prompting of Qwen3-32B, while using roughly one fiftieth of the inference memory and running at 30 tokens/s on a MacBook M3. PAW reframes the foundation model from a per-input problem solver into a tool builder: invoked once per function definition, it produces a small reusable artifact whose subsequent calls per function application are cheap and offline.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Program-as-Weights: A Programming Paradigm for Fuzzy Functions”
Overview: What is this paper about?
Some everyday computer tasks are hard to write as strict rules. Think of:
- Skimming tons of messages and only alerting you to the important ones
- Fixing slightly broken JSON so it loads correctly
- Re-ranking search results by what a person probably meant
These are “fuzzy” tasks: people understand them, but they’re messy to describe in exact code. Today, many teams send each input to a large online AI model to handle this fuzziness, which can be slow, expensive, and not private.
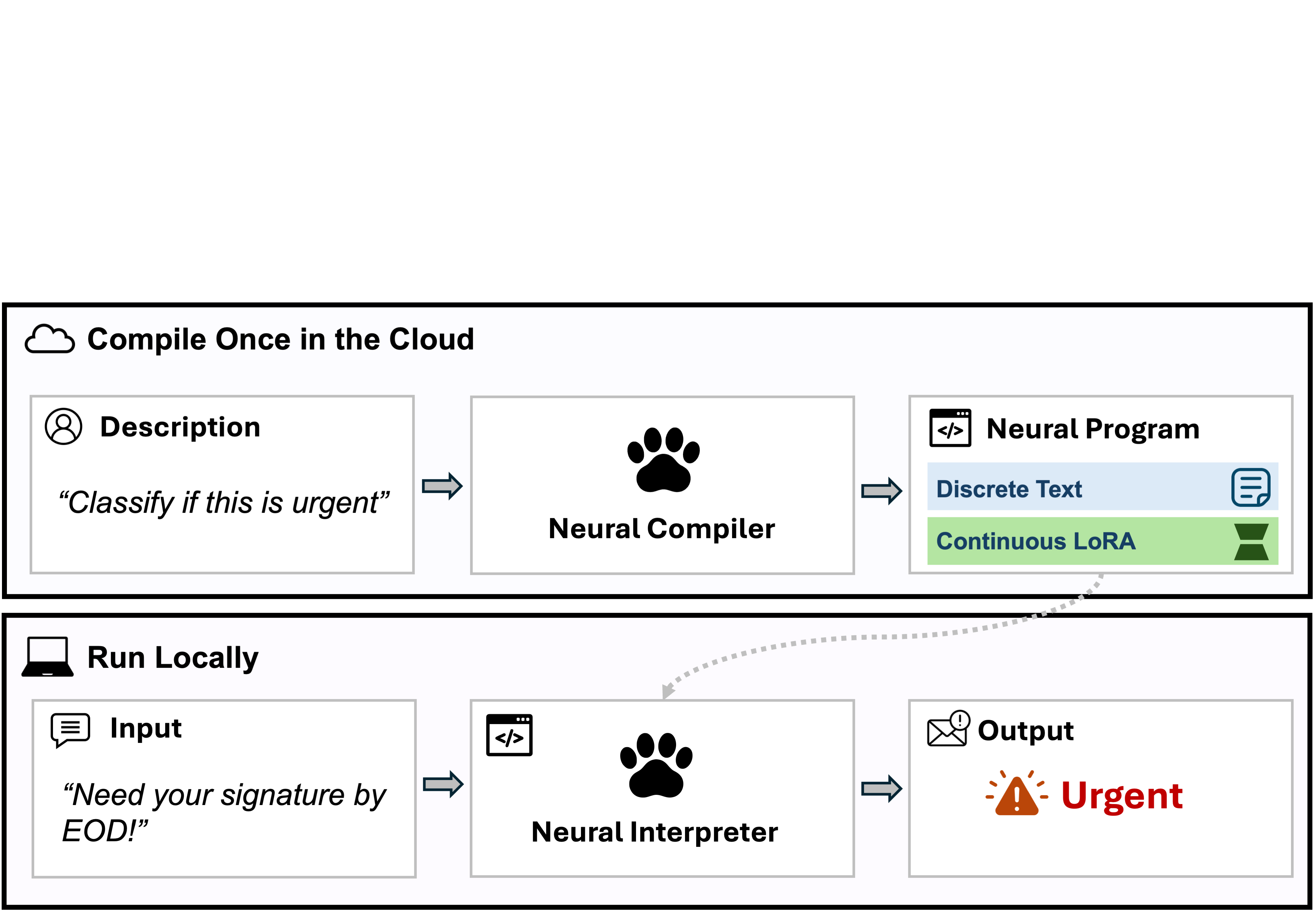
This paper introduces a different way: Program-as-Weights (PAW). Instead of calling a big AI model for every input, you describe your fuzzy function once in plain language, a “compiler” turns that description into a small file, and a tiny “interpreter” model on your own device runs that file over and over—fast, cheap, and offline.
Objectives: What were the researchers trying to do?
The authors wanted to:
- Turn natural-language instructions (like “alert only important log lines”) into a small, reusable “neural program” you can run locally.
- Show that a small local model plus a custom add‑on can perform as well as much bigger models that run in the cloud.
- Build a huge dataset (called FuzzyBench) to train and test this idea on many kinds of fuzzy tasks.
- Make this approach robust to messy, typo-filled instructions, and extend it beyond text to images.
How it works: Methods explained simply
Think of PAW like installing a custom app plugin.
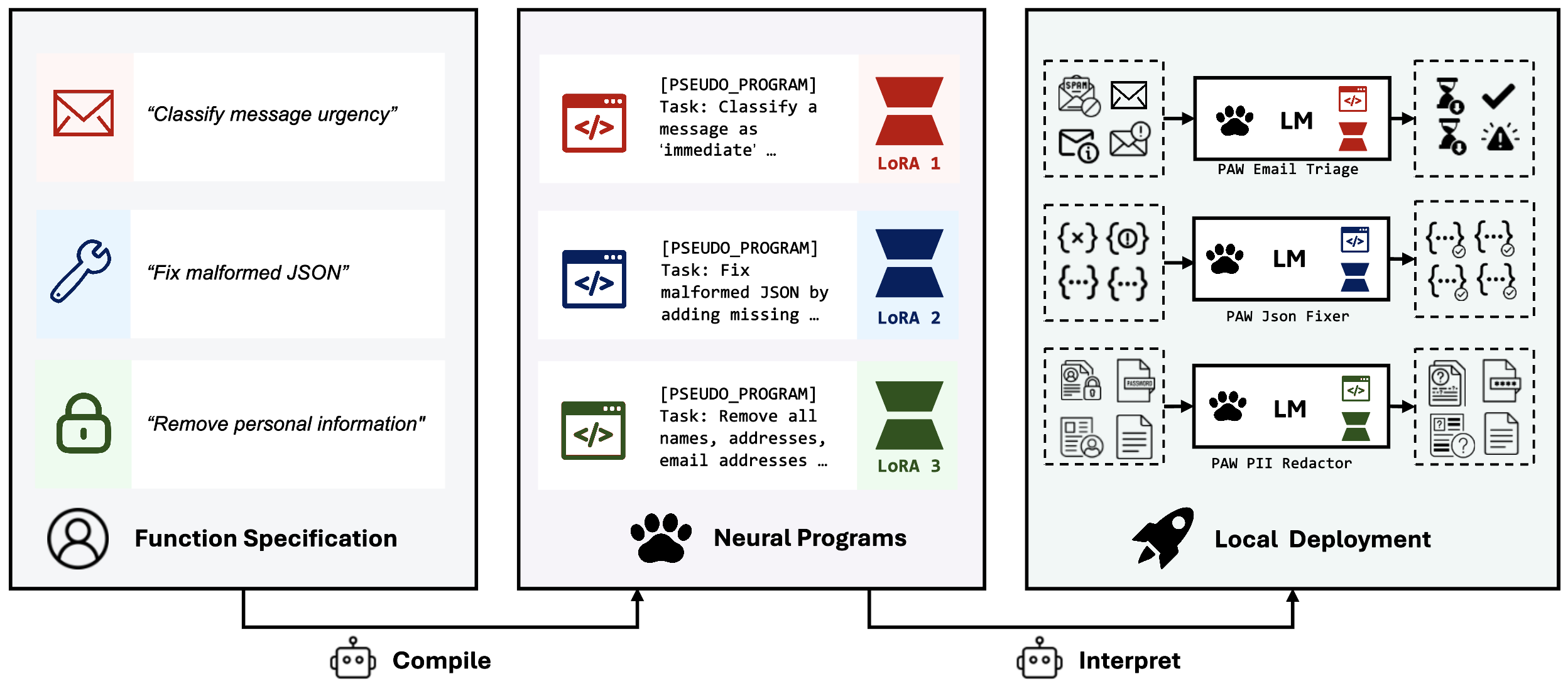
- The “compiler” is like a plugin builder. You give it:
- A plain‑language description of what you want (the “spec”)
- The compiler writes a cleaned-up “pseudo-program” (a clear restatement plus a few examples), and then produces a tiny add‑on that tweaks a small model to do your task.
- The “interpreter” is a small AI model that sits on your device. It loads the add‑on and runs your inputs quickly without needing the internet.
Two key pieces make each PAW program:
- A short text “pseudo-program” (a tidy restatement plus examples)
- A tiny set of weights that nudge the small model to behave just right for your task
In everyday terms:
- The pseudo-program is like a neat instruction card that clarifies your fuzzy idea.
- The tiny weights are like adjusting a bunch of small knobs inside the model so it responds exactly the way you want.
Some names you might see:
- “LoRA” (Low-Rank Adaptation): A lightweight way to adjust a model with a small number of extra parameters—think “mini upgrades” instead of replacing the whole engine.
- “PEFT” (Parameter-Efficient Fine-Tuning): Fancy term for making small, cheap adjustments to a big model, rather than retraining it all.
- “Compiler vs. Interpreter”: The compiler builds the plugin once; the interpreter runs it many times. Like writing and saving an app, then running it whenever you want.
Training and data:
- The team created FuzzyBench, a 10‑million-example dataset of fuzzy tasks with instructions, inputs, and target outputs.
- They used a medium-size model (“compiler,” about 4B parameters) to generate the small add‑ons.
- They used a small local model (“interpreter,” about 0.6B parameters) to run tasks.
- They tried two styles of add‑ons; “LoRA” worked best.
Main findings: What did they discover and why it matters
Here are the big results in simple terms:
- Small can match big: A tiny 0.6B model running PAW programs matched or beat prompting a much larger 32B model on their benchmark (about 74% vs. 69% accuracy), while using roughly 1/50th the memory.
- Fast and local: On a MacBook M3, a quantized version ran around 30 tokens per second. The shared base model can be ~430 MB, and each per-task add‑on is ~23 MB. After you compile once, you can run offline.
- Robust to messy instructions: If your written task description has typos or awkward phrasing, PAW still works well. That’s because the pseudo-program step “cleans” your instructions before they reach the small model.
- Works with images too: By swapping in a vision-language compiler (but keeping the same tiny interpreter), PAW handled image-conditioned tasks (like understanding diagrams) surprisingly well.
- General and reusable: The interpreter stays frozen (unchanged). You can compile many different fuzzy functions into different small add‑ons and hot‑swap them—like loading different plugins for different jobs.
Why this is important:
- Cheaper and private: You don’t need to send every input to a big cloud model.
- Reproducible: Your compiled program is a versioned file you can save, share, and run later with the same behavior.
- Developer-friendly: It looks and feels like a normal function you call in your code.
Implications: What could this change in the real world?
If tools like PAW become common:
- Apps could handle fuzzy tasks locally—faster, cheaper, and with better privacy.
- Teams could ship “neural programs” as small, versioned files, just like software libraries.
- Big models might be used mainly once—at “compile time”—to create tools, while small models do the daily work on devices.
- More people could build smart features without paying for constant API calls or managing giant models.
In short, this paper shows a practical path to “compile once, run many times” for fuzzy tasks. It turns big models into tool builders and small models into reliable, local tool runners.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes concrete gaps and unresolved questions that future work could address to strengthen the Program-as-Weights (PAW) paradigm and its evaluation.
- Real‑world generalization beyond synthetic data
- How well do PAW programs compiled from human‑authored specifications perform on real production tasks (e.g., log triage, JSON repair, search reranking) compared with results on the synthetic FuzzyBench?
- What is the performance under domain, style, and vocabulary shift between synthetic specs/IO pairs and real inputs?
- Reliability of ground truth and evaluation
- The “verified” test labels rely on agreement between two LLMs from the same provider; human‑validated gold labels are missing. How do results change under human adjudication, especially for inherently fuzzy tasks with multiple valid outputs?
- Exact‑match accuracy may undercount valid outputs on fuzzy tasks. How do alternative metrics (edit distance, semantic equivalence, partial credit, task‑specific validators) affect conclusions?
- Coverage and representativeness of FuzzyBench
- To what extent do the 800+ categories reflect real developer workloads (frequency, skew, long‑tail edge cases)? A mapping to real application logs or issue trackers is not provided.
- How well does performance hold on genuinely out‑of‑distribution specs and unseen task families (not just held‑out specs within the same families)?
- Compile‑time cost and amortization
- The paper emphasizes low inference cost but does not quantify compile‑time latency, GPU/CPU hours, and energy per function. When does compilation amortize versus prompting for different call volumes and function complexities?
- Robustness beyond spec noise
- Robustness is only tested by corrupting the specification. How robust are compiled programs to input drift (typos, schema changes, adversarial inputs), long contexts, or malformed inputs the functions are supposed to repair (e.g., JSON fixers)?
- Long‑form and structured outputs
- PAW LoRA underperforms on long structured generation (e.g., Im2LaTeX). What architectural or decoding constraints (constrained decoding, grammar guides, structured decoders) are needed to guarantee well‑formed outputs (e.g., valid JSON) at scale?
- Multimodal limits with a text interpreter
- Image‑conditioned PAW relies on the VL compiler to encode visual context into a LoRA for a text‑only interpreter. What are the limits for complex vision tasks (dense reasoning, spatial grounding), and when does this bottleneck the system?
- Composability and control flow
- How to compose multiple PAW programs (e.g., pipelines, conditionals, ensembling) without destructive interference between LoRAs? Are there principled mechanisms for LoRA composition, arbitration, or hierarchical control flow?
- Debuggability and observability
- There is no method to attribute errors to the discrete pseudo‑program vs. the continuous LoRA. What tooling supports inspection, unit tests over compiled programs, counterfactual edits, or minimal patches without full recompilation?
- Determinism, versioning, and reproducibility
- The pseudo compiler is prompt‑programmed and not trained; its nondeterminism, seed sensitivity, and drift across upstream model updates are not characterized. How can compiles be made deterministic and reproducible across versions?
- Security model for distributed PAW programs
- What prevents a malicious or poisoned LoRA/pseudo‑program from inducing unsafe behaviors in the interpreter? There is no discussion of program signing, provenance, sandboxing, or runtime policy checks.
- Prompt/pseudo‑program injection risks
- Since specs feed a prompted pseudo compiler, how resilient is the pipeline to prompt injection or spec payloads that cause the pseudo‑program to subvert safety or leak information?
- Storage footprint at scale
- At ~23 MB per program (quantized), libraries with hundreds/thousands of functions become large (GBs–TBs). Are there mechanisms for basis sharing, delta/diff distribution, or cross‑program deduplication to reduce storage?
- Lifecycle management and updates
- How are programs updated when specs evolve, requirements change, or bugs are found? Is there support for diffing compiled programs, backward compatibility guarantees, or automated regression testing across versions?
- Portability across interpreters
- Compiled LoRAs are interpreter‑specific. Can PAW target an intermediate representation that retargets programs to new interpreters (and tokenizer variants) without full recompilation? What is the loss from cross‑model transfer?
- Scaling laws and capacity limits
- There is no analysis of how accuracy scales with compiler size, interpreter size, LoRA rank, and number of shared bases. What are capacity limits for increasingly complex functions, and where does the discrete vs. continuous split become the bottleneck?
- Why simple LoRA mapping works best
- The mean‑pool + shared‑basis LoRA mapper outperforms more expressive variants, but no explanation is given. What properties of the compiler’s hidden states or the interpreter’s layer structure make this aggregation optimal?
- Uncertainty estimation and abstention
- PAW does not report calibration, confidence scores, or abstention behavior. How can compiled programs detect out‑of‑scope specs/inputs and fail safely?
- Multi‑turn/stateful and interactive tasks
- The current setup treats functions as single‑turn mappings. How can PAW support stateful logic (memory across calls), multi‑turn interactions, or tool‑using agents with persistent state?
- Multilingual breadth and transfer
- Aside from a game case study, multilingual coverage is not quantified. How does performance vary across languages and scripts, and can a single compiled program handle multilingual specs and inputs reliably?
- Tool‑use at scale and external dependencies
- The tool‑calling pipeline is small. How does PAW handle dozens/hundreds of tools, error recovery, tool latency, and authenticated/online dependencies while preserving “contained” execution guarantees?
- Quantization generality and edge deployment
- Quantization results are shown on a MacBook M3 for specific GGUF formats. How do results vary across hardware (mobile GPUs/NPUs/CPUs), longer contexts, and different quantization schemes, especially for latency‑critical tasks?
- Concurrency and serving under load
- Hot‑swapping LoRAs is assumed, but throughput, memory pressure, and latency under many concurrent programs/users are not measured. What are the scaling limits and scheduler designs for multi‑tenant interpreters?
- Safety and alignment of compiled functions
- There is no red‑teaming of compiled programs or discussion of guardrails when specs request harmful or deceptive behavior. How are safety policies enforced at compile and execution time?
- Data privacy and leakage
- If specs include sensitive examples, do compiled LoRAs memorize and leak private data? What is the privacy model for distributing per‑function adapters outside the origin environment?
- Real‑world deployment studies
- Beyond case studies, there is no end‑to‑end evaluation in production settings (e.g., replacing API calls in a live service) with measurements of cost savings, failure modes, and developer productivity impacts.
- Program length and context budget
- Pseudo‑programs can crowd the interpreter’s context on long tasks. What mechanisms (compression, gist tokens, retrieval) best reduce pseudo‑program footprint without harming accuracy?
- Constraint decoding and validation
- The interpreter uses standard autoregressive decoding; no integration with constrained decoding or validators is reported. Can integrating structure‑aware decoding reduce invalid outputs on parsing/formatting tasks?
- Environmental and compute footprint
- The cost of generating FuzzyBench‑10M and training the compilers is not reported. What are the energy/emissions implications, and how do they compare to continuous API usage for the same workload?
- Licensing and governance
- The legal status of distributing compiled adapters derived from synthetic data and the dataset’s licensing constraints are not discussed. What governance is needed for sharing, versioning, and publishing PAW programs?
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented now using PAW’s compiler–interpreter paradigm (Text-to-LoRA programs executed on a frozen 0.6B interpreter, with ≈23 MB per-function adapters and ≈430–507 MB quantized base; ≈30 tokens/s on a MacBook M3).
- Software/DevOps — log triage and alerting
- What: Compile fuzzy alerting rules to fire only on “important” log lines (e.g., error patterns, customer-impacting events) instead of brittle regexes.
- Sector: Software/Observability/SRE.
- Tools/workflows: CI compiles specs to LoRA adapters; agents run locally on servers/workstations; artifacts versioned in SCM or a PAW registry.
- Dependencies/assumptions: Access to the PAW compiler service; on-prem interpreter deployment; adequate examples/specs; robustness to log format drift (supported by pseudo-program denoising).
- Software/DevOps — automatic JSON repair and schema normalization
- What: Compile a function that repairs malformed JSON or normalizes fields with format drift.
- Sector: Software/Data Engineering.
- Tools/workflows: ETL pre-processors invoke local PAW functions; adapters shipped alongside data pipelines.
- Dependencies/assumptions: Sufficient examples of malformed inputs; interpreter context length fits examples.
- Enterprise IT — intent-based navigation and command palettes
- What: Local fuzzy classification for “jump-to” or “find” functionality on websites/apps.
- Sector: Software/Product.
- Tools/workflows: Front-end or service-side PAW call; per-feature adapters cached client-side.
- Dependencies/assumptions: Lightweight interpreter available on device or in service tier; UI integration.
- Search and e-commerce — semantic reranking
- What: Compile intent-aware rerankers over keyword indices to improve relevance without per-query API calls.
- Sector: Software/Information Retrieval/Retail.
- Tools/workflows: Search service loads adapters per vertical/category; A/B test swaps adapters cheaply.
- Dependencies/assumptions: Latency budgets compatible with small-model inference; domain examples for each vertical.
- Agent frameworks — tool selection and argument shaping
- What: Local tool-routing and argument extraction (paper case study: ≈93% on ToolCall-15) to reduce reliance on 30B+ models at inference.
- Sector: Software/Agents/Automation.
- Tools/workflows: Compose multiple PAW programs in a pipeline; cache compiled adapters.
- Dependencies/assumptions: Stable tool schemas; curated examples; safety policies for edge cases.
- Customer support and ops — triage of email, chat, and tickets
- What: Urgency, intent, or routing classification that runs offline and is reproducible.
- Sector: CX/Operations.
- Tools/workflows: Local adapters in helpdesk integrations; per-queue specialization via separate adapters.
- Dependencies/assumptions: Data privacy requires on-device/intranet interpreter; domain shift monitoring.
- Security operations — alert deduplication and enrichment
- What: Reduce false positives by classifying noisy SIEM/SOAR alerts; extract salient details.
- Sector: Security.
- Tools/workflows: On-prem interpreters to preserve data locality; versioned adapters for each detector.
- Dependencies/assumptions: Robustness to noise (supported by tested noise variants); strict access control to adapter artifacts.
- Compliance and privacy — on-device PII detection/redaction
- What: Local, auditable fuzzy redaction functions for documents and chat logs.
- Sector: Finance/Healthcare/Government.
- Tools/workflows: Distribute signed adapters through an internal registry; run in DLP gateways.
- Dependencies/assumptions: Policy-aligned specifications; audit trails via artifact checksums and versions.
- Healthcare ops — non-clinical triage and de-identification
- What: Appointment/administrative message triage; free-text de-identification before storage.
- Sector: Healthcare (operations, not clinical decision support).
- Tools/workflows: Edge deployment in clinics; offline inference; human-in-the-loop review.
- Dependencies/assumptions: Regulatory review; local-only processing; validated domain examples.
- Finance back office — KYC doc parsing and normalization
- What: Extract/standardize entities and resolve format drift in scanned or emailed forms (text channel).
- Sector: Finance.
- Tools/workflows: Batch adapters per region/regulation; integrate with RPA flows.
- Dependencies/assumptions: Clear specs per jurisdiction; data retention policies; robustness to noise.
- Education — rubric-specific grading aids and feedback tagging
- What: Compile per-course rubrics into re-usable classifiers that tag feedback/themes.
- Sector: Education.
- Tools/workflows: In-LMS plug-ins; per-assignment adapters; offline mode for exams.
- Dependencies/assumptions: Human oversight; limited to non-adversarial student data.
- Robotics/IoT — natural-language command parsing to structured actions
- What: Map free-form commands to structured intents for home/industrial devices locally.
- Sector: Robotics/IoT.
- Tools/workflows: Ship interpreters on gateways; adapters per device family.
- Dependencies/assumptions: Command vocabulary within interpreter context; safety interlocks externally enforced.
- Web and mobile — local creative features and mini-games
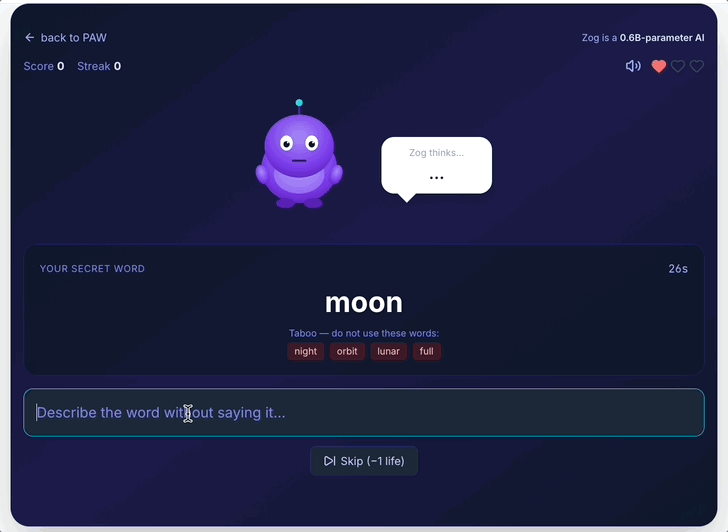
- What: Interactive generation tasks (e.g., word-guessing games) served by a 0.6B interpreter; optional in-browser GPT-2 path via WebAssembly for fully client-side experiences.
- Sector: Consumer Software/Gaming.
- Tools/workflows: Bundle adapters with apps; precompile per-language versions.
- Dependencies/assumptions: Device storage for base + adapters; acceptable quality with small interpreters.
- Multimodal document and diagram tasks with a VL compiler
- What: Compile image-conditioned fuzzy functions (e.g., receipts/diagrams extraction, TextVQA) by swapping in a 4B VL compiler while keeping the same 0.6B interpreter.
- Sector: Enterprise Docs/Engineering/Support.
- Tools/workflows: Cloud compile (VL); local execution; structured outputs for downstream automation.
- Dependencies/assumptions: VL compiler availability; long-form outputs may be context-limited (observed Im2LaTeX limitations).
- Research and teaching — FuzzyBench-10M use
- What: Benchmark hypernetworks/PEFT generation, robustness to noisy specs, cross-interpreter studies.
- Sector: Academia/Industrial Research.
- Tools/workflows: Reproducible splits; verified test sets; noise variants.
- Dependencies/assumptions: Dataset licensing; awareness that data are synthetic (domain gaps may exist).
Long-Term Applications
These concepts are feasible but require additional research, scaling, standardization, or validation beyond current results.
- PAW “app store” and artifact ecosystem
- What: Marketplaces/registries for signed, versioned PAW adapters (LoRA/prefix) with metadata, SBOM, and provenance.
- Sectors: Software, Open Source, Enterprise IT.
- Dependencies/assumptions: Standardized program format/ABI; supply-chain security; license compliance.
- OS/runtime-level integration
- What: OS services exposing a “neural function runtime” so apps call compiled functions like shared libraries.
- Sector: Platform/OS.
- Dependencies/assumptions: Stable interpreter ABI; sandboxing of adapter injection; GPU/accelerator support.
- Federated/on-device compilers
- What: Run the 4B compiler locally or via federated learning for sensitive specs/data.
- Sectors: Healthcare, Finance, Government.
- Dependencies/assumptions: Efficient compiler variants; privacy-preserving training; device resource constraints.
- Safety, verification, and certification pipelines
- What: Policy frameworks to audit/approve adapters (tests, constraints, red-team reports) before deployment.
- Sectors: Regulated Industries, Government, Critical Infrastructure.
- Dependencies/assumptions: Standard verification suites; formal or empirical guarantees; governance processes.
- Adapter composition and orchestration
- What: Compose multiple PAW programs (routing, weighted mixtures, layer-wise merges) to build complex workflows.
- Sectors: Agents, Enterprise Automation.
- Dependencies/assumptions: Theory and tooling for safe/robust LoRA composition; conflict detection.
- Cross-modal unification (speech, video, sensors)
- What: Swap in modality-specific compilers (ASR, video, time series) while sharing a text interpreter or a multimodal interpreter.
- Sectors: Call Centers, Media, IoT.
- Dependencies/assumptions: Data and training for new compilers; interpreter extensions; context/latency constraints.
- Domain-specific interpreters
- What: Smaller or specialized interpreters (e.g., code, legal, medical text) for higher accuracy/efficiency.
- Sectors: LegalTech, MedTech, FinTech.
- Dependencies/assumptions: Curated domain data; rigorous evaluation; licensing/IP for bases.
- Certified on-device assistants
- What: Personal assistants built from a library of PAW functions for private, offline operation.
- Sectors: Consumer, Enterprise.
- Dependencies/assumptions: Comprehensive function coverage; continuous update workflows; user consent and data controls.
- Energy-aware edge deployments
- What: Use PAW to reduce inference energy (small models, offline) across fleets (retail kiosks, vehicles, smart meters).
- Sectors: Energy, Automotive, Retail.
- Dependencies/assumptions: Hardware heterogeneity; fleet management of adapters; robust quantization strategies.
- Enterprise MLOps for PAW
- What: CI/CD for compiled programs (spec linting, unit tests, regression suites, canary releases, rollback).
- Sectors: Software/IT.
- Dependencies/assumptions: Telemetry and evaluation at function granularity; policy hooks for approval gates.
- Government and policy frameworks
- What: Guidance that favors local, reproducible inference for data sovereignty; procurement standards for PAW artifacts.
- Sectors: Public Sector/Policy.
- Dependencies/assumptions: Interoperability standards; compliance mappings (e.g., GDPR, HIPAA, PCI).
- Formal methods and guardrails
- What: Formal specifications for certain fuzzy functions and conformance tests; runtime monitors for out-of-spec behavior.
- Sectors: Safety-Critical Systems.
- Dependencies/assumptions: Hybrid spec languages (text + constraints); model-checking research.
- Enhanced robustness and long-form handling
- What: Improved interpreters or pseudo-program compaction for long-form structured outputs (e.g., Im2LaTeX-like tasks).
- Sectors: Scientific Publishing, Engineering.
- Dependencies/assumptions: Longer context windows; better pseudo-program summarization; task-specific adapters.
- Secure distribution and anti-malware scanning for adapters
- What: Signing, scanning, and sandboxing to prevent malicious or exfiltrating adapters.
- Sectors: Security/Platform.
- Dependencies/assumptions: Standard signing infrastructure; adapter behavior analysis tools.
Notes on Feasibility and Dependencies (cross-cutting)
- Technical
- Interpreter availability: Results are demonstrated with Qwen3 0.6B; quantized GGUF bases (≈430–507 MB) plus ≈23 MB adapters enable laptop-class deployment.
- Compiler requirements: A 4B text compiler (or 4B VL compiler for images) is currently needed at compile time; this may run in the cloud or on a capable workstation.
- Robustness: Pseudo-program denoising improves tolerance to spec noise (small drops even under heavy noise); long-form outputs may stress context budgets.
- Performance bounds: FuzzyBench ceiling ≈96% (data generator); PAW 0.6B achieves ≈74% exact match, surpassing 32B prompting on test distribution.
- Organizational/Legal
- Licensing: Ensure rights to distribute bases, adapters, and datasets (e.g., Qwen, synthetic data provenance).
- Privacy/compliance: Local execution helps with data residency; still require governance around specs, examples, and artifacts.
- Security: Control adapter provenance; sign and verify artifacts; restrict injection to vetted modules.
- Economic
- Cost model: High one-time compile cost per function (LLM invocation/training amortized) vs. very low per-call costs thereafter.
- Storage trade-offs: Many small adapters vs. one large general model; registries mitigate management overhead.
These applications collectively illustrate PAW’s central value proposition: compile once using a large model, then execute fast, offline, and reproducibly with a small, shared interpreter across devices and workflows.
Glossary
- Activation steering: A technique that modifies internal activations to steer a model’s behavior without changing its weights. Example: "extends the idea to activation steering"
- Adapter: A small, trainable module inserted into a frozen model to adapt it to new tasks with few parameters. Example: "emits parameter-efficient adapters for a frozen, lightweight interpreter."
- AdaLoRA: A LoRA variant that dynamically allocates low-rank capacity across layers for better parameter efficiency. Example: "AdaLoRA dynamically allocates rank budgets across layers"
- Autoregressive generation: Producing outputs token by token, each conditioned on previously generated tokens. Example: "and (iii) generate the output autoregressively."
- Attention KV cache: Stored key/value tensors for attention used to speed or condition inference, often extended by prefix-tuning. Example: "prepended to the interpreter's attention KV cache"
- Attention q/k/v/o projections: The query, key, value, and output linear projections inside transformer attention blocks. Example: "attention and MLP "
- Exact match accuracy: An evaluation metric that requires the predicted output to match the reference output exactly. Example: "FuzzyBench uses exact match accuracy on the verified test set."
- Frozen interpreter: A fixed (non-trainable) neural model that executes compiled programs or adapters. Example: "The interpreter is also frozen."
- GGUF: A quantized weight file format used by lightweight LLM runtimes such as llama.cpp. Example: "GGUF formats compatible with llama.cpp"
- Hypernetwork: A network that generates the weights of another model or adapter conditioned on input. Example: "emitted by a hypernetwork"
- In-context learning: Adapting a model’s behavior at inference time using examples or prompts instead of weight updates. Example: "PEFT can outperform in-context learning at lower deployment cost"
- Interpreter (neural): The runtime neural model that, once configured by a compiled program, executes the function on inputs. Example: "a small fixed neural Interpreter"
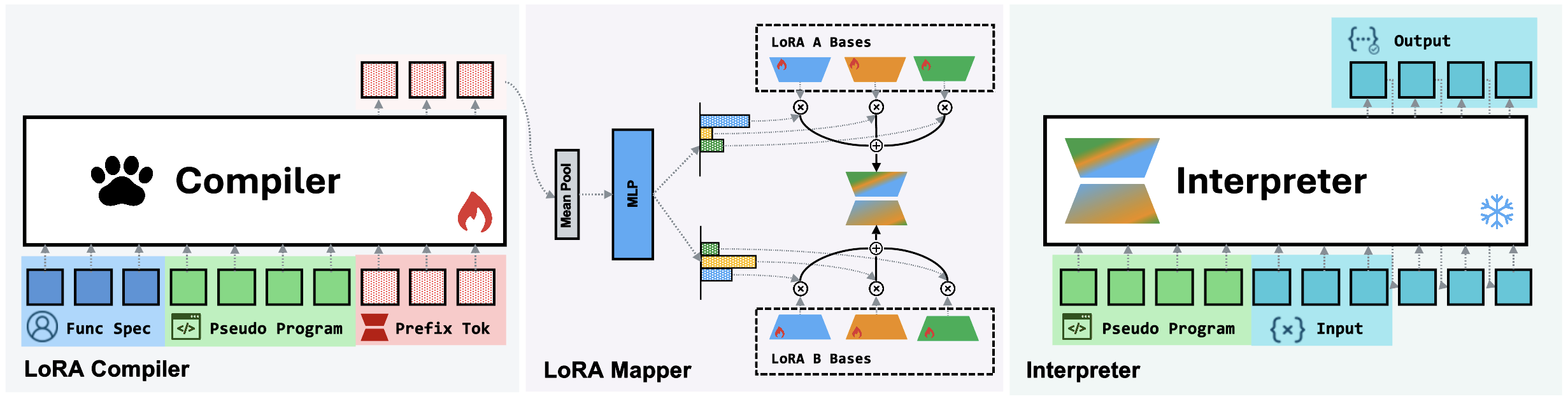
- Learned prefix tokens: Trainable tokens prepended to inputs to condition a model, often used in prefix/prompt tuning. Example: "a fixed sequence of learned ``prefix'' tokens."
- llama.cpp: A lightweight C/C++ inference runtime for running quantized LLMs locally. Example: "compatible with llama.cpp"
- LoRA (Low-Rank Adaptation): A PEFT method that injects low-rank updates into linear layers to adapt a frozen model. Example: "and a LoRA (\Cref{sec:arch_lora}), with the latter being our current best."
- LoRA mapper: The module that maps compiler hidden states into task-specific LoRA weights for the interpreter. Example: "The LoRA mapper mean-pools , passes it through an MLP, and projects into mixing coefficients"
- Mean-pooling: Aggregating vectors by averaging across positions (and/or layers) to get a single summary vector. Example: "These hidden states are mean-pooled over both the depth-aligned layers and the prefix positions"
- Mean-token log-likelihood: The average log probability assigned by a model to each target token, used as a loss/objective. Example: "The loss is the negative mean-token log-likelihood of the target "
- Mixing coefficients: Scalars used to combine shared basis matrices to form per-task LoRA weights. Example: "projected into mixing coefficients "
- MLP trunk: A feed-forward network block used here to transform pooled hidden states before projection. Example: "passed through a shallow MLP trunk "
- MLP gate/up/down: The three linear projections within transformer MLP blocks (gate, up, and down projections). Example: "attention and MLP "
- Parameter-Efficient Fine-Tuning (PEFT): Techniques that adapt large models using small parameter additions without full fine-tuning. Example: "parameter-efficient module (PEFT)"
- Prefix-tuning: A PEFT method that prepends learned key–value pairs to a model’s attention to steer behavior. Example: "standard prefix-tuning~\citep{li-liang-2021-prefix}"
- Program-as-Weights (PAW): The paradigm of compiling a fuzzy function into a compact neural artifact executed by a fixed interpreter. Example: "We call this paradigm Program-as-Weights (PAW)."
- Pseudo-program: A discrete, self-contained textual restatement of the task specification used to guide the interpreter. Example: "a self-contained ``pseudo-program''"
- QLoRA: A PEFT approach that combines quantization with LoRA for memory-efficient fine-tuning. Example: "QLoRA combines quantization with LoRA for memory-efficient fine-tuning."
- Quantization: Reducing numerical precision of model weights/activations to shrink size and speed up inference. Example: "We quantize both the shared interpreter base and each per-program LoRA adapter to GGUF formats"
- Quantization codes (e.g., Q4_0, Q5_K_M, Q6_K, IQ4_XS): Named quantization configurations indicating bit-widths and schemes for weights. Example: " base + LoRA"
- Rank (LoRA rank): The dimensionality of the low-rank factors used in LoRA updates, controlling adapter capacity. Example: "We use rank "
- Shared learnable bases: A set of reusable basis matrices that are linearly combined via mixing coefficients to build LoRA weights. Example: "the mapper maintains shared learnable bases"
- Vision-LLM (VLM): A model that processes both images and text to solve multimodal tasks. Example: "replacing only the compiler with a vision-LLM"
- Hot-swappable (LoRA): The ability to attach/detach task-specific LoRA weights at runtime without retraining the base model. Example: "Because the interpreter is frozen and the LoRA hot-swappable"
Collections
Sign up for free to add this paper to one or more collections.

